생문과가 통계와 친해지려는 시도 (2025-05-09)

911GT3RS
2025.05.09조회수 363회
911GT3RS
구독자 1,979명구독중 107명
Hybrid Theory
나는 직관을 중요시한다. 복잡한 사고의 과정을 거치지 않고 보는 순간 바로 어떠한 '느낌'이 오는 경지야말로 그것을 제대로 이해하고 있다는 방증이라고 생각하기 때문이다. 운전을 하면서 차량 조작에 대해 생각을 굳이 하지않고 상황에 따라 발이 엑셀과 브레이크를 통해 저절로 반응하게 되는 것, 그것이 직관의 경지에 도달한 것이라는 것을 항상 하게된다.
최근 변동성이나 SKEW, 회귀분석과 관련된 논문들을 자꾸 뒤지다 보니까, 평소에 그냥 외계문자로 보이거나 이해하지 못한 채 수식으로만 받아들이던 부분들을 (아주) 조금은 '직관적'으로 이해하게 된 부분들이 몇가지 있다. 처음에는 와닿지 않지만, 일단 모르겠어도 계속 보다보니, 반복적인 부분들이 보이고 유추를 하게 되고, 찾아보다 보니 조금은(?) 이해할 수 있을 것 같은(착각 일수도있지만) 부분들도 생겨서 정리해본다. (역시 내가 제일 잘하는 반복학습이 답인가?)
아무튼, 깨달은 것들을 정리해보면,
키와 몸무게처럼 서로 다른 단위의 비교를 위해서는 정규화(normalization)를 해주어야 한다. 대표적으로 Z-Score가 있는데,
의미를 좀 가만히 생각해보자. 분자를 보면 결국 "평균으로부터 얼마나 떨어져 있냐?"를 의미한다. 그럼 상식적으로 그걸 표준편차로 나눈다는게 무슨 의미인가? 편차 한 단위가 이만큼인데, 현재의 평균으로부터의 떨어짐의 정도가 그 표준편차 한 단위만큼의 얼마나(직관적으로는 몇%)해당 되냐를 의미한다.
가령, 현재 A라는 사람의 키가 180cm이고, 평균이 160cm이다. 그럼 분자는 180-160=20cm이고, 이는 A라는 사람의 키가 현재값이 평균으로부터 20cm만큼 떨어져있다는 의미이다. 근데, 표준편차가 40cm라고 하면, 사람들의 키가 평균으로부터 떨어져 있는 편차의 표준이 40cm이라는 뜻인데, 이 A씨는 20cm만큼만 떨어져 있다는 뜻이다. 그럼 A라는 사람의 키의 Z-Score는 0.5인 것이다. 왜? 표준편차가 40인데 그것의 절반인 20cm니까 20cm/40cm = 표준편차의 0.5배수인 것이다.
그럼 여기서 두번째 의문이 생긴다.
표준편차란 무엇인가? 아니, 애초에 표준은 둘째치고 편차란 무엇인가?
먼저, 편차를 사전에서 찾아보자. 단어 자체의 어감에서 뭔가로부터 "떨어져 있다"라는 느낌이 팍팍 온다.

탄착군에서 탄환이 벗어난 거리라... 갑자기 훈련소에서 영점사격을 못해서 눈바닥에 배를 깔고 PRI를 오지게 했던 PTSD가 몰려온다. 아무튼 직관적인 생각이 어느 정도는 맞는 것 같다. 핵심 단어는 요컨대 "벗어난 정도가 얼마냐?"라는 것 같다.
수학적으로 표현하면 편차(deviation)는 관측값에서 평균값을 뺀 것이다. 위 A씨의 예시에서 관측값은 A씨의 키인 180cm, 평균값은 사람들의 평균값인 160cm이므로, 편차는 20cm가 된다.
오케이, 그럼 여기까지는 이해했다.
그럼 앞에 표준이 붙은 표준편차는 무엇인가? 설명을 찾아보니, 아래와 같은 청천벽력같은 단어가 또 나온다.
표준편차(standard deviation)는 분산을 제곱근한 것이다.
슬슬 빡이 친다.
아니 그럼 또 분산은 뭔가? 또 찾아본다.
분산(variance)은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다.
진심 죽여버리고 싶다. 일단 애초에 관측값에서 평균을 뺀게 편차인데, 그 편차를 왜 제곱을하고 X랄이란 말인가?
분명 이유가 있을 터이다. 열받아서 ChatGPT를 갈궈본다.
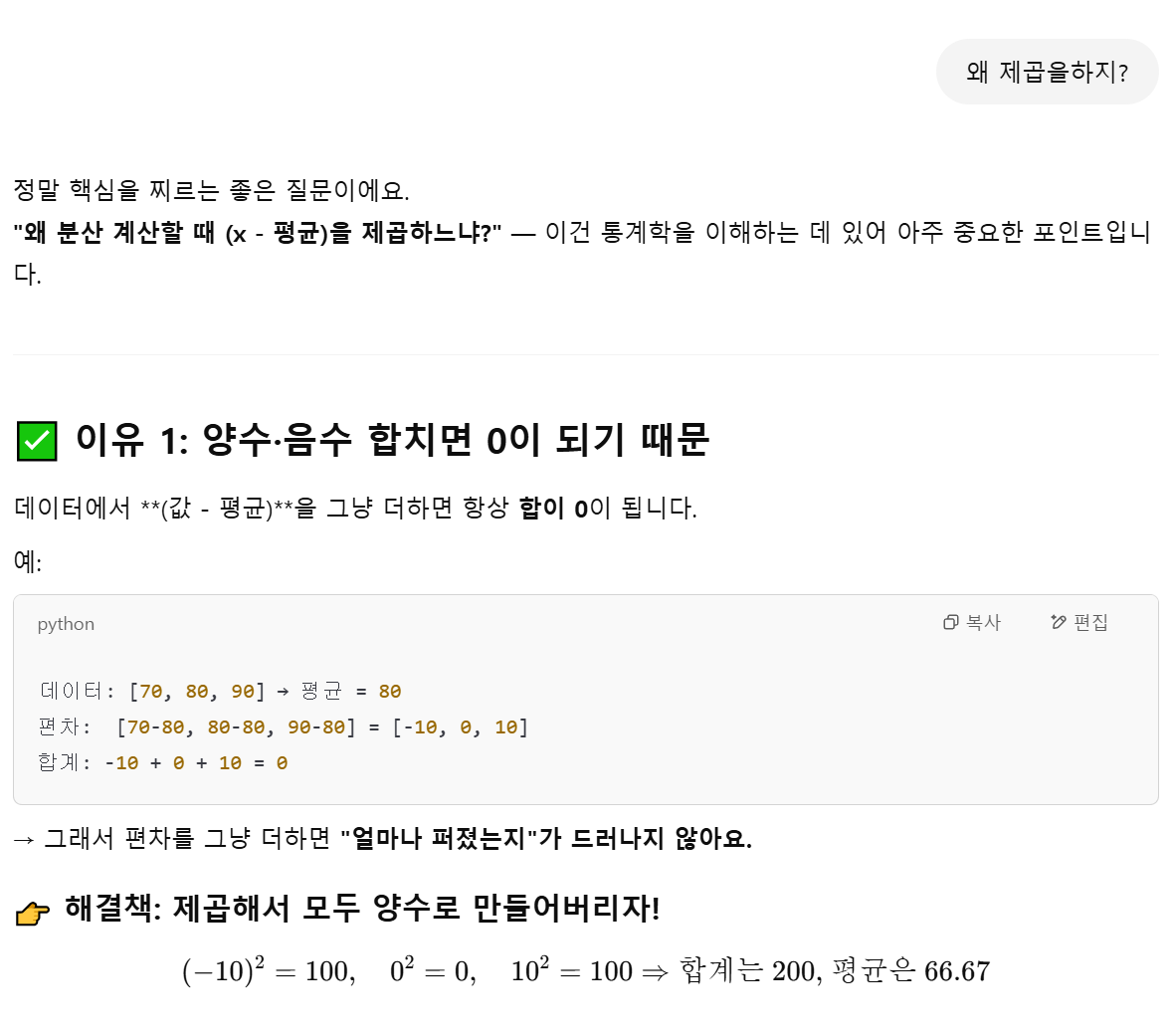
일단 핵심을 찌르는 좋은 질문이라는 아부쟁이 ChatGPT...
일단 첫번째 이유는 납득이 간다. 평균이라는 거 자체가 직관적으로 엔빵때린 가운뎃값이기 때문에, 편차들을 그냥 더해버리면 서로 양쪽 +-부호를 가진 편차들이 서로 상쇄되어 0이 되어버리기 때문에, 얼마나 분산되어 있는지 알 수가 없는 것이다.
예를 들어, 2, 4, 6, 8, 10이 있다고 하면, 평균은 당연히 6이다. ...
![[파이썬] 시장 리스크 대시보드 제작중](https://post-image.valley.town/m1s-WRKTPNh9C1YnIVzWT.png)
![[파이썬] 실습 - FRED 유동성 데이터 불러와서 시각화해보기](https://post-image.valley.town/ttGSBAuz9jq8WFaoxntH8.png)
![[파이썬] 3. 판다스 기초 - 시리즈와 데이터프레임](https://post-image.valley.town/rHonDjiw8FlFXv8t0xB1-.png)
![[파이썬] 2. 제어문과 함수, 패키지](https://post-image.valley.town/Gn101iI4BDWNzapmg3-Ru.png)

좋은 글 감사드립니다. 중간에 보여주신 표준편차에서 제곱근을 씌워주는 이유에 대해서 보여주신 수식이 성립하지않는 것이 당연히 일반적으로 참입니다. 다만 수치적인 편차의 정도를 보여주기 위해 일일이 모든 데이터에 절대값을 씌워주는 연산은 상당히 큰 부담이 발생하기에 제곱하고 더하고 다시 제곱근을 씌워준다 정도로 설명할 수 있을 것 같습니다. 또한 생각해볼 것이 (0 0 0 1 1)과 (0 0 0 0 2)의 표준편차를 계산해보면 후자가 더 크다는 것을 볼 수 있습니다. 직관적으로도 알 수 있듯이 모든 데이터의 편차의 절대값의 합이 같더라도 튀는 값이 더 많은 경우가 일반적으로 표준편차가 더 크게 나타납니다. 이렇게 보면 제곱하고 더하고 다시 제곱근을 취하는 이유가 나름 합리적으로 보이지 않을까요? :)
와... 예시가 너무 직관적이어서 단번에 이해가 되네요...제곱을 통해 "극단치를 과장"한다는 건 그런 의미였군요! 매번 글마다 도움되는 글 달아주셔서 항상 감사하게 보고 있습니다. 저도 항상 응원합니다!

이건... 통계가 두려운 고딩에게도 통할 법한 쉬운 요약인데요? 훌륭합니다. ^^
저 생각을 고딩때 미리 하고 왔어야 했는데, 그땐 외우기만 하고 15년도 더 지난 지금에서야 머리 싸매고 되새김질하고 있네요 ㅋㅋㅋ 하.. 너무 늦게와버렸다...

지나가던 지적질 장인입니다, 오랜만이네요 911님 🤓 본문 중에, " 리스크는 표준편차(σ)로 나타내는 경향이 있는 것 같다. 왜인지는 잘 모르기도 하고, 아직 다룰 주제가 아닌 것 같아서 패스. " 이 부분이랑 " 관측 " 이 두 가지가 가장 중요하지 않나 생각이 되네요. 저는 911님의 공부가, 내가 사거나 팔기 위한 가격의 분포를 결정하기 위하여, 어디서 관측할 것인지를 깊이 탐구하기 위해 평균을 공부하시는 것으로 이해했습니다. 그런데 저는 수식 도출에 대한 답을 먼저 드리기 보다는 가장 기본이 되는 것, "왜" 관측해야 하는 지에 대한 기준이 먼저 있어야 평균을 공부하는 것이 더 의미가 있어 진다고 생각합니다. 이는, 리스크를 수용할 수 있는 능력 자체가 관측 주체 (개인, 기관, etc) 가 모두 다르기 때문에 평균으로 표시를 해 놓은 것이지 (1) 개인의 입장에서, (2) 기관의 입장에서, (3) etc 의 입장에서 모두 다른 "관측"을 할 것이기 때문입니다. 이를 쉽게 이해하기/전달하기 위해서 수식으로 표준편차(σ) 를 나타낸 것이지, 직접 거래한 데이터를 가지고 있다면 (이 역시도 지속적인 수익을 낸 데이터 (알파/베타), 지속적인 손실을 낸 데이터에 따라 달라질 겁니다) 내가 설정한 가격 상한, 하한, 중단 등 모든 반경에는 동일한 편차를 적용할 수 없기 때문입니다. 왜냐면 "관측" 위치가 다르기 때문에요. 여기에 동일한 표준편차를 적용하는 것이 가능할 때는 오로지 과거 데이터만 가지고 P-Hacking 을 할 때만 유효하겠죠. 미래 가격 분포는 절대적으로 「알 수 없는」 영역입니다. 월가아재님이 말씀하신 카지노를 파산시키는 플레이어*의 역할이 바로 여기에 적용될 수 있을 것 같습니다. 카지노에 들어간 사람들이 카지노를 파산시키지 못 했기 때문에 카지노를 파산시킬 수 있는 플레이어의 등장은 위 계산식에 (기꺼이 도출해놨더만) 적용될 수 없는 문제가 생기게 됩니다. 그리고 이것은 평균을 통해 시장을 관찰하는 개개인들에게 모두 해당됩니다. 내 가격 정보를 알고 있는 거래 상대방이 내 가격을 그대로 받아준다면 「알파」 는 절대 없을 겁니다. * https://www.youtube.com/watch?v=uA8em0NqKaI 그럼 마지막으로 질문 하나만 던지고 가겠습니다. 「직관」 의 관측자는 어디에 있는가? 이에 대한 대답을 찾아가시는 모든 과정이, 답이 되기를 기원합니다. 좋은 밤 보내세요 😘
우문현답이라는 말이 있는데, 이건 바보같은 질문을 더 현명한 생각해볼 거리로 돌려주시는 우문현문의 경지인 것 같습니다. 사실 달아주시는 댓글마다 항상 그랬지만, 지금 답을 Fine님께 다시 되묻는 것 보다 말씀대로 스스로 답을 찾아가는 과정자체에서 더 큰 효용이 있을 것 같아서 스스로 오래도록 한번 생각해보도록 하겠습니다. 매번 철학이 담긴 지적질(?)에 감사드립니다. 좋은 밤 되세요!
키가 160cm, 170cm, 180cm 인 세 사람이 있을 때 // 편차는 각각 -10cm, 0cm, 10cm // 이 집합의 분산은 [(-10cm)^2+(0cm)^2+(10cm)^2]/3 = ~~ cm^2 -> 단위가 cm^2이 됩니다. // 따라서 제곱근을 취해주면, 완벽한 척도는 아니라도 분포의 흩어진 정도를 관심 대상의 단위로 직관적으로 나타낼 수 있습니다
와... 야밤에 입을 벌리고 감탄하고 있습니다. 어떻게 이런 설명이... 덕분에 한번에 이해가 되었습니다. 오늘도 귀인을 만났네요. 정말 감사드립니다 ㅜㅜ

제곱 세제곱 네제곱 ! 재밌네요
저도 보면서 참 누가 발견했는지 신기하다는 생각을 많이 하게되었습니다 ㅋㅋㅋ 수학자들은 다 변태가 분명해요...
깨달음을 얻은 그.....ㄷㄷㄷㄷ
ㅋㅋㅋㅋ말그대로 이제 간신히 수학책 펼친 수준입니다... 트레이딩 쪽으로 갈 수록 점점 수식들의 향연이네요 흙흙

제 생각에 구일일님 의문점의 시작은 아마도 왜 굳이 절댓값을 쓰지 않고 제곱을 써서 여럿 피곤하게 하냐?로 보입니다. 제곱을 하지 않고 절댓값을 썼을 때 구해지는 편차를 mean absolute deviation 또는 median absolute deviation, 줄여서 MAD 라고 정의하는데요. MAD는 포스팅에서 탐구하신 표준편차(STD)와 비교했을 때 정규분포를 가정할 경우 MAD가 STD의 0.8배 정도 나옵니다. 따라서 첫번째 의문점에 대한 구일일님의 직관이 맞습니다. MAD와 STD는 다릅니다. 그런데 왜 굳이 제곱을 하게 될까를 비전공자 입장에서 조심스럽게 작성해보면 다음과 같은데요. 연속적인 공간에서 정규화 조건을 만족하는 확률밀도 '함수'의 매끄러운 곡선(smooth curve)이 존재해야 미/적분이 가능하고 엄밀한 해석적(analytical) 해가 깔끔하게 나옵니다. 그리고 일상적인 자연 현상들에 대해 '비교적' 잘 설명해주는 좌-우 대칭이 예쁘게 나오는 정규분포(gaussian)도 여기서 시작됩니다. 통계학 뿐만 아니라 여럿 학문의 베이스가 여기서 시작되며 옵션 공부하시면서 배웠던 블랙숄즈 방정식도 로그-정규분포(log-normal distribution)를 가정해서 이론이 완성되었습니다. 다만 이제는 해석적(analytical) 해를 구할 수 없는 문제에 대해 수치적(numerical) 해를 구할 수 있는 충분한 컴퓨팅 파워가 있는데 아직까지도 STD를 억지로 쓰는게 맞냐? 입니다. 즉, STD의 가치는 충분히 중요하고 학문적으로도 중요한 주제지만 정규분포로 설명하면 안되는 사회적 현상까지도 STD를 끌고 오는게 과연 올바른 것이냐는 것인데요. 몸무게/키와 같은 수치들은 정규분포를 예쁘게 따릅니다만, 이를 따르지 않는 분포가 사회에서 자주 보입니다. (Power law, 파레토 법칙 등) 주식 시장은 어쩔 땐 정규분포를 따르는 듯 하면서도 어쩔 땐 따르지 않습니다. 옵션에 관심이 많으실테니 스트래들로 보면, 스트래들 매수로 수익 내기가 쉽지 않습니다. 스트래들 매도자가 계산한 이론가가 비교적 정확하기 때문인데요. 문제는 정규분포로 설명이 안되는 구간에서 STD를 맹신할 때 골로 가는 경우가 생깁니다. 블랙먼데이, LTCM, XIV(볼마게돈), Covid-19 등... 다만, 모든 모델링의 시작점이 여기다 보니 여기서 조금 더 fat-tail에 강건한 구조를 갖기 위해 마켓 메이커들과 vol trader이 밤낮으로 열일하고 있는 것 아닐까 생각됩니다. 최근들어 댓글이 줄 넘기기가 안되는 상태라 읽기가 좀 불편하실 것 같아서 위 내용에 대한 나심 탈레브의 글을 링크로 올려드립니다. https://web.archive.org/web/20140116031136/http://www.edge.org/response-detail/25401
좋은 글 감사드립니다. :)
원문이 좋으니 댓글에도 배울 것이 많이 있습니다. 덕분에 여러가지 배웁니다. 감사합니다.

크…절대 유익한 글에 절대 유익한 댓글의 조합. 감사합니다!
가우시안 분포를 단어만 들어만 봤는데, 정규분포를 의미하는 것이었군요! 가우스가 발견해서 그렇게 붙인것인가... MAD와 STD에 대해서 저는 그냥 단순히 계산편의 차원에서의 고민이었느데, 그런 깊은 추가적인 고민이 필요한 영역일줄은 몰랐습니다. 신기하네요. 오늘도 많이 배워갑니다. 링크 주신 부분은 내일 한번 정독해보겠습니다!!
역시 갓시메트릭 선생님이시다.. 탈렙 교수님 유튭도 있으니 함께 보시면 더 좋지 않을까 하며.. 숟가락을.. (영상은 재생목록이고 갓시메트릭 선생님 말씀이랑 첫 영상 MINI-LESSON 1: Breaking down intuitively the concept of standard deviation 같이 보시면 더 좋을 것 같습니다 ㅎㅎ) https://www.youtube.com/playlist?list=PLMV8UXQuOWKPAIjvnyMN2317LHF3ydvnG

중간중간 독백이ㅋㅋㅋㅋㅋ 수학문제 안풀릴때 딱 그심정 같아서 웃겼습니다. 재미나게 읽었습니다!
ㅋㅋㅋㅋ역시 그 기분을 알아주시는군요... 수포자는 웁니다 ㅜㅜ

저도 이제 조금씩 통계 공부하려고 했는데 너무 좋은 글과 댓글들 잘 읽었습니다 !! ㅎㅎ
댓글들이 정말 너무 주옥같네요... 질문한 보람이 있었습니다 흑흑 감사합니다.

아...이해하고 싶다 ㅠㅠ 직관을 즐겨 쓰기에 이거다 싶은데
저도 하루에도 몇번을 GPT를 고문하는지 모르겠습니다... 거의 과외선생님 수준으로 갈구면서 꾸역꾸역 이해해보려 하고있습니다...