LLM 토큰 생성 속도 한계 효용 기준의 변화, 돈 벌기 위한 질문들

반도의반도체공돌이
2026.03.19조회수 230회
반도의반도체공돌이
구독자 139명구독중 51명
여러분의 좋아요, 댓글, 구독은 글을 쓸 동인이 됩니다.
사람은 1초에 3~5단어 정도 읽는데, 이를 토큰으로 변환하면 대략 3~7토큰 정도 된다.
그렇기에 초당 수십 토큰 생성은 생성된 토큰이 읽을 가치가 있다는 전제 하에 꽤나 충분한 속도였다.
OpenAI 는 gpt4o, 그리고 그 이후 모델들을 통해 이 요구 속도를 넉넉히 만족시켰다.
생성 속도를 해결 한 뒤 한동안 주요한 이슈는 더 큰 컨텍스트 처리였다.
사용되는 컨텍스트는 점점 길어지는데, 이를 모두 HBM 에 넣기는 너무 비싸고, 물리적인 메모리 크기의 한계도 있었다. 그래서 엔비디아는 작년 가을 발표한 루빈 CPX 구조를 통해 HBM 아닌 GDDR 을 함께 써서 컨텍스트는 더 싸고 용량을 많이 확보할 수 있는 GDDR 에 쓰려는 계획을 발표했다. 그렇게 해도 한계 효용에 해당하는 초당 수십토큰은 맞출 수 있었으니까.
그런데, 한계 효용 기준이 명확히 바뀌었다. 초당 생성 토큰이 수십을 넘어 수백, 수천, 수만이 될수록 더 좋아지는 구조로.
에이전트 시대에는 토큰의 주된 소비자가 사람이 아닌 AI가 되었기 때문이다.
첫번째 LLM 을 호출해서 얻은 결과를 사람이 읽고 그 다음 액션을 취하는 것이 아니라, AI 가 읽고 두번째, 세번째, 네번째 단계 액션을 취한다. 그 결과 사람 전문가가 12시간 걸리는 일을 사람 개입 없이 하기 시작했고, 이 시간은 점점 더 길어지고 있다. 굉장히 빠르게.
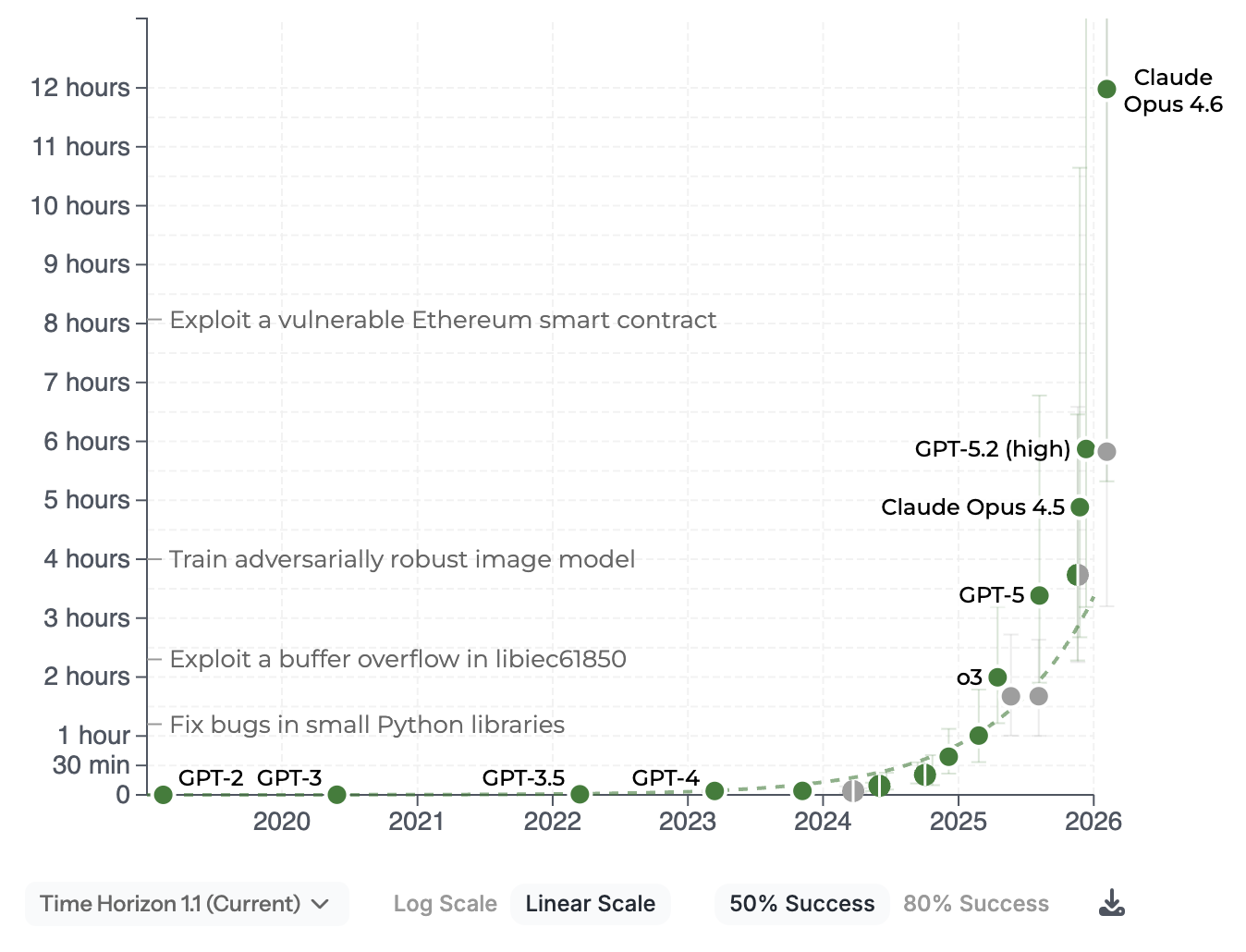
그리고 AI 는 인풋 토큰을 컨텍스트 윈도우 제한 이내에서는 '병렬로' 처리하고, 때로는 이 병렬 처리의 범위가 수만~수십만이 되니 기존 대비 한계 효용의 기준이 수천, 수만배 올라가는 것이다. 그냥 무제한으로 빠를 수록 좋다고 생각해도 될 정도의 차이다.
이 때문에 올해 ...

안될공학 유튜버가 정리한 이번 SRAM 구조도 되게 좋더라구요 ㅎㅎ 정리 잘해주셔서 감사합니다

핵심 논리만 명확하게 짚어주시니 좋습니다. 내용 긁어서 딥리서치 돌리며 공부하는데 재밌네요!