
제이피
구독자 25명구독중 13명
쓰고 싶은거 다 씀
ID는 중복되어서는 안되는 어떤 데이터에 대한 고유 식별자이다. 유저의 프로필, 유저가 작성한 글, 유저가 작성한 댓글은 각각 ID가 존재하며 데이터베이스에 저장할 때의 값은 문자열일 수도 숫자일 수도 심지어는 그냥 바이너리일 수도 있다.
https://www.valley.town/space/@jaypee/articles/6967556e87a887e74ae74c5a 이 링크에서 6967556e87a887e74ae74c5a 부분은 게시글의 ID이고 @jaypee는 유저의 공개용 프로필 ID라고 할수있다. 지금은 접었지만 사이트 만들면서 나만의 ID 방식을 정립한 김에, ID의 종류와 장단점 그리고 더 나은 설계는 어떤게 있는지 정리해보았다.
기초 과정에서는 대부분 auto increment 방식으로 숫자 타입의 id를 만든다. 이 방식은 웹, 게임 등의 내가 코딩한 결과물인 서버 프로그램이 아니라 별도로 설치한 데이터베이스 서버가 ID의 생성을 담당하게 된다. 그래야 순차적으로 중복없이 ID인 숫자값이 증가 할수 있기 때문인데, 이 것의 가장 큰 단점은 데이터의 양과 ID를 유추하기 쉽다. 게시글은 웹 주소로 노출될 수밖에 없고 작성자의 프로필 조회 기능도 있는 방식이라면 숫자값을 다르게 넣어 총 회원수를 충분히 알아 낼수 있다. 또한 ID의 생성주체가 DB이기 때문에 불필요한 ID 생성 처리 부하가 존재하고 ID의 고유성을 DB없이는 보장할수 없는 문제가 있다.
고유한 ID를 DB에게 확인할 필요 없이 프로그램이 자체적으로 만들기 위해 대부분 UUID v4를 사용한다. 초당 10억 개씩 100년간 생성해야 50%의 확률로 충돌 가능성이 있기에 마이크로서비스 환경에서도 수백 수천개의 프로그램이 필요한 고유 ID를 생성 할수 있지만 이 방식도 단점이 있다
숫자기반 ID는 32비트나 64비트 크기를 차지 하지만 UUID는 128비트의 크기를 차지한다. '요즘 핸드폰도 512GB인데 128비트가 대수냐' 라고 할수 있지만 서비스의 규모가 커질수록 스토리지 용량, 트래픽 비용 심지어 서버 메모리 공간을 생각하면 64비트 기반 ID사용시 기본 ID의 크기가 절반이 되기 때문에 전체 컴퓨팅 예산 절약에 상당히 도움이 된다. 물론 이거 걱정할 정도로 서비스 규모가 크다면 대박난거 축하
또 다른 단점은 데이터베이스 입장에서 ID값이 완전 램덤하기 때문에 데이터 읽기와 쓰기 성능이 순차적인 ID 대비 떨어진다. 인덱싱의 핵심 원리는 미리 데이터를 정렬한채로 저장 하는것 이다. 아파트 단지를 예로 들어보자.
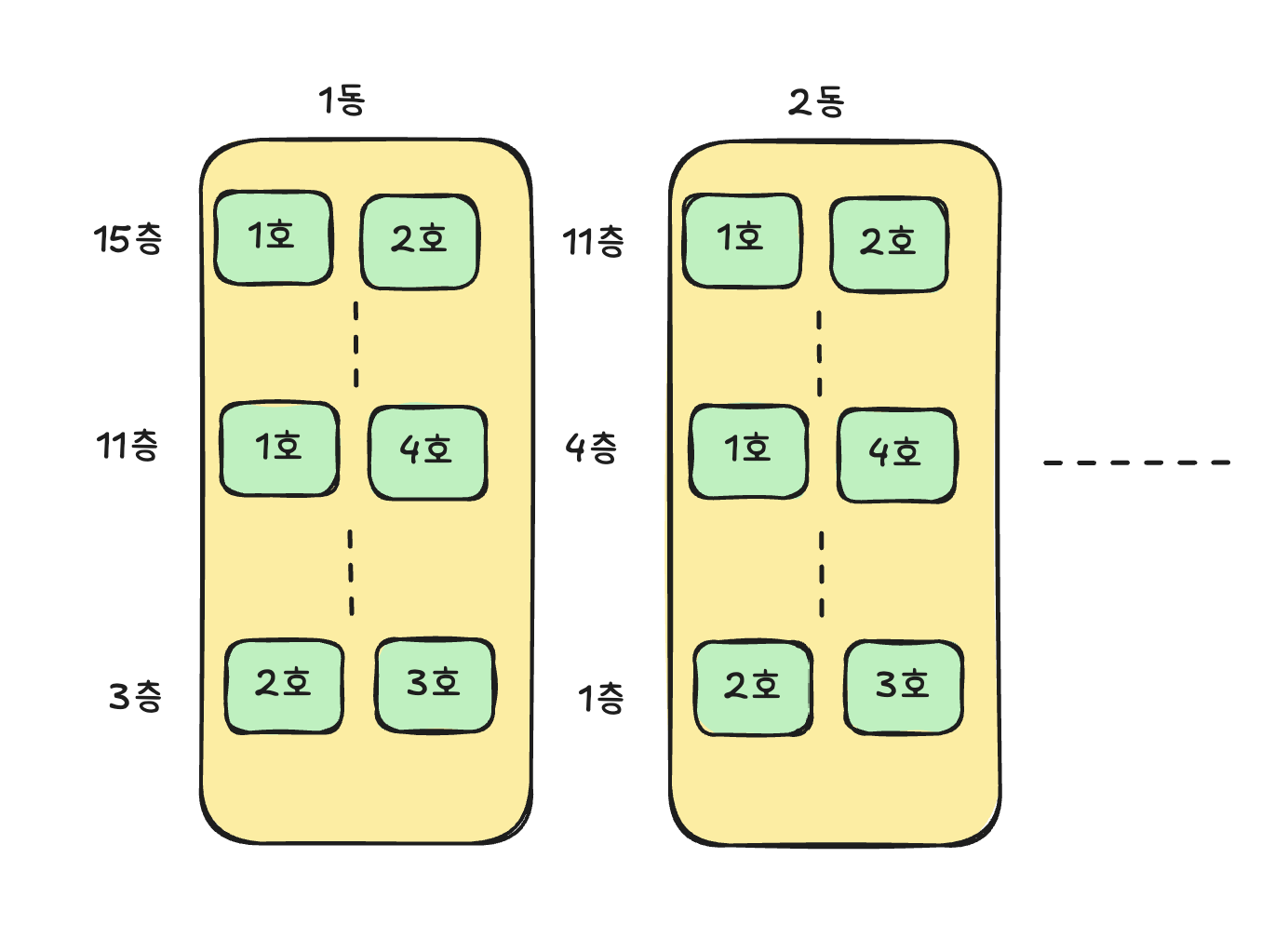
1명의 유저는 호수이고 호수가 모여 하나의 층이되고 여러 층이 모여 하나의 동이 되며 여러개의 동이 모여 하나의 아파트 단지가 된다. 여러 호수가 같은 층 같은 동에 있다는 말은 ID값이 정렬했을때 다른 동보다 근사한 값이라는 말이다. 그런데 100명의 입주자가 생긴경우(100건...

개발 블로그에서 볼 수 있는 글을 보게 되는군요. 재밌게 읽었습니다.

쿠쿠 지나가는 DB 엔지니어입니다 구독하겠습니다~! ㅎㅎ
자체적으로 UUID를 만드신다니 멋지십니다.
uuid v7 써보셨어요? 중복확률도 적고 좋습니다!
https://andyatkinson.com/avoid-uuid-version-4-primary-keys