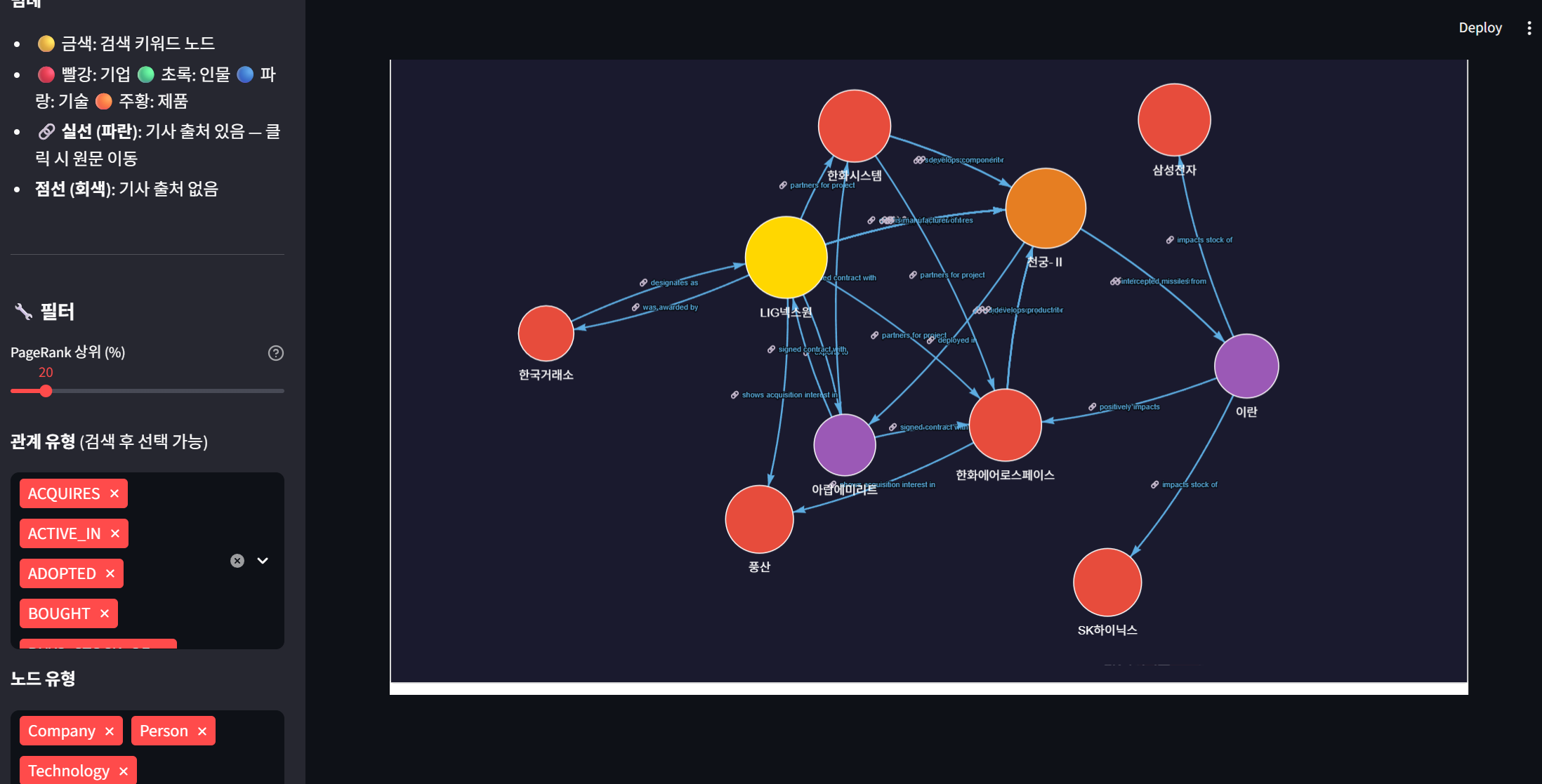
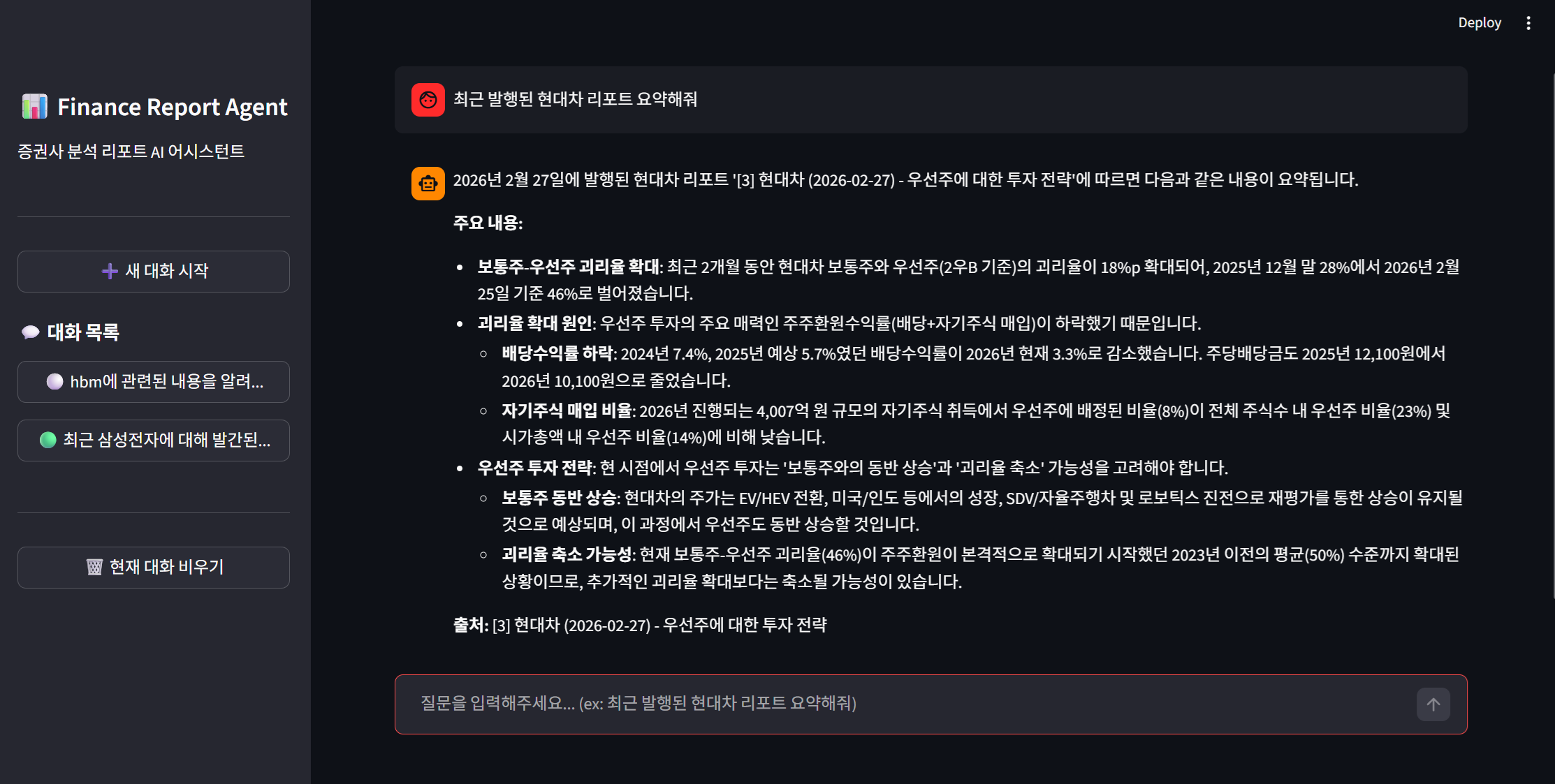
이제 시작하기 전에 생각했던 기능이 어느정도 완성되었습니다.
하면서도 계속 고민이 되는 부분이 소스에 대한 한계였는데요. 소스로 네이버 뉴스 api를 사용했는데, 이게 뉴스의 요약본을 제공하는 형태라 아무래도 한계가 있을 수 밖에 없다고 생각되었습니다. 그 외에도 중복된 뉴스가 너무 많고 어뷰징을 위한 기사들도 많기 때문에, 일부 신문사(개인적으로 많이 들어본 신문사)를 중심으로 필터링하고 제목이 비슷하면 필터링 하는 등의 과정을 거쳤으나 그래도 여전히 많았습니다. DB에 내용을 잘 쌓아가려면 유의미한 기사를 중심으로 수집하는 것이 중요한데, 그게 어렵겠다는 생각이 많이 들었습니다.
그래서 다음은 텔레그램 메세지를 소스로 해서 비슷한 걸 해볼까 생각 중입니다. 저 같은 경우 텔레그램에서 몇몇 채널에 들어가있는 상태이지만 매일 그 메세지를 읽기에는 시간도 없고 ...
회원가입만 해도
이 글을 무료로 읽을 수 있어요.
이미 계정이 있으신가요?로그인하기