쉽게 이해하는 강화학습 (feat. DeepSeek)

적랑
2026.04.18조회수 147회
적랑
구독자 341명구독중 42명
논리 기반 사고
요즘 AI 얘기가 나올 때 강화학습(Reinforcement Learning)이라는 용어가 심심찮게 등장합니다. AlphaGo도, 최근 화제가 된 DeepSeek도, ChatGPT의 훈련 과정에도 강화학습이 쓰였다고 하고, 알고리즘 트레이딩 쪽에서도 강화학습이 적용된다는 이야기가 종종 나옵니다.
이름은 많이 들었는데 막상 "정확히 뭐가 강화되는 학습이야?"라고 물으면 답이 애매한 분들이 있을 것 같아, 개념을 간단히 정리해봅니다.
가장 쉬운 시작은 다른 학습 방식과 비교해보는 것입니다.
머신러닝은 보통 세 가지로 나뉩니다. 지도학습, 비지도학습, 강화학습입니다.
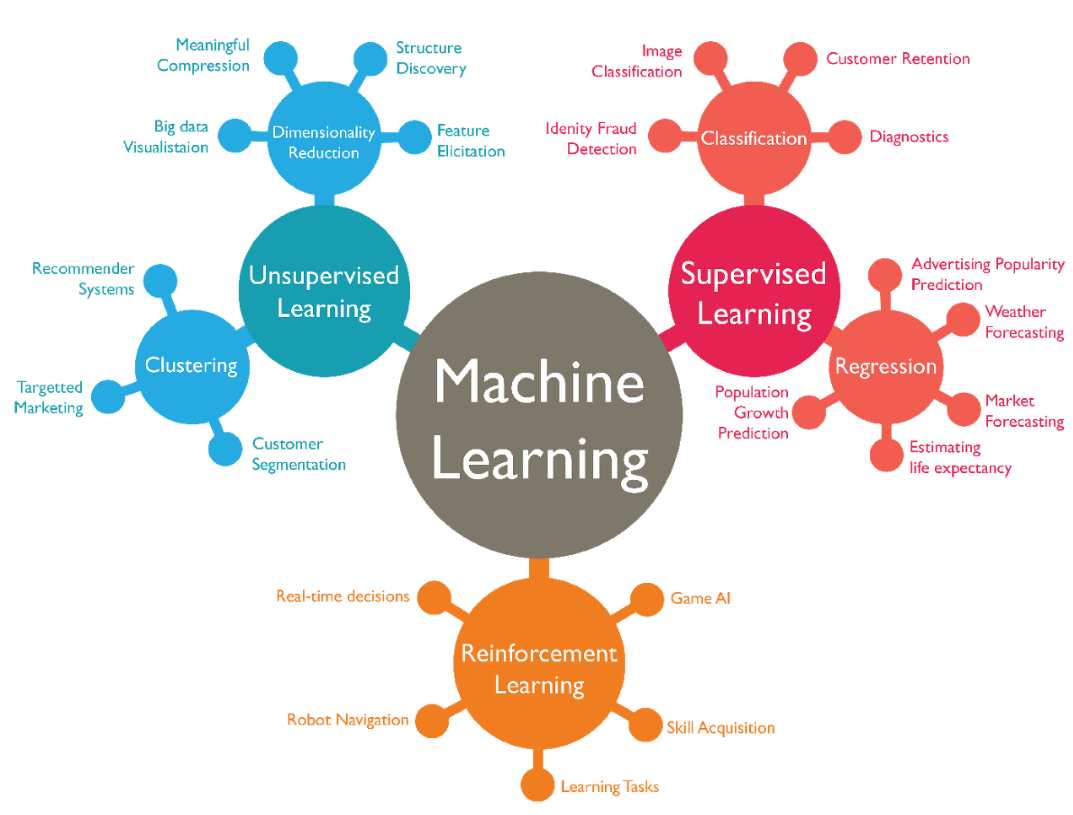
지도학습은 정답지가 있는 문제집 풀이와 비슷합니다. 문제를 풀고 정답과 대조하면서 틀린 부분을 고쳐갑니다. "이 이메일은 스팸이다", "이 사진은 고양이다" 같이 정답이 미리 주어져 있는 상황이죠.
비지도학습은 정답 없이 데이터 속에서 패턴을 찾는 방식입니다. 고객을 성향별로 묶는다든가, 이상 거래를 찾아낸다든가 하는 것들입니다.
그럼 강화학습은 뭘까요?
강화학습에는 정답지가 없습니다. 대신 "결과가 좋았는지 나빴는지만 알려주는" 구조입니다.
예를 들어 봅시다.
자전거를 처음 배울 때를 떠올려보면, 누군가 옆에서 "지금 핸들을 3.7도 왼쪽으로 꺾어" 같은 정답을 알려주진 않습니다. 그냥 타고 넘어지고, 덜 넘어지고, 결국 쓰러지지 않게 되는 과정을 반복합니다.
이때 학습 신호는 하나입니다. "넘어졌다 / 안 넘어졌다."
이게 강화학습의 본질입니다. 행동을 하고, 결과를 받고, 결과가 좋았던 방향으로 행동을 조금씩 조정하는 것. 정답을 알려주는 선생 없이, 잘했는지를 채점하는 심판만 있는 학습입니다.
좀 더 정확하게 구조를 뜯어보면 강화학습에는 네 가지 등장인물이 있습니다.
Agent(에이전트) = 학습하는 주체 (자전거 타는 사람)
Environment(환경) = 상호작용 대상 (도로와 자전거)
Action(행동) = 에이전트의 선택 (핸들 조작, 페달 돌리기)
Reward(보상) = 결과에 대한 피드백 (넘어짐 / 안 넘어짐)
에이전트는 매 순간 환경을 관찰한 뒤 행동을 선택하고, 그 결과로 보상을 받습니다. 그리고 받은 보상을 바탕으로 "다음에 비슷한 상황이 오면 어떻게 행동할까"를 조금씩 업데이트합니다.
여기까지는 직관적인데, 강화학습이 서 있는 중요한 가정이 하나 있습니다.
바로 "미래는 오직...

1타강사 감별사 입니다. 만점입니다.... 짝짝
설명 감사합니다..

이용만 하고 탐험만 하지 않는 에이전트는 마치 포커로 따지면 마치 특정보드 특정핸드의 플랍 체크레이즈가 이득이라는 노드 하나에 갇혀서 턴 딜레이 체크레이즈 라인의 ev를 탐험하지 않는 것과 비슷하군여