
썩은 이빨
구독자 4명구독중 1명
이과돌이
버핏스러운 주식을 찾는 것은 힘들다.
나는 리서치를 썩 즐기지도 않는다. 가능하면 콤푸타가 버핏스러운 좋은 주식을 알아서 찾아주었으면 좋겠다.
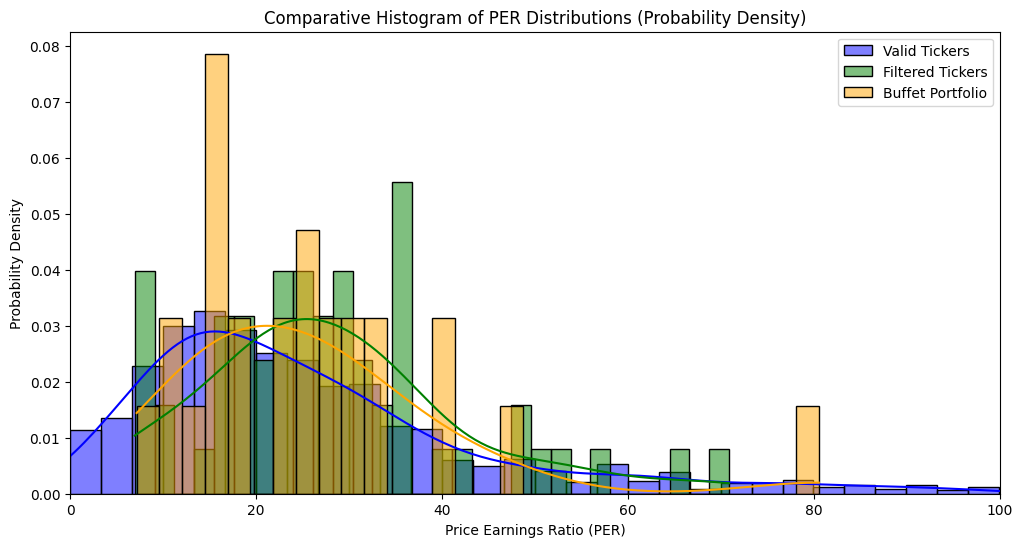
그리하야 처음엔 버핏의 베타 팩터를 반영하는 포트폴리오를 구성해보았으나 과거 가격을 사용하기 때문에 그렇게 구성한 포트폴리오의 성과가 백테스트 상에서도 별로 좋지 않았고 특히 숏을 해야한다는 게 개인 투자자로서 큰 고비라서 제꼈다.
대신 정량화된 필터링 방법을 찾아보는 것으로 방향을 바꾸었다. 필터링된 유니버스 안에서 찾아보는 수고 정도는 괜찮기 때문이다. 아래는 그의 스타일을 나름대로 정리해본 것이다.
핵심은 일관성과 이를 기반으로 한 높은 재투자 수익이다.
일관성: 장기적으로 수익성 있는 운영이 가능한 기업
수익의 일관성 + 성장성 / 낮은 부채와 좋은 현금 동원력 / 낮은 자본 지출 (+R&D)
같은 서비스를 수년 간 판매하면 직원 숙련도와 재고/자본 투자/마케팅 지출 감소에 도움이 된다.
손익계산서
순이익의 안정성 및 꾸준한 성장
매출 증가
규모의 경제 덕분에 판매량이 많아질수록 수익성이 높아짐
수익성
일관된 GrossMargin, NetMargin등
그 수익성의 성장.
대차대조표 + 기타 재무지표
꾸준한 성장 동력
장부가치 성장: 재투자 되는 사내 유보금의 일관된 성장.
혹은 CapEx 감소를 통한 높은 배당 수익.
ROE: 가치의 이론적인 상승 속도
유형 자산에 대한 수익률 : ROE와 함께 보면 좋다
낮은 장기 부채: Capital Cost 감소
현금 흐름표
자본 지출: 가능한 낮게 유지 (벌어들인 돈 대비 재투자)
더 나은 후보 등장.
성장 동력 약화.
시장이 미쳤을 때.
이 기준에 맞는 기업을 찾으려면 수많은 종목에 대한 과거 재무 데이터가 필요하다. 밸리 AI는 아직 api나 자동화 방법은 없고 문의해보니 스크리너는 도입한다고 한다. 나는 다른 곳에서 사서 쓰고 있다.
데이터는 구했다 치고, "10년 간 순이익률 > 5%" 이런 식으로 특정 값을 기준으로 하는 필터를 여러 겹 쌓아 필터링하는 것은 별로 좋은 아이디어가 아니다. 파라미터에 따라 과최적화 될 수 있고 특정 섹터를 편애하는 경향도 생긴다. 내 경험 상 보통 건축이나 1차 산업을 선호하게 되었다.
▽ 재무 데이터는 아래와 같이 상당히 비일관적인 경우가 많아서..
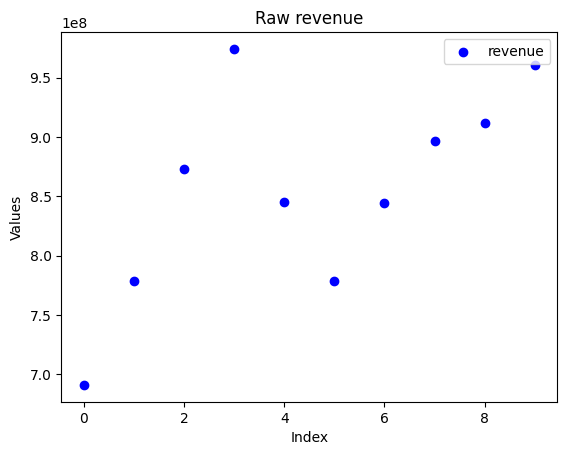
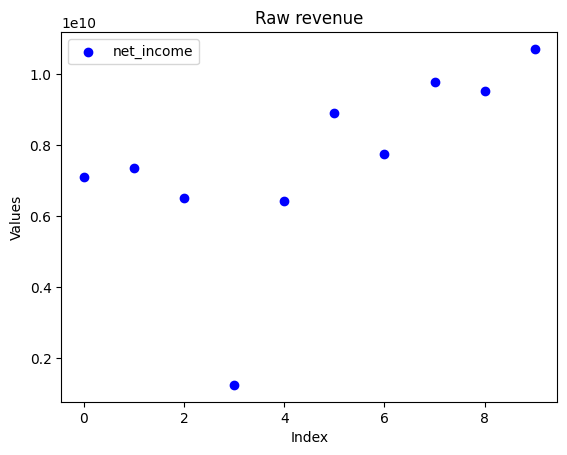
▽코카콜라의 순이익도 특정 해에 뚝 떨어진 적이 있어서 단순 필터링은 별로 좋은 방법이 아니다. (코카콜라마저도 놓치게 하니까)
그래서 전반적인 추세를 보았다. 재무 데이터는 시계열의 길이가 짧기 때문에 L-2 norm을 사용하는 일반적인 선형회귀를 하면 outlier에 취약한 편이다. 그래서 L-1 norm(절대값)을 함께 사용하는 선형회귀를 쓰는 것이 조금 더 낫다. 데이터 포인트가 적어 아주 큰 차이는 없지만 아무튼 좀 더 낫다. 이유는 수학적이라 패스.
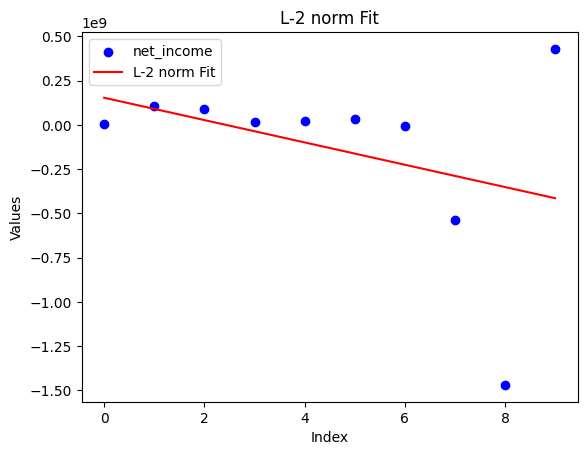
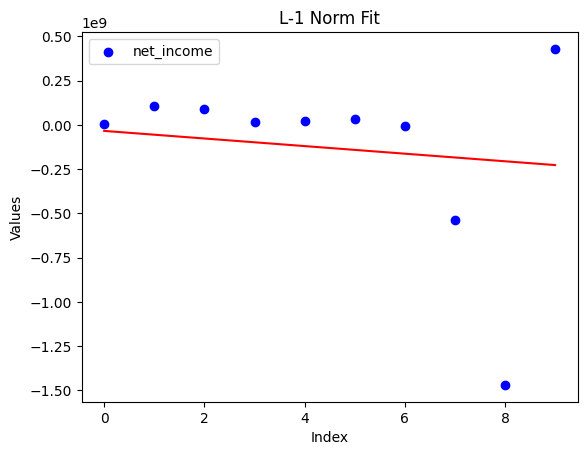
그러나 우리가 원하는 이상적인 기업은 수익이 꾸준히 증가하고 있을 것이다. 대략 성장률^햇수 형태로, 지수적으로 ...
