
자꿈두
구독자 9명구독중 5명
비판적으로 세상을 바라보지만 혁신적인 미래에는 낙관적인 투자자입니다.
찰리멍거와 워런 버핏의 투자 철학을 존경하며 지향하는 투자 철학을 가지고 있습니다.
DeepSeek-V3는 High-Flyer AI 헤지 펀드에서 분사한 중국 AI 연구 회사인 DeepSeek AI에서 개발한 대규모 언어 모델(LLM)입니다. 2024년 12월에 출시한 이 모델은 인상적인 성능과 비용 효율성으로 큰 주목을 받고 있습니다.
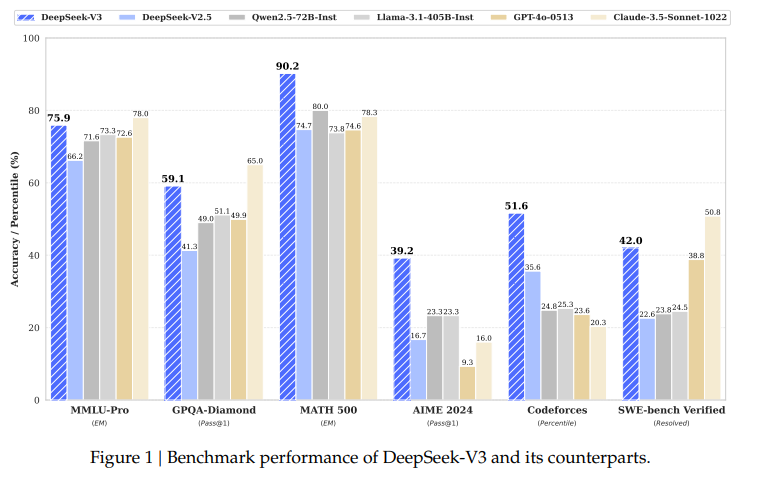
DeepSeek-V3는 각 입력에 대해 매개변수의 일부만 활성화하여 효율성을 높이는 Mixture-of-Experts (MoE) 아키텍처를 기반으로 합니다. 동적 리소스 할당을 통해 모델은 다양한 작업과 복잡성에 적응하여 성능과 에너지 소비를 모두 최적화할 수 있다고 이야기합니다. 6,710억 개의 매개변수를 가지고 있으며, 각 토큰당 370억 개의 매개변수를 활성화시키는 대규모 언어 모델입니다.
이미 DeepSeek-V2에서 검증된 비용 효율적인 추론 구조인 Multi-head Latent Attention(MLA) 구조와 DeepSeekMoE는 V3 모델에서도 계속 채택되어 사용주입니다. 이러한 두 가지 아키텍처는 DeepSeek-V2(DeepSeek-AI, 2024c)에서 검증되었으며, 효율적인 훈련과 유지하면서도 강력한 모델 성능을 유지할 수 있음을 증명하였다고 합니다.
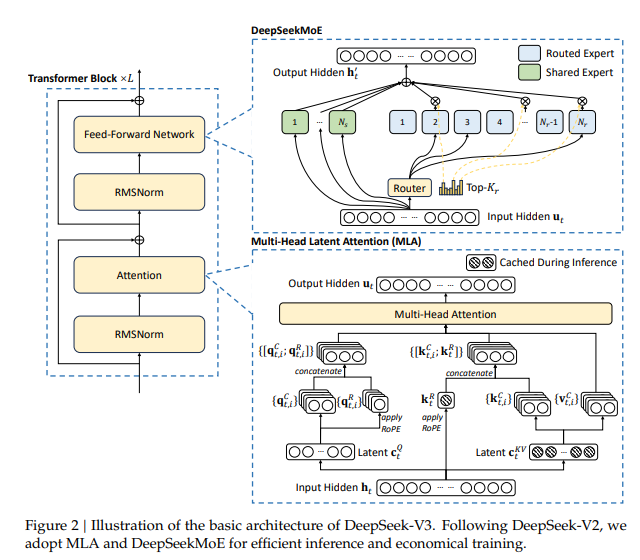
Multi-head Latent Attention(MLA): 이 메커니즘은 관련된 Key-Value 쌍을 압축하여 추론 중 메모리 소비를 줄입니다. 나중에 쉽게 기억할 수 있도록 핵심 정보를 요약하는 메모 작성 시스템이라고 생각하면 됩니다. 이를 통해 더 큰 Context Window와 더 효율적인 처리가 가능해집니다.
DeepSeekMoE: MoE 아키텍처를 기반으로 작동하는 DeepSeek의 MoE 알고리즘입니다. 크게 두 가지 전략을 사용합니다.
세분화된 전문가 분할: DeepSeekMoE는 각 전문가를 더 작고 특화된 부분으로 나눕니다. 각 전문가 팀은 특정 작업에 특화되어 있어, 필요한 정보를 빠륵 정확하게 처리할 수 있습니다.
공유 전문가 분리: 모든 작업에 공통적으로 필요한 지식을 처리하는 특별한 그룹입니다. 여러 파트에서 필요로 하는 정보를 제공합니다. 이를 통해 정보의 중복 저장을 방지하고, 각 전문가는 고유한 전문 분야에 집중할 수 있도록 합니다.
DeepSeek V3는 V2에 적용된 위 아키텍처 이외에도 더욱더 효율적인 알고리즘의 개선이 있었습니다.
Auxiliary-loss-free load balancing: 이 전략은 기존 MoE 모델의 일반적인 문제인 성증 저하 없이 균형 잡힌 전문가 로드를 보장하게 합니다. 기존 MoE 모델에서는 특정 전문가에게 과도한 작업이 몰리는 것을 방지하기 위해 Auxiliary loss 방식을 사용했습니다. 하지만 Auxiliary loss는 모델 학습에 불필요한 gradient를 발생시켜 성능을 저하시키는 문제가 있었습니다. DeepSeek-V3는 Auxiliary loss 대신 각 전문가의 Bias를 동적으로 조정하여 로드 밸런싱을 달성합니다. 아래와 같은 방식으로 DeepSeek-V3는 Aux loss 없이도 전문가들의 작업량을 균등하게 분배하여 효율적인 학습을 가능하게 합니다.
각 전문가는 입력 토큰에 대한 'Routing Score'를 가지고 있습니다.
Auxiliary-loss-free load balancing은 각 전문가의 Routing Score에 ...
