예상 하기는 했지만, Deepseek가 75% API영구 할인을 발표했다.
이제 Deepseek대비 Gemini pro는 14배 비싸고, Opus는 20배 비싸고 , GPT는 35배 비싸다.
성능 차이는 벤치마크 기준 5~15% 차이. 그 성능 차이를 위해 개인이 15~35배 비싼 비용을 계속 지불 할 수 있을까?
실제 AI API 비용은 얼마일까? 이래도 Deepseek는 마진을 남겨먹을거라는게..
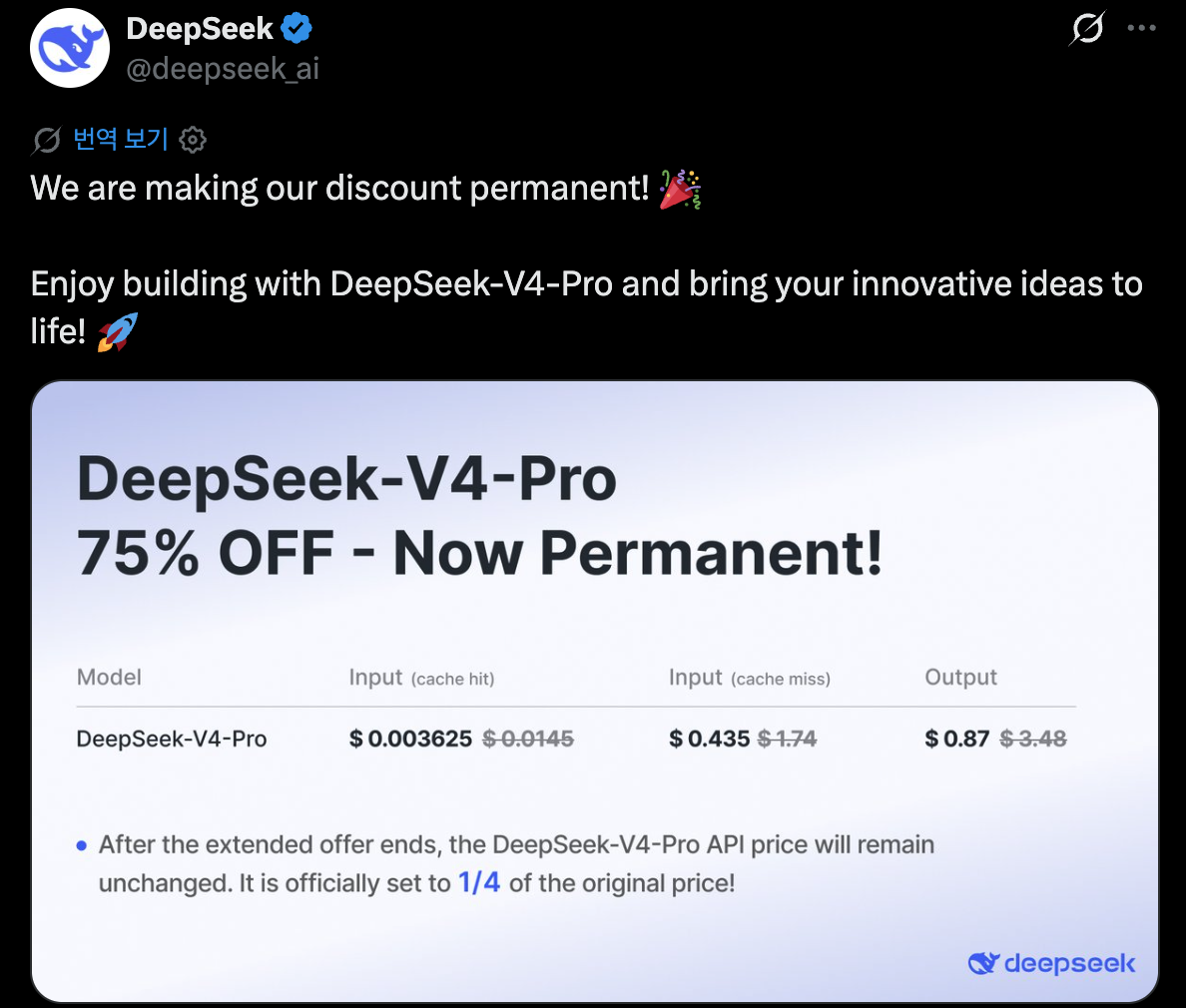

예상 하기는 했지만, Deepseek가 75% API영구 할인을 발표했다.
이제 Deepseek대비 Gemini pro는 14배 비싸고, Opus는 20배 비싸고 , GPT는 35배 비싸다.
성능 차이는 벤치마크 기준 5~15% 차이. 그 성능 차이를 위해 개인이 15~35배 비싼 비용을 계속 지불 할 수 있을까?
실제 AI API 비용은 얼마일까? 이래도 Deepseek는 마진을 남겨먹을거라는게..
덧. 미국 model들이 프리미엄을 엄청 붙이는 것은 맞다.
1. 프론티어 모델 성능 프리미엄. 소위 1등 프리미엄.
2. GPU 및 컴퓨팅 파워 부족으로 인한 프리미엄. 수요가 공급보다 훨씬 크니 비싸도 쓰는 것.
3. R&D 회수 비용.
4. 구독/무료 사용자 보조. 일반 사용자 비용 구조를 기업이 떠받치는 구조일 '수도' 있다. 실은 일반 사용자도 비싸게 쓰는 것일지도.
5. IPO 스토리용 마진 방어. 상장하면 우리는 고마진 플랫폼이 된다. 라는 네러티브.
덧2. 그러나, 중국 Model들이 점점 이렇게 API비용을 낮추고, 미국 API비용들은 계속 높아진다면, 시장이 물어보지 않을까? GPT, Claude의 높은 가격은 기술 때문인가? 아니면 컴퓨팅 파워 / 브랜드 프리미엄인가? 미국 model들이 중국에 비해 대단한 기술적 해자를 갖추고 있는가? 그리고 그게 방어 가능한가?
덧3. 이건 주관적인 의견이지만, GPT-4o이후에 기술혁신은 오히려 Deepseek에서 많이 나왔다. 이후 미국 Model들의 성능이 좋아지기는 했지만, Transformer급 새 패러다임이라기 보다는 스케일링, RL, Tool-use, 시스템 최적화와 같은 성능 개선에 가까웠다.
진짜 혁신은 지금처럼 'GPT가 Deepseek보다 10~15% 더 똑똑해'가 아니라 카파시가 예언한 '1B 모델이 지금 모델과 비슷한 실사용 지능을 내는 순간'이 있어야 한다고 본다.
OpenAI나 Anthropic이 IPO전에 그런 기술 혁신을 보여줄까?

딥시크는 구독모델 가성비 좋게 안내주려나요 ㅠㅠ
저는 Opencode go 구독을 이용합니다. 다만, 저는 Kimi, minimax, deepseek, glm, qwen 다 쓰고 싶어서 이용하는게 큽니다.
그렇군요! 감사합니다!!