

메인 파트를 들어가기 전 브리핑 기반의 결론·핵심 요약, 그리고 광학이 칩에 가까워지는 5단계 spectrum (Pluggables → LPO → OBO → NPO → CPO)을 다룬다.
원문 및 주 레퍼런스로 SemiAnalysis의 자료를 참고했다.
다만 반도체와 네트워킹에 대한 기술적 배경지식, 그리고 산업 트렌드와 사이클에 대한 기본 이해를 전제로 하기 때문에 대중적인 톤으로 작성된 자료는 아니다.
이에 CPO 5부작에서는 위 자료의 핵심 내용을 최대한 이해하기 쉬운 언어로 재해석하였다.
결론
CPO(Co-Packaged Optics)는 단순히 “네트워킹 전력 / 비용을 줄이는 기술”로 보기 어렵다.
더 정확한 투자 프레임은 다음과 같다:
Scale-out CPO는 개별 단위 기준, Optical Transceiver 대비 명확한 전력 절감 효과가 있으나, cluster-level TCO 개선폭은 제한적이다.
Scale-up CPO는 copper / SerDes scaling이 물리적 병목에 가까워지는 구간에서 더 전략적 의미가 크다.
즉, CPO adoption은 균일하게 진행되기보다 use case별로 갈릴 가능성이 높다.
Scale-out networking에서는 TCO, serviceability, reliability, interoperability가 adoption 속도를 제한할 수 있다.
Scale-up AI interconnect에서는 bandwidth density와 escape bandwidth 병목 때문에 CPO의 전략적 필요성이 더 커질 수 있다.
핵심 요약
구체적으로 들어가기 전, GPU 네트워킹은 세 가지 축으로 구분된다.

Scale-up은 로컬 클러스터 내 GPU 간 연결 (1–2 m, 초저지연·초고대역폭, NVLink 등),
Scale-out은 랙 간 / 클러스터 내 연결 (수십 m, 백엔드 광트랜시버 + spine / leaf),
Scale-across는 지리적으로 떨어진 데이터센터 간 연결 (km 단위, 800G / 1.6T 광트랜시버 직접 deployment).
본 article은 scale-up / scale-out 중심으로 다룬다.
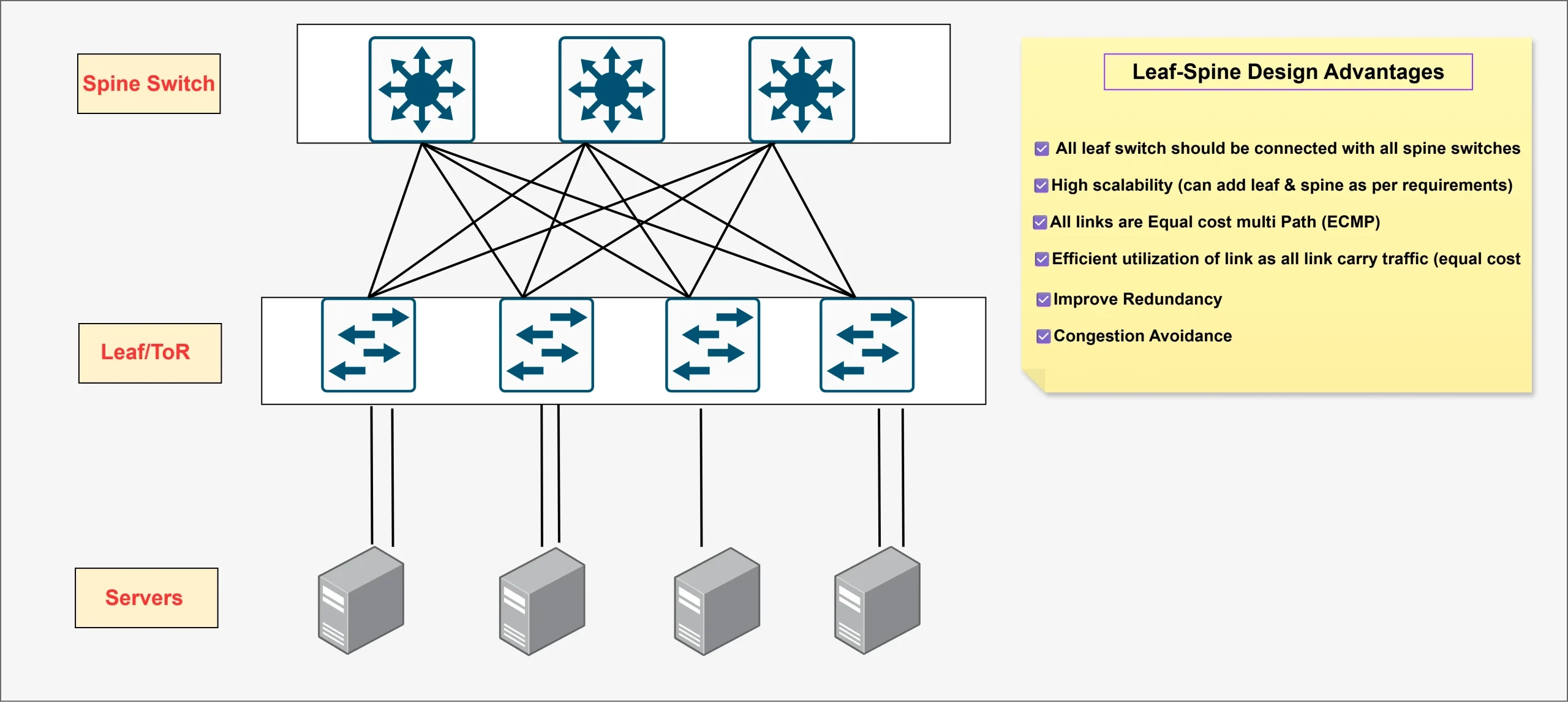
참고: Scale-out 네트워킹 구조
(1) 기존 구리 & 광학 트랜시버 네트워킹의 한계, CPO의 시사점
Copper 기반 scale-up link는 bandwidth는 크지만 reach가 짧다.
NVLink는 GPU당 매우 높은 bandwidth를 제공하지만, copper distance constraint (~2.2m) 때문에 단순 구리로만 네트워킹이 설계될 경우, scale-up domain은 대체로 1–2 rack 수준으로 제한된다.
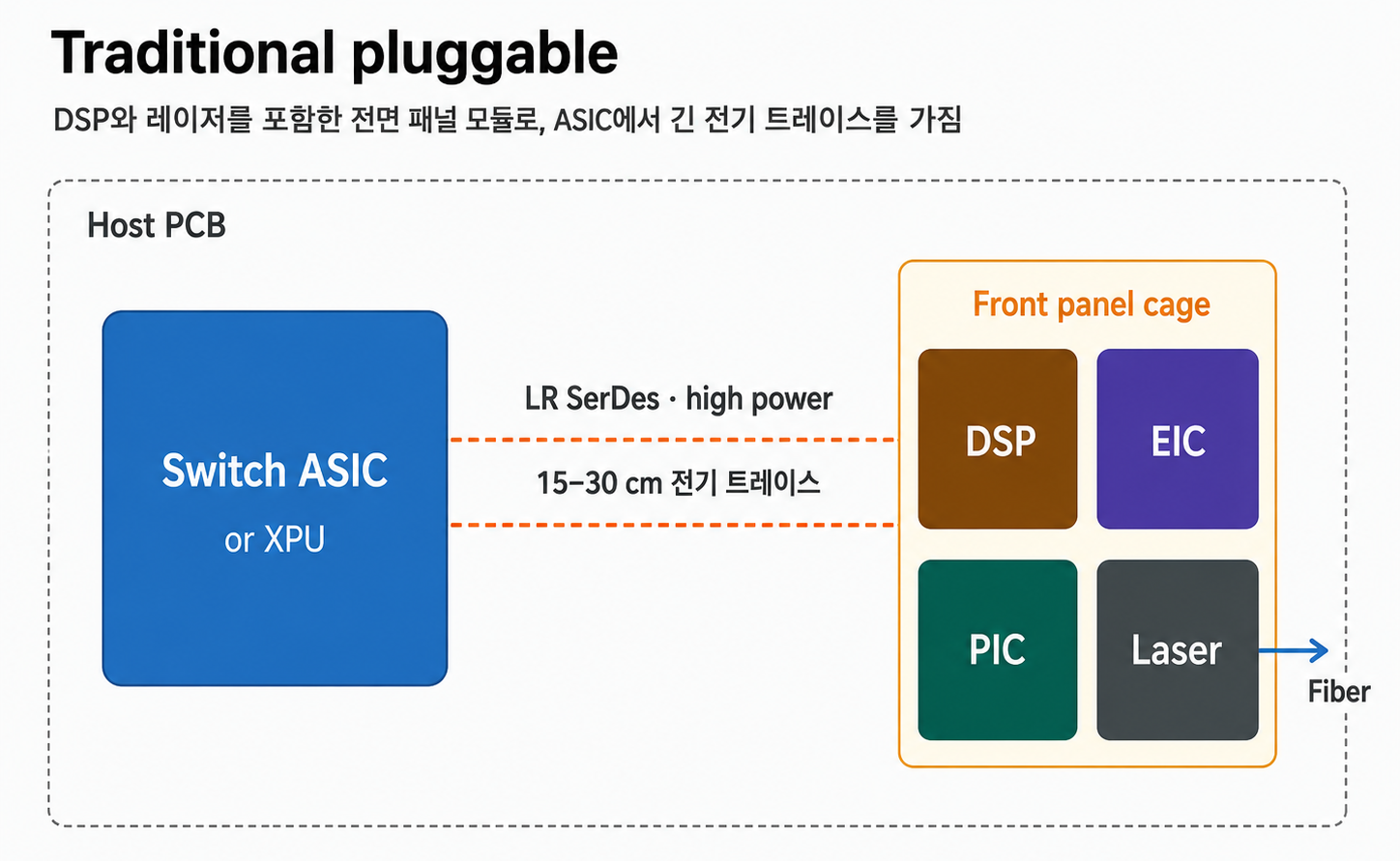
기존 Pluggable Transceiver는 이 reach 문제는 풀지만, optical conversion 이전에 전기로 이동해야 하는 trace가 길다.
Transceiver module은 front panel cage에 위치하며, XPU / Switch ASIC과 15–30cm 떨어져 있다.
데이터는 PCB와 connector를 따라 초고속 전기 신호로 이동해 module 내부 DSP까지 간 뒤, DSP / EIC / PIC가 이 신호를 광신호로 변환해 fiber로 송출한다.
이 과정에서 전기 경로가 길어져 connector·PCB 손실 때문에 power, latency, signal integrity 부담이 커진다.
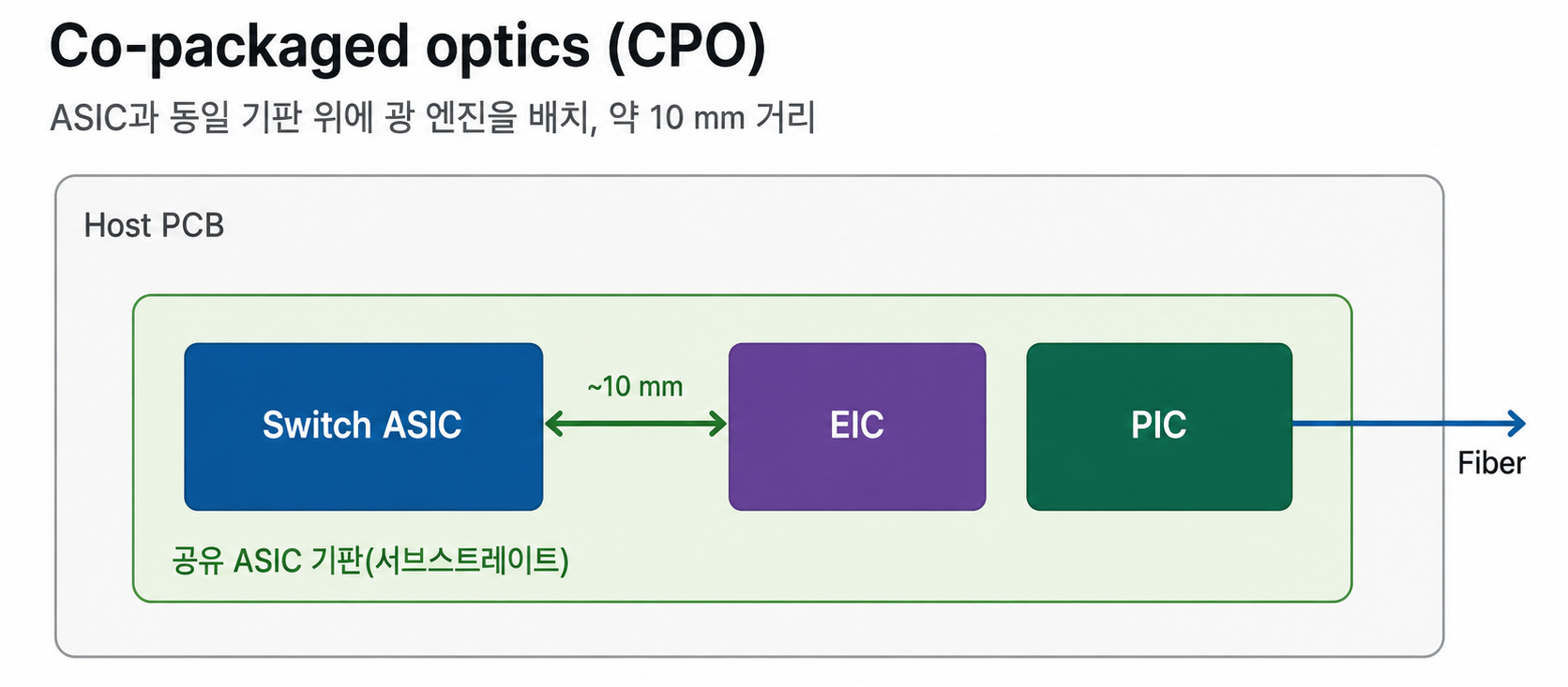
CPO는 ASIC과 optical engine 사이의 긴 electrical path를 패키지 내부로 압축하는 구조다. Optical engine을 ASIC 바로 옆, 같은 패키지 또는 기판 위에 배치해 전기 신호의 이동 거리를 크게 줄인다.
Optical engine이 ASIC 바로 옆에 배치된다.
기존 Pluggables처럼 신호가 보드 끝의 module까지 이동하지 않고, ASIC 근처에서 바로 광신호로 변환된다.
Electrical path가 짧아진다.
긴 PCB trace와 connector 구간이 줄어들면서 signal loss, parasitics, equalization 부담이 감소한다.
DSP 제거 또는 축소 가능성이 생긴다.
전기 경로가 짧아지면 강한 retiming / equalization이 덜 필요해져, 일부 구조에서는 DSP-less 또는 DSP-light architecture가 가능해진다.
단, 모든 CPO가 DSP를 완전히 제거하는 것은 아니다.
LR SerDes 대신 lower-power short-reach SerDes를 쓸 수 있다.
Pluggables은 보드와 connector를 건너야 하기 때문에 더 강한 long-reach SerDes가 필요하지만,
CPO는 ASIC–optical engine 간 거리가 짧아 lower-power SerDes로도 충분할 수 있다.
(2) CPO의 Scale-out vs Scale-up Economics
CPO의 scale-out economics는 component-level power saving만큼 강하게 보이지 않을 수 있다.
Optical module 또는 switch device 단위에서는 CPO가 electrical path를 줄이기 때문에 power saving 효과가 크다.
하지만 cluster-level로 올라가면 networking은 전체 power / cost의 일부에 불과하고, compute, memory, cooling, system integration 비용이 더 큰 비중을 차지한다.
따라서 CPO의 device-level 효율 개선이 최종 TCO 개선으로 1:1 전이되지는 않는다.
더 강한 strategic case는 scale-up interconnect에 있다.
Scale-up은 GPU / XPU 간 extremely high-bandwidth, low-latency 연결이 핵심이기 때문에 electrical interconnect의 물리적 한계가 더 직접적인 병목으로 작용한다. NVLink 같은 고대역폭 electrical fabric은 두 가지 scaling lever에서 동시에 압박을 받고 있다.
Per-lane speed: lane당 속도를 높일수록 SerDes loss, power, signal integrity 문제가 커진다.
Shoreline / lane count: 더 많은 lane을 넣고 싶어도 package edge, bump pitch, routing density가 제한한다.
⇒ CPO의 역할: optical engine을 ASIC 가까이 배치해 electrical distance를 centimeter-level에서 millimeter-level로 줄인다.
즉, scale-out에서 CPO는 power-saving story에 가깝지만, scale-up에서는 bandwidth scaling을 다시 가능하게 하는 architecture story에 가깝다.
