
<문제의식>
이 글은 하나의 단순한 질문에서 출발한다.
“대규모 언어 모델(LLM)이 서로 점점 비슷해지고, 누구나 접근할 수 있는 기본 인프라처럼 바뀐다면, 투자 관점에서 진짜 돈이 되는 자리는 어디인가?”
처음 생성형 AI 붐이 일었을 때 사람들의 시선은 거의 한곳만을 향했다.
“어떤 모델이 가장 똑똑한가?”, “누가 SOTA(State of the Art)를 찍었는가?”, “파라미터 수가 얼마인가?” 같은 질문이 자연스럽게 투자 스토리의 중심이 됐다. 그래서 “가장 뛰어난 모델을 가진 회사에 베팅해야 수익을 낼 수 있다”는 직관이 거의 상식처럼 받아들여졌다.
하지만 몇 년간 숫자와 산업 리포트, 인터뷰,벨리의 글들을 읽어보니, 이야기의 중심이 조금씩 다른 곳으로 옮겨가고 있음을 느낀다.
모델 간 성능 격차는 줄어들고, 오픈소스 모델은 빠르게 위로 치고 올라오고, 기업들은 비슷한 수준의 LLM을 각자 붙여서 서비스를 만든다.
어느 순간부터 질문이 바뀐다.
“어떤 LLM을 갖고 있느냐?”에서
“그 모델을 얹을 칩·전력·데이터센터, 그리고 도메인 애플리케이션과 데이터를 누가 더 탄탄하게 쥐고 있느냐?”로.
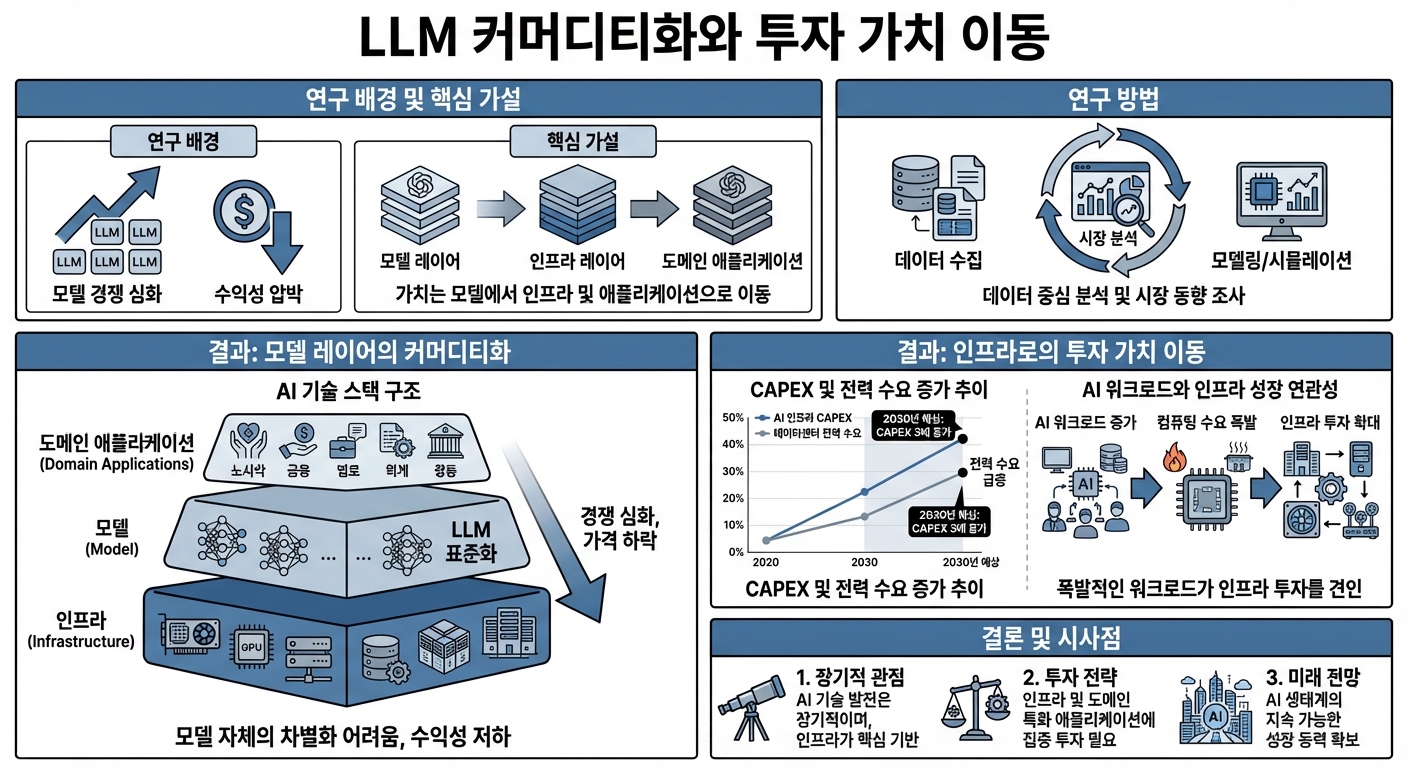
그래서 이 글은 세 가지 가설을 중심에 두고 이야기를 풀어본다.
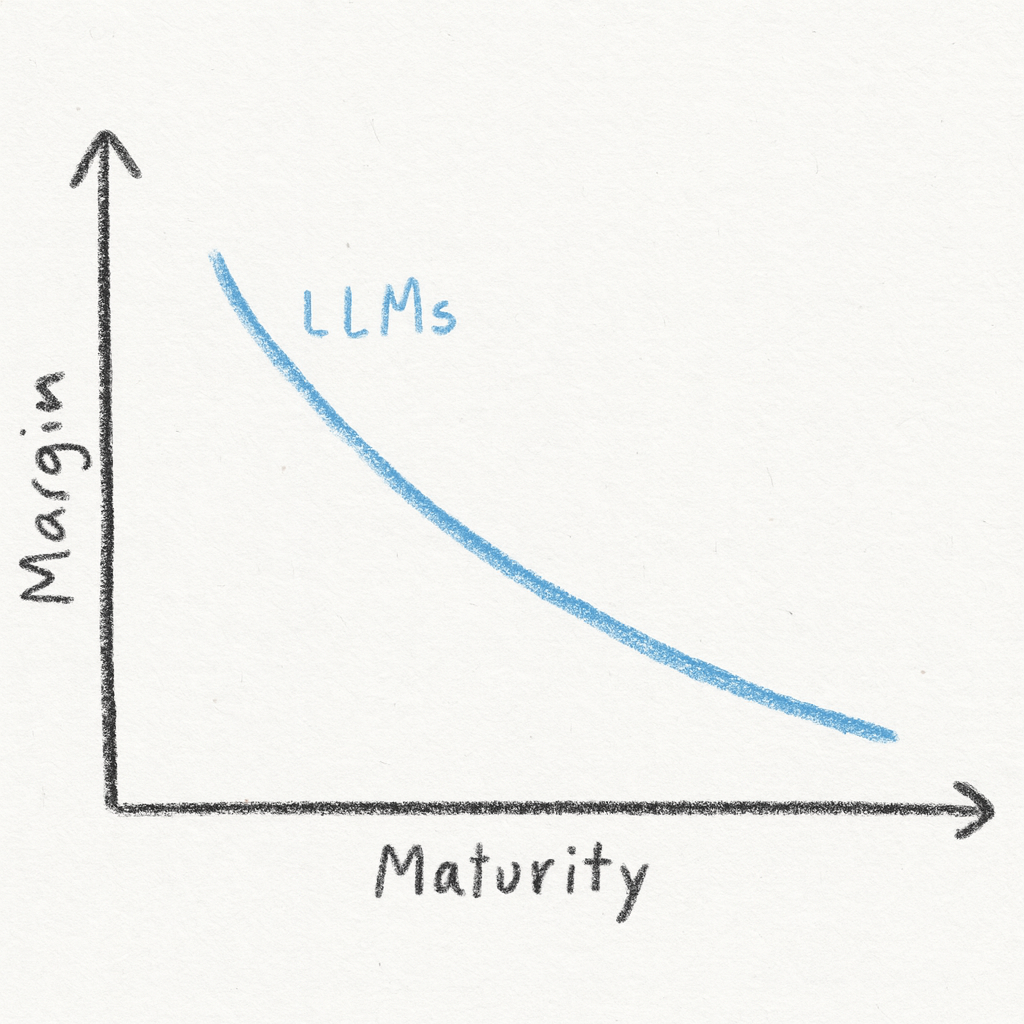
LLM이 커머디티에 가까워질수록, LLM 모델 자체에서 장기 초과수익(알파)을 얻기는 점점 어려워진다.
AI 확산은 칩·데이터센터·전력 같은 인프라 레이어에 구조적인 성장 기회를 제공한다.
GenAI가 만들어내는 경제 가치의 상당 부분은 실제 산업 현장에서 돌아가는 도메인 애플리케이션과 독점 데이터를 가진 기업들 쪽으로 귀속된다.
이를 검증하기보다는, 최소한 합리성이 있는 가설인지를 따져 보기 위해, 정량과 정성 자료를 반반 정도 섞어서 들여다봤다.
정량 쪽에서는 크게 세 축에 집중했다.
① 데이터센터 인프라 CAPEX(설비투자)
② 데이터센터 전력 소비
③ GenAI의 연간 경제 가치 추정치
예를 들어 GenAI의 잠재 경제 가치는 연간 2.6~4.4조 달러 수준으로 추정되고,
전 세계 데이터센터에는 2030년까지 누적 약 6.7조 달러의 CAPEX가 들어갈 것으로 예상된다.
데이터센터 인프라 연간 지출은 2024년 약 2,900억 달러에서 2030년 1조 달러 이상으로 불어날 것으로 잡혀 있고,
전력 소비는 2024년 기준 약 415TWh(전 세계 전력의 1.5%) 수준, 최근 5년 연평균 증가율은 12% 안팎이다.
정성 쪽에서는 마이크로소프트, Appian CTO, Amadeus Capital, Cambridge Associates, EY, 인도 중앙은행(RBI), Abraham Thomas 등의 논의를 추려서, 서로 다른 주체들이 가치 이동을 어디로 보고 있는지 공통된 시각을 뽑아 보려고 했다.
이 숫자와 이야기들을 한데 꿰어 보니 대략 이런 구조가 드러난다.
모델 레이어는 기술적으로 시스템의 ‘뇌’에 가깝지만, 가격 경쟁·규제·칩·전력·데이터센터 비용 압력 아래 있어, “장기 초과수익의 중심”이 되기엔 구조적으로 불리한 자리에 서게 된다.
반대로 칩·데이터센터·전력 인프라에는 수조 달러 규모 CAPEX가 몰려들고 있고,
도메인 애플리케이션과 데이터 레이어에서는 AI 도입이 생산성 향상을 실제 매출 증가·비용 절감·리스크 축소로 바꾸어 줄 여지가 크다.
결국 LLM 커머디티화 시대에 진짜 질문은 이렇게 옮겨 간다.
“어떤 모델이 SOTA(현시점에서 가장 뛰어난 성능)냐?”에서
“어느 레이어가 AI로 만든 생산성을 실제 돈으로 바꾸느냐?”로.
이 글은 그 변화된 질문 위에서, 칩·전력·툴링·도메인 앱·데이터 다섯 축을 투자 관점에서 다시 바라보려는 시도다.
1. 서론: 왜 지금 이 질문을 던져야 하는가
생성형 AI와 LLM이 등장했을 때 시장의 첫 반응은 단순했다.
“더 똑똑한 모델 = 더 좋은 투자처”라는 등식이다. 파라미터 수, 벤치마크 점수, SOTA 달성 여부가 곧 기업 가치의 프록시처럼 쓰였다.
하지만 몇 년이 지나며 느껴지는 분위기는 다르다.
오픈소스 모델이 상위 LLM을 빠르게 추격하고, 비슷한 수준의 모델이 여기저기서 쏟아져 나온다. 사용자는 “쓸 만한 모델”을 선택할 수 있는 옵션이 많아지고, 기업 입장에서도 “최고 모델”이 아니어도 충분히 사업을 굴릴 수 있는 상황이 된다.
이 지점에서 LLM은 “희소한 기술자산”에서 “여러 플레이어가 공유하는 기본 자원”으로 서서히 인식이 바뀐다.
내가 관심을 갖게 된 것도 바로 이 순간이다.
그렇다면 장기 알파는 어디에서 나오는가?
여전히 모델 제공사의 몫인가,
아니면 칩·전력·데이터센터를 포함한 인프라,
혹은 각 산업의 현장에 붙어 있는 애플리케이션과 데이터 쪽인가?
숫자와 레포트를 모아 보면 방향성은 명확해진다.
GenAI의 연간 잠재 경제 가치는 2.6~4.4조 달러,
데이터센터 인프라에 들어가는 누적 CAPEX는 2030년까지 6.7조 달러,
연간 인프라 지출은 2,900억 → 1조 달러,
전력 소비는 연평균 12%씩 증가 중이다.
이 정도 스케일의 돈과 전기가 움직이면 자연스럽게 떠오르는 질문은 단순하다.
“이 거대한 인풋이 만들어낼 ‘이익 풀’은 어떤 레이어에 축적될 것인가?”
내가 이번 글에서 하고 싶은 일은, 그 질문을 숫자와 서사를 통해 끝까지 밀어붙여 보는 것이다.
그리고 그 과정에서, 투자자가 어디를 봐야 하는지에 대한 나름의 프레임을 정리해 보려 한다.
2. 분석의 틀: 무엇을, 어떻게 보고 판단했는가
형식적으로 말하면 “연구 방법”이지만, 실제로 한 일은 비교적 단순하다.
“투자 판단에 쓸 수 있을 정도의 거칠지만 구조적인 그림을 그려보자”는 목표로, 정량 데이터와 정성 자료를 동시에 훑어본 것이다.
먼저 세운 질문은 세 가지였다.
모델 레이어
가격 경쟁, 규제, 인프라 비용, 경쟁자 수를 고려했을 때
LLM 모델 자체에서 두꺼운 마진과 장기 초과수익을 유지할 수 있는가?
인프라 레이어(칩·데이터센터·전력)
데이터센터 CAPEX와 전력 소비 증가 속도만 놓고 보더라도
이 영역은 구조적 성장 섹터로 봐도 좋은가?
성장성과 동시에 사이클 리스크는 어느 정도로 보아야 하는가?
도메인 애플리케이션·데이터 레이어
GenAI가 만들어낼 경제 가치 중
실제로 현금 흐름과 마진 개선으로 이어지는 부분이
어느 산업의 어떤 업무에서 나올 가능성이 큰가?
이 질문에 답하기 위해, 자료는 전부 공개된 2차 자료에서 가져왔다.
GenAI 경제 가치: 연간 2.6~4.4조 달러(맥킨지 추정)
데이터센터 CAPEX: 2030년까지 누적 6.7조 달러 수준
연간 인프라 지출: 2024년 2,900억 달러 → 2030년 1조 달러
데이터센터 전력: 2024년 415TWh(전 세계의 1.5%), 최근 5년 연평균 12% 증가
정성 자료는,
빅테크(마이크로소프트 등)의 공식 리포트,
엔터프라이즈 소프트웨어 기업 CTO 인터뷰,
VC·자산운용사의 AI 투자 리서치,
EY·RBI 등 정책·거시 분석,
그리고 데이터·LLM 방어력에 대한 개별 분석들을 ...

