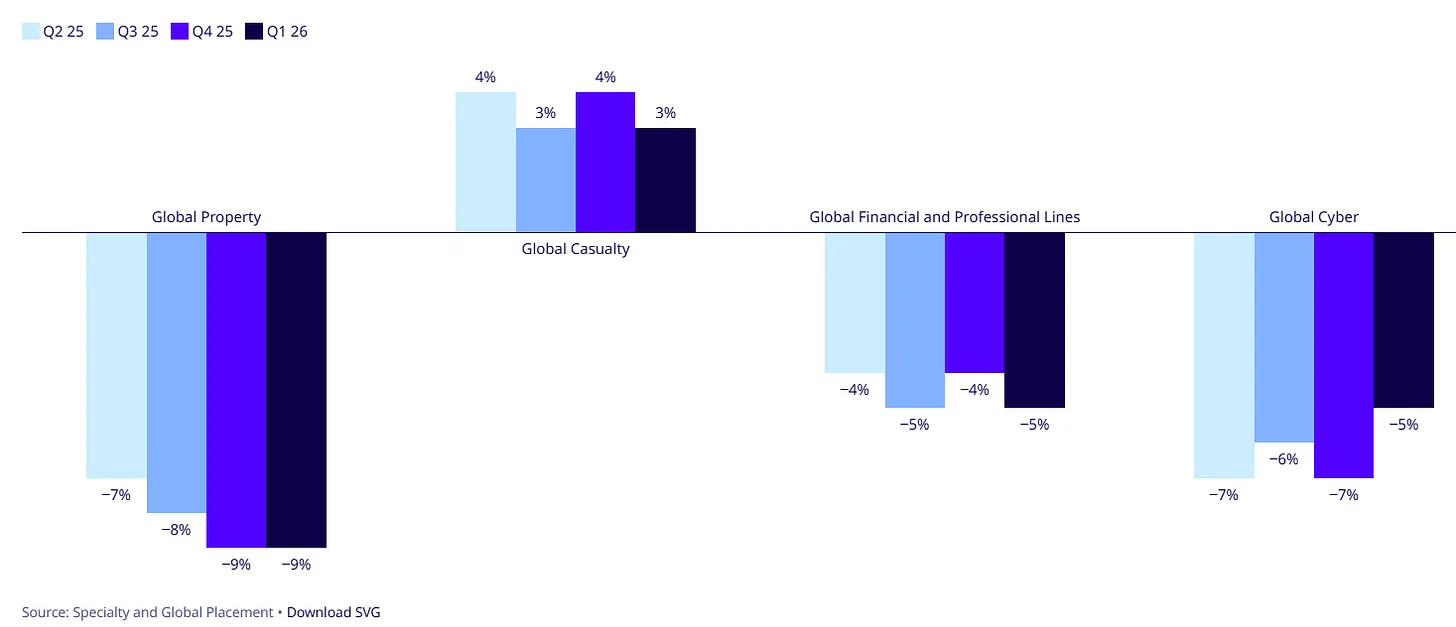
퀄리티기업연구소
구독자 1,408명구독중 112명
"투자의 질을 중시하며, 장기적 안목으로 시장을 바라봅니다. 비단 재테크뿐만 아니라 인생 전반에 걸쳐 복리의 힘을 믿고, 그 원칙을 실천에 옮기는 곳입니다. 여기서는 깊이 있는 분석과 지속 가능한 성장 전략을 공유하며, 함께 성장하는 지혜를 나눕니다."
생물학 연구에서 AI 에이전트의 활용을 확대하려면 데이터 인프라가 에이전트 친화적으로 설계되어야 한다. NCBI Virus에서 바이러스 시퀀스를 검색하는 과제에서 Claude, GPT 등 최첨단 모델들도 정확도 16.9~91.3%에 그쳤고, 같은 쿼리를 반복하면 매우 다른 결과를 얻었다. 하지만 결정론적 검색 도구인 gget virus를 추가하자 정확도는 90% 이상으로 올라갔고, 모델 간 성능 편차도 거의 사라졌다.
이는 소프트웨어처럼 생물학 데이터 인프라도 에이전트가 신뢰할 수 있게 탐색할 수 있도록 설계되어야 함을 보여준다. 창의적 추론은 모델에 맡기고, 데이터 접근·검증·메타데이터 처리 같은 기계적 작업은 신뢰할 수 있는 인터페이스로 표준화해야 한다. 이렇게 하면 더 저렴한 모델도 신뢰할 수 있게 되고, 과학 연구의 정확성과 재현성이 보장된다.
Laura Luebbert 저. Ferdous Nasri, Sarah Gurev, Patrick Varilly, Krithik Ramesh, Nuala A. O'Leary, Jonah Cool, Bernhard Y. Renard, Pardis Sabeti, Laura Luebbert의 연구를 바탕으로 함.
이 글에서 Laura Luebbert는 생물학적 데이터 인프라를 에이전트 친화적으로 만들어야 한다고 주장한다. 사례 연구로서, 그녀와 연구팀은 과학 연구 에이전트들(Claude, Biomni Open Source(Biomni OSS), Edison Analysis, GPT)에게 바이러스학자들이 감시 활동이나 진단 검사 개발 같은 작업에 활용하는 데이터베이스인 NCBI Virus에서 시퀀스 데이터를 검색하는 과제를 부여했다. 가장 강력한 모델조차 신뢰할 수 있는 데이터셋 구축에 필요한 수준의 정확도를 일관되게 달성하지 못했다. 그러나 연구팀이 결정론적 검색 레이어인 gget virus를 추가하자 정확도는 거의 100%에 근접했다. 과학 에이전트에 대한 더 넓은 교훈은, (현재로서는) 결정론적 검색 도구가 에이전트 워크플로의 신뢰성을 높이는 데 필수적이며, 생물학 데이터베이스는 규모 있는 사용자로서의 에이전트를 염두에 두고 설계되어야 한다는 것이다.
AI 에이전트를 활용해 생물학적 데이터 인프라를 탐색하는 것은, 자동차가 등장하기 전에 설계된 고도(古都)를 운전하는 것과 같다. 그 인프라는 아름답고 나름의 사려 깊음을 갖추고 있을지 몰라도, 현대 차량이 탐색하기 어려운 좁고 구불구불한 도로(독특한 파일 형식, 분산된 데이터베이스, 일회성 검색 스크립트)로 가득 차 있다. 교통 표지판, 주차장, 간간이 넓힌 도로 등으로 도시를 개량할 수 있지만, 기본 구조는 다른 이동 방식을 위해 설계되었기 때문에 탐색하기 여전히 어렵다. 반면 소프트웨어 인프라는 기본적으로 자동차(에이전트)의 필요에 맞게 만들어졌다. 포장된 도로, 명확한 차선, 표준화된 신호, 처음부터 끝까지 빠른 이동을 위해 설계된 시스템(버전 관리, 잘 문서화된 API, 패키지 매니저)이 그것이다.
그 결과, 코딩 에이전트는 생물학 에이전트보다 훨씬 빠르게 발전했다. 소프트웨어는 일반적으로 구조화된 디지털 워크플로와 신뢰할 수 있는 인터페이스를 제공하는 반면, 데이터 검색 및 검증에 필요한 전산 생물학 인프라는 종종 취약하고 이질적이며 프로세스에 의존적이다. 이를 탐색하는 도구들은 필연적으로 맞춤 제작되어 특정 도메인이나 가설에 맞게 조율된다. 더욱이 소프트웨어는 빠르게 컴파일하고 검증할 수 있는 테스트 가능한 출력물을 제공하는 반면(예: 프로젝트 테스트를 통과하는 패치를 생성해 GitHub 이슈를 해결하는 것), 생물학은 단순하면서도 검증 가능하고 의미 있는 보상 지표가 거의 없다.
따라서 생물학 에이전트의 병목은 추론 능력만의 문제가 아니라, 생물학적 데이터를 쿼리하기 위한 결정론적 실행 레이어의 부재에 있다. 과학자는 의도를 표현할 수 있다(예: 이 도메인을 가진 모든 인간 키나아제를 찾고 그 구조를 가져와라). 하지만 에이전트는 필요한 정보를 담고 있는 데이터베이스에 접근할 신뢰할 만한 방법을 갖추지 못한 경우가 많다.
생물학 및 과학 워크플로에서는 작은 오류조차 심각한 결과를 초래할 수 있다. 예를 들어 잘못된 게놈 빌드에서 좌표를 검색하면 하위 생물학적 해석 전체가 무효화될 수 있다. 의도치 않게 RefSeq과 GenBank 레코드를 혼합하거나, 불완전한 게놈을 완전한 게놈으로 취급하거나, 분절 바이러스에서 분절 명칭을 혼동하거나, 일관성 없는 메타데이터 필드로 인해 관련 레코드를 놓치는 것도 마찬가지다. 연구의 매력이자 어려움은, 세부 사항이 결정적으로 중요한 경우가 많다는 데 있다.
이탈리아 언덕 마을을 운전하는 것과 같이, 도로가 너무 좁고 모퉁이가 너무 가파르며 길이 현지 지식에 의존한다면 차가 아무리 강력해도 소용없다. 에이전트가 발병 대응부터 신약 설계, 생물학적 모델링에 이르기까지 과학적 발견을 돕기를 원한다면, 인간이 탐색하는 것만큼 신뢰성 있게 탐색할 수 있는 생물학적 데이터 인프라를 구축해야 한다.
웹 개발에 관한 Karpathy의 강의가 AI 에이전트를 이용한 생물학 연구에 시사하는 것
에이전트의 필요와 인간을 위해 구축된 도구 사이의 이러한 불일치는 생물학에만 국한된 문제가 아니다. 에이전트가 인간 전용으로 설계된 환경에 투입되는 곳이라면 어디서든 동일한 마찰이 발생한다.
몇 달 전, Andrej Karpathy는 AI 시대의 소프트웨어에 관한 강연을 하면서 몹시 낯익게 들리는 불평을 늘어놓았다. 그는 작은 웹 앱을 바이브 코딩으로 만들었는데, 실제 서비스(인증, 결제, 배포)로 만들려 했을 때 브라우저 대시보드를 클릭하며 일주일을 날려버렸다.
그가 요약한 것처럼, "코드는 가장 쉬운 부분이었다! 대부분의 작업은 브라우저에서 이것저것 클릭하는 데 있었다." 문서는 계속해서 "이 URL로 가서 이 드롭다운을 클릭하라"고만 안내했다. 그의 결론은, 아무도 이런 일을 해서는 안 된다는 것이었다. 대신 우리는 에이전트를 위해 구축해야 한다.
Karpathy는 소프트웨어 에이전트의 세계에서 생물학 연구자들이 오랫동안 씨름해 온 것, 즉 이질적인 정보와 암묵적 관습, 브라우저를 클릭하는 인간을 중심으로 구축된 환경에서 지능형 시스템을 작동시키려는 고통을 새삼 경험했던 것이다.
AI 에이전트가 등장하기 훨씬 전부터, 전산 생물학자와 유전학자들은 이 문제를 조금씩 해결하기 위해 전통적인 전산 생물학 도구를 개발하기 시작했다. Biopython, BioPerl, BioJulia, Entrez Direct, BioMart, gget, 그리고 수많은 워크플로 라이브러리들은 모두 생물학 데이터를 브라우저 인터페이스에서 꺼내어 연구자들이 직접 연산할 수 있는 공간으로 옮기려는 노력들이다.
문제는 생물학 데이터가 단일 인터페이스를 가진 단일 데이터베이스에 존재하지 않는다는 것이다. 그것은 각자의 식별자, 관습, 형식, 필터링 로직, 프로그래밍 방식의 접근 수준을 가진 지저분한 도로망이다. 일부 데이터는 프로그래밍 방식으로 접근하기 간단하다. 그러나 그렇지 않은 경우도 많다.
특히 바이러스학은 더 어려운 사례 중 하나다. 백신 및 진단 검사 설계에서 단백질 모델 학습 데이터 구축에 이르는 연구 워크플로는 종종 NCBI Virus에서 시퀀스를 검색하는 것에서 시작된다. NCBI Virus는 검색 가능한 웹...