데이터에 익숙하지 않은 이들을 위한 팔란티어(PLTR) 소개2
1편을 쓰고 나서 글을 다시 읽어보니,
인사이트도 부족하고 설명은 복잡하기만 해서 이게 무슨 도움이 될까 싶어 사실 2편은 쓰지 않으려 했다.
유튜브에 이미 수 많은 영상들이 넘쳐나는데, 개발자도 아닌 비전문가가 굳이 소음을 더할 필요가 있나 싶었는데
감사하게도 몇몇 분들이 2편 작성을 요청해주셔서, 부족하지만 용기내서 소음을 좀 더 보태본다.
이 글은 어디까지나 데이터를 다루는 사람이, 데이터에 익숙하지 않은 이들을 위해 작성한 글이다.
1편에서는 'Ontology'의 중요성에 대해서 설명했고,
2편에서는 이 과정에서 어떤 지점들이 해자로 작용할 수 있는지,
그리고 팔란티어(PLTR)가 이를 지켜내는게 가능할지를 최대한 쉽게 풀어보려 한다.
데이터를 다루는 입장에서 개인적인으로 생각할 때, 해자가 될 수 있는 주요 지점은 세 가지다.
비정형 데이터의 처리
데이터 학습과 분석 알고리즘의 고도화
데이터 보안
1. 비정형 데이터의 처리
당연한 이야기지만 컴퓨터는 사람이 아니다.
때문에 인공지능을 만들기 위해 데이터를 학습하는 컴퓨터의 모델은,
우리 사람이 사용하는 '자연어'와 같은 '비정형 데이터'들을 이해하지 못한다.
'정형 데이터'는 1편에서의 예시와 같은 규칙을 가진 데이터 테이블을 의미하고,
'비정형 데이터'는 데이터베이스나 표 형식에 맞춰 정리되지 않고, 특정한 규칙 없이 저장된 모든 데이터를 의미한다.
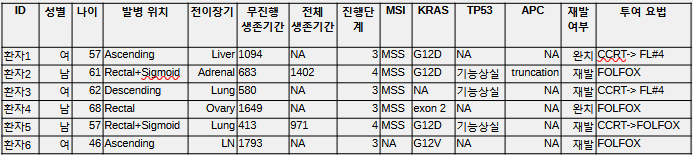
<정형 데이터의 예시 - 1편의 의료 정보 테이블>
데이터를 생산하는건 우리 인간인데, 컴퓨터에게 인간의 언어인 '자연어'는 전처리(Pre processing) 없이는 이해할 수 없는 비정형 데이터다. 데이터를 이용하려는 입장에서 이거 참 답답한 일이다.
그래서 과거부터 데이터 학습(Data learning)에 있어서 가장 중요한 작업은 데이터를 목적에 맞는 형태로 변환하는 것이었다.
이를 위해 Feature, Phenotype, Category와 같은 정보 객체(Object)를 데이터에 할당하는 과정이 필요하다.
이 과정이 바로 데이터 처리과정(Data processing)이며, 사실상 이게 데이터를 다루는 '사람'이 하는 알파이자 오메가이다.
(데이터를 Encoding하고, Cleaning하기도 하고, Trimming하기도 하고, Transformation하기도 한다. 이 부분은 몰라도 된다.)
그리고 요즘에는 이러한 데이터 처리 과정을 자동화하는 기술에 많은 연구가 집중되고 있다.
당연하지만, 우리가 일상에서 나누는 대화나 다른 비정형 데이터들도 각기 고유한 규칙을 가지고 있다.
이 '규칙'이 있기 때문에 우리가 그것을 해석하고 이해할 수 있는 것이다.
다만, 이러한 규칙들은 컴퓨터 모델이 이해할 수 있게 조건문으로 분류하기엔 너무 복잡하고, 규칙을 지키지 않는 예외들도 존재하기 때문에, 비정형 데이터를 컴퓨터가 인식할 수 있는 구조화된 데이터로 자동 전환하는 데에는 많은 난관이 존재한다.
예를들어, 저녁 메뉴를 정할 때 점심에 먹은 메뉴와 겹치지 않게 하기 위해,
상대방에게 '오늘 점심에 무엇을 먹었는지'를 묻는 상황을 생각해보자.
수도 없이 다양한 표현들이 있지만, 간략하게 아래의 다섯 문장만 살펴보면
1) '야, 너 오늘 점심 어떤거 먹었어?'
2) '사장님, 오늘 오찬은 어떤 걸 드셨습니까?'
3) '뭐 먹었어, 너 오늘 점심?'
4) '님, 점심 뭐 먹?
5) '마, 니 오늘 점심 때 뭐 뭇노?'
이때 표준을 1)이라고 하면, 1)과 비교해서
2)는 점심 식사란 단어 대신 '오찬'이란 한자어로 축약되어 사용되었다. 존댓말이 쓰였다.
3)은 문장에 쓰인 단어의 어순이 바뀌었다.
4)는 축약어가 사용되었다. 온전한 이해를 위해서는 대화 맥락이 필요할 수도 있다.
5)는 표준어가 아닌 사투리로 사용 단어들이 바뀌었다.
의 차이점을 가지고 있다.
단어가 사용되는 위치와 사용된 단어 자체에 뭐 하나 일관성이 없음에도 불구하고
모두 상대에게 '오늘 점심에 무엇을 먹었는지'를 묻는 문장이다.
간단한 문장도 이런데, 더 긴 문장들과 다양한 상황은 얼마나 더 복잡하겠는가? 거기에 동음 이의어는?
때문에 자연어의 복잡성과 규칙의 예외성으로 인해, '연역적' 방식으로 이 문제를 해결하기에는 한계가 있다.
그래서 해당 한계를 극복하기 위해 현대의 자연어 처리(NLP, Natural Language Processing) 모델은 일부 연역적 규칙 아래에 수많은 문장을 학습하고, 이를 통해 규칙과 패턴을 역으로 추론하는 귀납적 방식으로 데이터 처리를 자동화하는 방식을 택했다.
이게 어느 단계까지 왔냐면, 요즘은 병원에서 수기로 작성하던 환자 차트도
의사와 환자의 문진 대화 -> 음성언어를 텍스트 데이터화 -> 텍스트 데이터를 바탕으로 환자 차트 작성 -> 작성된 환자 차트에서 필요한 데이터를 추출하여 환자 정보 테이블을 작성
까지 자동화해주는 프로그램이 도입되기 위해 테스트가 진행 중에 있다.
1편에서 실제 예시 설명을 위해 첨부한 환자 정보 테이블의 경우도 그렇게 만들어졌다.
물론 프로그램의 차트 작성이 완벽하지 못해서, 작성된 차트 내용이 정확한지 검수하는 작업이 반드시 필요하다.
그리고 꽤 많이 수정이 들어간다. 아직까지는 완벽한 자동화가 아니라, 수고를 줄여주는 보조적 기능에 그친다고 봐야하지만
비정형 데이터 처리를 위해 ...