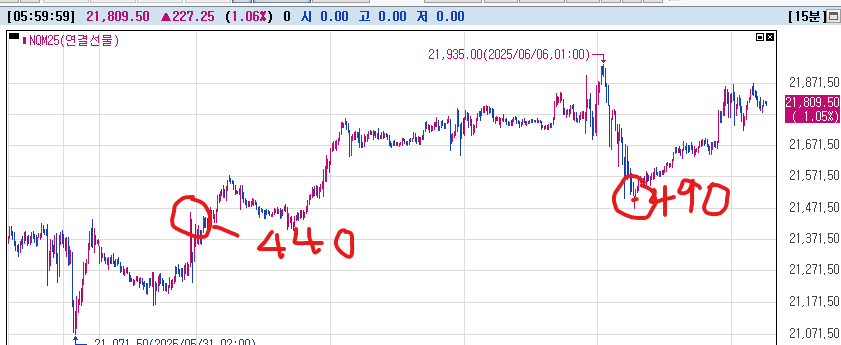
대장내시경 받고오느라 죽는줄알았네
휴 요즘속이-안좋아서 난생처음으로 대장위내시경받고왔는데
위대장은 클린한데 맹장염의심... 의심이라 일단 냅두긴했는데 무섭구만...
내시경한다고 반나절굶고 반나절장정결제먹으니 일상의 소중함을 바로체감...행복이란게 별거아니구나...
삼계탕 구슬아이스크림 연어초밥을 먹을 수 있는게 행복이구나...
정신차려보니 나스닥은 개떡상해있는데 나스닥 롱포지션보다 엔롱원숏 오일숏이 더털려서 약손실... 나스닥롱업섰으면 진짜조떌뻔...
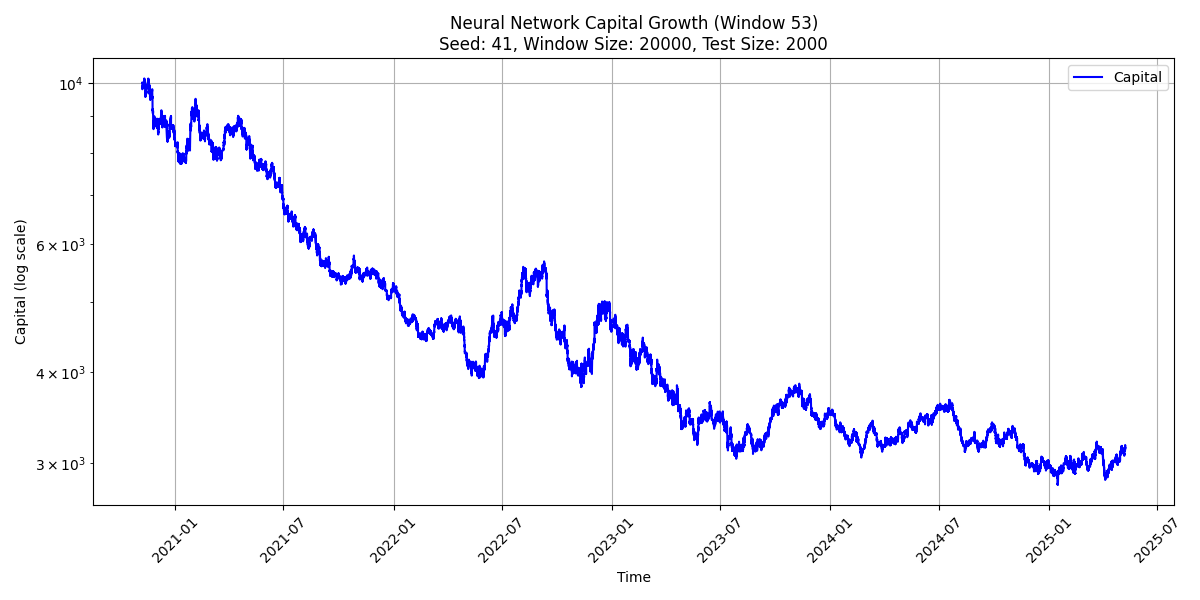
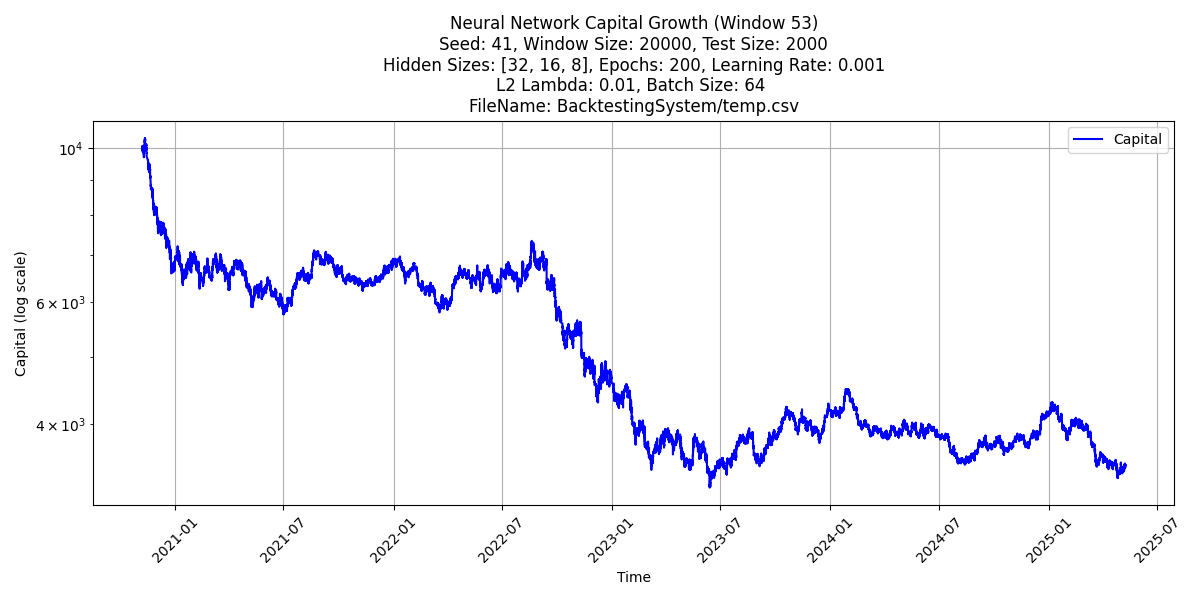
엊그제 ANN과의 사투를 벌였는데 그 과결과를 좀 정리해보자.. 하도 많이 시뮬을돌려서 리뷰에도 좀 시간이걸릴듯하다
저번에 이제 ANN(그냥 일반 평범하고 특색없는 단순 멀티레이어 뉴럴네트워크)을 돌려 봤는데 생각보다 퍼포먼스가 너무안좋아서 놀란상태였다. ANN은 그걸 쓰려고 돌린게아니라 내가 실제로 제작하고 사용하는 커스텀머신러닝알고리즘의 퍼포먼스가 알고리즘이 좋아서나오는건지 아니면 걍 학습시키기 좋은 데이터셋이라 나오는건지에 대한 컨트롤알고리즘느낌으로다 해본건데 뭘 해도 퍼포먼스가 별로여서 좀놀랐다. 이럴떄는 항상 뭔가 코드자체가 잘못돼서 결과가 애초에 얼탱이없게 나오는경우가 있기때문에 좀 꼼꼼하게 테스트를 해보고있었다.
일단은... 메인알고리즘 트레이닝-테스트 방식과 동일한 20000트레인 2000테스트에서 뭔짓을해도(히든레이어 규모 변경 / 트레이닝 epoch수변경(validationSet/Earlystopping 은 안함) / 오버피팅방지레귤러라이제이션 넣다뻇다) 계속 안정적으로 마이너스가 나온다.
뭐 오타났나? 해서 롱판단때 숏치고 숏판단때 롱쳐도
딱 거꾸로 나온다
여기서 좀 재밌던 것은
이제 기본적으로 전략은(레버리지포함) 궁극적으로 log(wealth)의 기댓값을 최대화하는 것을 목표하는 방향으로 나아간다
이건 뭐냐면, 어떤 베팅에서 결과가 나왔을 때, 단순기댓값으로는 50% 이익이나 50% 손실이나 똑같은거지만, 50% 손실을 본 뒤에 그걸 복구하려면 50% 이익이 아니라 100% 이익이 필요하다는 거를 고려해서, 50% 손실을 100% 이익과 동일한 가치(부호만 바뀐)로 보는 것이다. 만약 내가 워렌버핏이여서 돈이 한 1000조있는데, 여기서 1000조를 먹어봣자 그냥 2000조가 되지만(워렌버핏정도면 5년정도면 자연스럽게 2천조가 될 수 있다), 1000조를 꼴으면 바로 일반인1이 되어 버리고 그 뒤에 다시 1000조를 버는 것은 100년이 주어져도 악마적으로 어려운 일일 것임을 생각해 보면 될 것이다.
즉 내가 100억으로 투자하면, 100억을 1단계로 놓고, 100억->200억 은 +1단계, 100->200억->400억 은 토탈 +2단계, 100억 -> 800억은 +3단계, 100억->50 억은 -1단계, 100억 -> 25억은 -2단계, 100억 -> 12.5억은 -3단계...
즉 100억->800억이 되는 시나리오에서 실질적인 효용(가치)가 100억->12.5억 시나리오 와 동일하다고 보는 것이다.
어쨋든 그런 의미에서...
첫번째 그림에서는 10000에서 시작한 캐피털이 대충 3300내외에서 끝나고, 두번쨰는(뒤집은거) 21000내외에서 끝난다
둘은 그냥 완벽하게 상반된 전략임에도 불구하고 말이다.(참고로 여기서 트레이딩코스트는 0으로 가정되어잇다)
2배 / 0.5배를 +1단계 -1단계로 보는 관점에서,
첫번째는 -1.6단계 / 두번쨰는 +1.07단계...
+1단계를 -1단계로 취급하는 똑같은 전략에 방향성만 정반대인 건데 왜 결과가 단순부호뿐만아니라 그 정도까지 다른것이 이상하다고 처음 생각이 들었었고, 혹시 내가 레버리지 및 캐피털 시뮬레이션에서 뭔가 실수를 한게 아닌가 싶었따
capital = capital * (1 + dynamic_leverage * currentPosition * (np.exp(Ovector_15_T[i]) - 1))
캐피털을 업데이트하는 코드는 아래와 같다.
dynamic 레버리지는 변동성(이라고 부르고 실제로는 표준편차)의 역수에 대충 비례하게 해놓고, 현재포지션이 롱이면 +1, 숏이면 -1을 넣게 하고, 세번째 항에서 실수를 했나 했다.
Ovector_15_T[i] 는 15분 뒤의 가격변화량이다(기계학습의 학습 타겟). 근데 왜 1을 빼고 exponential함수;exp(X) = e^X 에 넣었을까? 나는 여기서 실수한줄 아랐는데 다시 가서 생각해보니 가격에 애초에 log를 씌워놨었다는 사실을 떠올렸다. 애초에 예측해야 하는 가격(예를들자면, 나스닥100선물 가격)에 log를 씌워놓고 시작한 것이다. 그게 더 적절한 이유는, 단순히 우리가 log(wealth)를 최대화하는 것을 목적으로 하는 것 뿐만이 아니라(전재산가지고 나선만 거래하는게 아니라는 점을 생각해보면), 증권상품가격의 히스토리로부터 의미가 높다고 생각되는 여러 feature(지표들이라고 볼 수 있겠다)들을 추출해내는 과정에서, log를 씌워놓고 시작했을 때 더 일관성을 가지는 경우가 많기 때문이다.
이렇게 s&p 히스토리컬을 봐보면 1970년대 전에는 그냥 아무일도 없이 잔잔하다가 그 이후로 유의미한 가격 변화가 생긴 것 같은 느낌이지만, 당연히 그 전에도 그 전의 가격 레벨대에 ...