
머신러닝은 컴퓨터라는 도구로 하여금 경험을 활용해 시스템 자체를 개선해 나가는 학문이다. 컴퓨터 시스템에서 일반적으로 경험은 데이터라는 형식으로 존재하고, 따라서 머신러닝이 연구하는 주요 내용은 학습 알고리즘, 즉 컴퓨터를 활용해 데이터에서 하나의 모델(이 책에서 사용하는 ‘모델’은 데이터를 통해 학습한 결과를 뜻한다)을 만들어내는 알고리즘이라 할 수 있다.
머신러닝의 기본 용어
잘 익은 수박을 고르는 상황을 가정하자. 줄이 선명한 수박을 찾아 두드려 보고, 청명한 소리가 나는지 이것저것 확인해 본다. 세개 정도 확인해 보니 다음과 같은 수박이 있다고 기록했다.
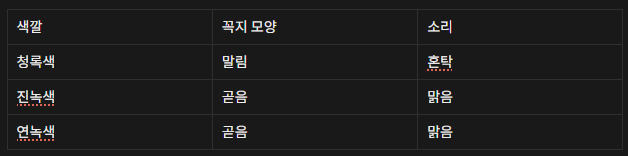
이 표를 통해 머신러닝에서 쓰이는 용어들을 정의할 수 있는데, 다음과 같다.
데이터셋 관련 용어
data set: 모든 기록의 집합
sample(instance): 표의 행(하나의 수박에 대한 기록)
attribute(feature): 열의 제목(수박의 속성)
attribute value: 청록색, 곧음 등의 속성을 나타내는 값
attribute space: 각 열에 대한 1차원 공간
sample space: 각 열로 이루어진 n(여기서는 3)차원 공간
dimensionality: 열의 개수
feature vector: 샘플이 샘플 공간에서 표현된 벡터
데이터셋 관련 수학적 표현
m개의 샘플을 가진 데이터 세트
샘플 x_i는 d차원 샘플공간 X위 하나의 벡터이다.
x_{ij}는 i번째 샘플의 j번째 속성값이다.
학습 관련 용어
learning(training): 데이터를 통해 모델을 만들어 가는 과정
training data(training set): 훈련 과정에서 사용된 데이터(데이터셋)
training sample: 훈련 과정에서 사용된 데이터 중 하나의 샘플
hypothesis: 훈련된 모델이 따른다고 제기되는 규칙
ground truth: 훈련된 모델이 따른다고 확인된 규칙
learner(학습기): 모델의 또다른 방언
prediction: 훈련 과정에서 사용되지 않은 데이터를 모델에 입력했을 때 나오는 결과
label (y_i): 훈련 과정에서 훈련을 돕기 위해 사용하는 데이터의 ...
![[BOOK] AFML 5](https://post-image.valley.town/V-KrfT5_g1JywwZiVq3nH.png)
![[BOOK] AFML 3](https://post-image.valley.town/1jwLhoH8F4K7iEvk_16xd.png)
![[BOOK] AFML 2 실습](https://post-image.valley.town/iryd5lWtKnjhW23pNAxjN.png)
![[BOOK] AFML 2](https://post-image.valley.town/H62zZBkLy7nzAU0VlsZy1.png)