
1. 13년 만의 I/O 폭 변화 — 왜 지금인가
2013년 SK하이닉스가 첫 HBM을 양산한 이후 13년 동안 변하지 않은 숫자가 있습니다.
I/O 폭 1024-bit입니다.
HBM2도, HBM3도, HBM3E도 모두 1024입니다.
핀 속도는 2.4 → 6.4 → 9.6 Gbps로 올랐지만 폭은 그대로였습니다.
2026년, 처음으로 폭이 두 배가 됩니다. HBM4는 2048-bit입니다.
13년 만의 변화입니다.
왜 13년이나 1024를 유지했고, 왜 지금 2048인가? 답은 인터포저입니다.
HBM 다이와 GPU 다이는 인터포저라는 실리콘 다리 위에서 만나는데, 그 다리에 깔린 배선 밀도가 HBM 폭을 결정합니다. 1024-bit가 한동안 인터포저·μbump 피치가 안정적으로 받쳐주는 최대치였습니다.
HBM4부터는 μbump 피치가 40μm에서 25μm 이하로 좁혀지고, 인터포저 위에 더 많은 배선이 깔립니다.
그래서 2048이 가능해진 것입니다.
단순히 "두 배"가 아니라, 13년 동안 쌓인 패키징 공정의 임계점이 한 번 풀린 전환점입니다.
그런데 더 큰 변화는 폭이 아니라 Base die에서 일어났습니다.
2. 세대별 스펙표 — HBM2 → HBM3 → HBM3E → HBM4
먼저 숫자로 봅니다. 표 한 장이 흐름을 가장 잘 보여줍니다.
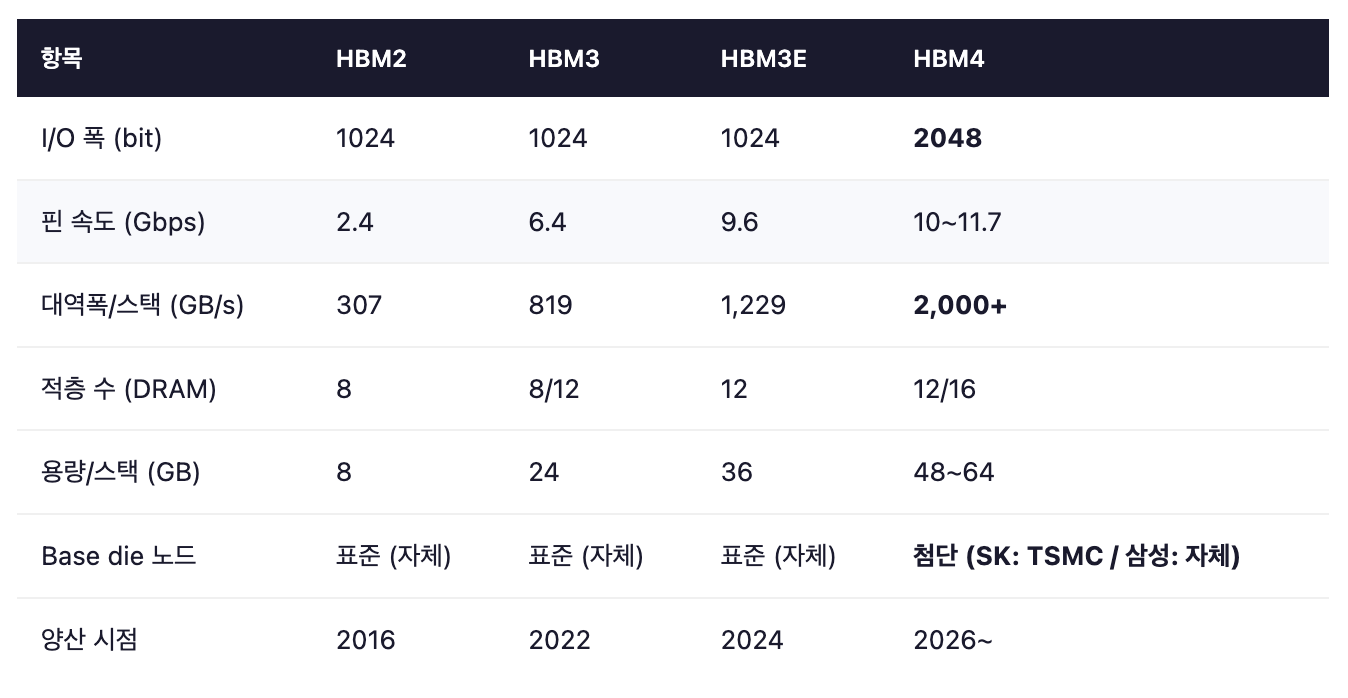
세대별로 핀 속도는 꾸준히 올랐습니다. 하지만 진짜 변곡점은 두 곳입니다.
I/O 폭 2배 — 13년 만의 변화. 대역폭이 단숨에 1.6~2배
Base die 로직화 — 13년 만의 변화. 메모리·로직 경계가 흐려짐
이 두 변화가 무엇을, 왜, 어떻게 바꾸는지를 봅니다.
3. HBM4 4대 변화 — 왜 진입 장벽이 한 단계 더 높아지는가
HBM3E vs HBM4 — 4대 변화 한 눈에 보기
3.1 I/O 폭 2배 — 13년 만의 변화
1024 → 2048 bit. 단순히 숫자가 두 배인 게 아닙니다. 인터포저 위에 깔린 배선이 두 배, μbump 밀도가 두 배, TSV 정렬 난이도가 한 단계 더입니다. 1편의 장벽 ①·②·③이 모두 한 단계씩 올라간다는 의미입니다.
이 변화를 시각적으로 보려면 HBM 시스템 단면도가 가장 빠릅니다. GPU와 HBM이 어떻게 만나는지, μbump·TSV·인터포저가 어디에 위치하는지를 한 장에 정리합니다.
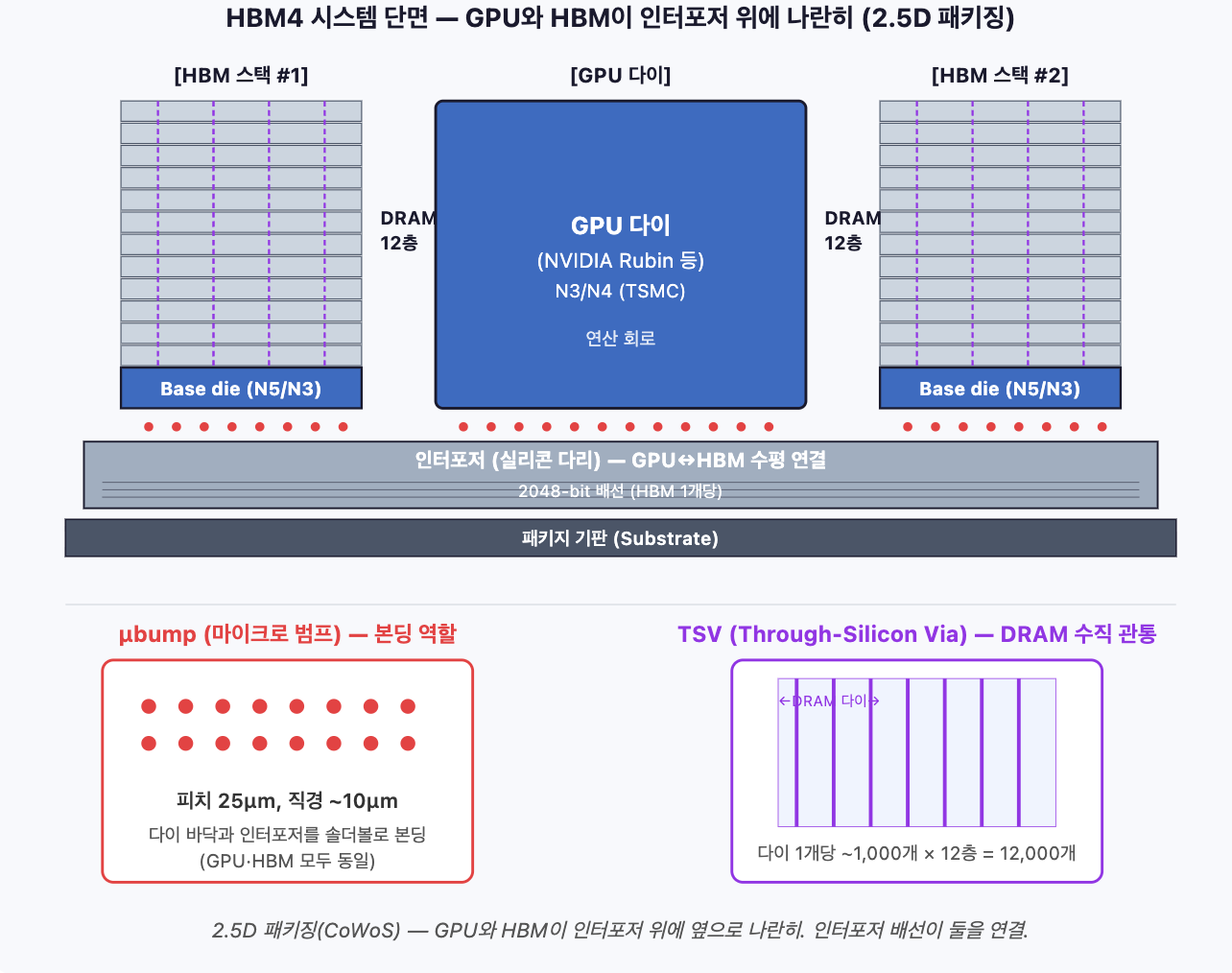
중요한 포인트: GPU와 HBM은 같은 인터포저 위에 옆으로 나란히 놓입니다. GPU가 HBM 위에 적층되는 게 아닙니다. 이게 2.5D 패키징 (CoWoS) 구조이며, HBM4까지 표준입니다. GPU가 HBM 위로 올라가는 본격 3D 적층은 아직 미래 기술입니다.
그림에서 핵심 구성 요소를 정리하면:
GPU 다이 — TSMC N3/N4 첨단 노드. 연산 담당. 인터포저 위에 놓임
HBM 스택 (좌/우) — DRAM 다이 12층 + Base die. GPU 양옆에 1~8개 놓임 (시스템에 따라 다름)
μbump (마이크로 범프) — 직경 ~10μm 솔더볼. 다이 바닥 ↔ 인터포저 사이를 본딩. GPU·HBM 모두 동일 방식. HBM3E 피치 40μm → HBM4 피치 25μm 이하로 좁혀짐
인터포저 — 모든 다이 아래에 깔린 실리콘 다리. 내부 배선이 GPU와 HBM을 수평으로 연결. HBM 1개당 2048-bit 배선 (HBM3E는 1024-bit)
TSV (Through-Silicon Via) — DRAM 다이를 수직으로 관통하는 비아 (HBM 스택 내부에만). 다이 1개당 약 1,000개 × 12층 = 12,000개. ±1μm 정렬 정확도 필요
Base die — HBM 스택 맨 아래. HBM4부터 TSMC N5/N3 첨단 노드 (SK 위탁) 또는 자체 파운드리 (삼성)
잠깐 — 이 구조의 이름이 "CoWoS"입니다
CoWoS = Chip-on-Wafer-on-Substrate (TSMC의 2.5D 패키징 브랜드명).
① CoW (Chip-on-Wafer) — GPU·HBM 다이들이 인터포저(실리콘 웨이퍼) 위에 올라감.
② oS (on-Substrate) — 그 인터포저가 다시 패키지 기판(Substrate) 위에 올라감.
전체 적층 순서:
다이(GPU·HBM) → μbump → 인터포저 → C4 bump → 패키지 기판 → BGA 솔더볼 → PCB(메인보드)
본드 종류는 위로 갈수록 작고 촘촘, 아래로 갈수록 크고 성김:
・μbump (다이 ↔ 인터포저) — 직경 ~10μm, 피치 25μm. 신호 밀도 극대화
・C4 bump (인터포저 ↔ 기판) — 직경 ~80~100μm. 인터포저 고정·전력 공급
・BGA 솔더볼 (기판 ↔ PCB) — ...