Semianalysis-AI Datacenter Energy Dilemma - Race for AI Datacenter Space(3월 14, 2024)
원문:AI Datacenter Energy Dilemma - Race for AI Datacenter Space (semianalysis.com)
chatGPT를 이용해 번역하였습니다.
(해당 글은 데이터센터 2편 쓰는 과정에 많은 도움이 되고 있습니다.... 최대한 빨리 작성해놓겠습니다. 그리고 데이터센터 1편 업데이트 해놓았습니다. 또한 BofA 레포트도 하나 아무도 모르게 올려놓았습니다(본래 남들이 공개한 자료들 또는 무료 자료들을 가져와 글을 작성하는데, 구글링하여 찾은 BofA 레포트 본문이 있어 레포트 데이터만 올리는 식으로 작성하다가 다시 확인해보니, 구글링해서 얻은 사이트가 없어졌더라고요.. 그러다보니, 이게 레포트전문을 비롯해, 데이터들을 공유를 하는 것이 불법일지도 모르겠다라는 생각에 일단은 펠로우 공개 형식으로 올려놓았습니다만, 문제가 될 것 같으면 아마 비공개로 내릴 생각을 가지고 있습니다. ))
AI Datacenter Energy Dilemma - Race for AI Datacenter Space
Gigawatt Dreams and Matroyshka Brains Limited By Datacenters Not Chips
AI 클러스터 수요의 폭발적인 증가로 인해 데이터 센터 용량에 대한 관심이 급증하고 있으며, 특히 전력망, 발전 용량, 환경에 극심한 부담을 주고 있습니다. AI 구축은 데이터 센터 용량 부족으로 크게 제한을 받고 있는데, 특히 GPU는 고속 칩 간 네트워킹을 위해 동일 위치에 배치되어야 하기 때문입니다. 또한 추론 모델의 배포도 여러 지역에서의 총 용량 부족과 더 나은 모델이 시장에 출시됨에 따라 크게 제한되고 있습니다.
이제 병목 현상이 어디에서 발생할 것인가에 대한 많은 논의가 이뤄지고 있습니다. 추가 전력 수요는 얼마나 큰가? GPU는 어디에 배치되고 있는가? 데이터 센터 건설이 북미, 일본, 대만, 싱가포르, 말레이시아, 한국, 중국, 인도네시아, 카타르, 사우디아라비아, 쿠웨이트 등 지역별로 어떻게 진행되고 있는가? 가속기 성장이 언제 물리적 인프라에 의해 제약을 받게 될까? 그것이 변압기, 발전기, 전력망 용량일까 아니면 우리가 추적하는 15개 이상의 데이터 센터 구성 요소 중 하나일까? 필요한 자본 지출(Capex)은 얼마나 될까? 어떤 하이퍼스케일러와 대형 기업들이 충분한 용량 확보를 위해 경쟁하고 있으며, 어떤 기업들이 데이터 센터 용량 부족으로 인해 심각한 제약을 받게 될까? 향후 몇 년 동안 기가와트 단위 이상의 트레이닝 클러스터가 어디에 건설될 것인가? 천연가스, 태양광, 풍력 등 발전 유형의 비율은 어떻게 될까? 이러한 AI 구축이 지속 가능한가, 아니면 환경을 파괴할 것인가?
오늘은 이 질문들에 대해 답을 해보려 합니다. 보고서의 첫 번째 절반은 무료로 제공되며, 두 번째 절반은 아래에서 구독자들에게만 제공됩니다.
많은 사람들이 데이터 센터 구축 속도에 대해 터무니없는 가정을 내놓고 있습니다, 심지어 일론 머스크도 의견을 제시했지만, 그의 평가는 완전히 정확하지 않아요.
인공지능 컴퓨팅이 온라인으로 도입되면서 매 6개월마다 10배씩 증가하는 것으로 보입니다... 그리고 다음 부족 사태는 전압 강하 변압기에서 발생할 것이라는 예측이 매우 쉬웠습니다. 이러한 시스템들에 전력을 공급해야 하니까요. 100~300킬로볼트의 전력이 전력회사를 통해 들어오면 이를 6볼트로 낮춰야 하는데, 그 과정은 상당한 전압 강하가 필요합니다. 제가 그리 재미있지 않은 농담으로 "트랜스포머(Transformers)를 작동시키려면 트랜스포머(변압기)가 필요하다"고 한 이유입니다... 그다음에는 전력 부족 사태가 올 겁니다. 모든 칩을 돌리기 위한 전력을 충분히 확보하지 못할 것입니다. 내년에는 칩을 구동할 전력을 찾을 수 없는 상황을 보게 될 것입니다.
Bosch Connected World Conference에서
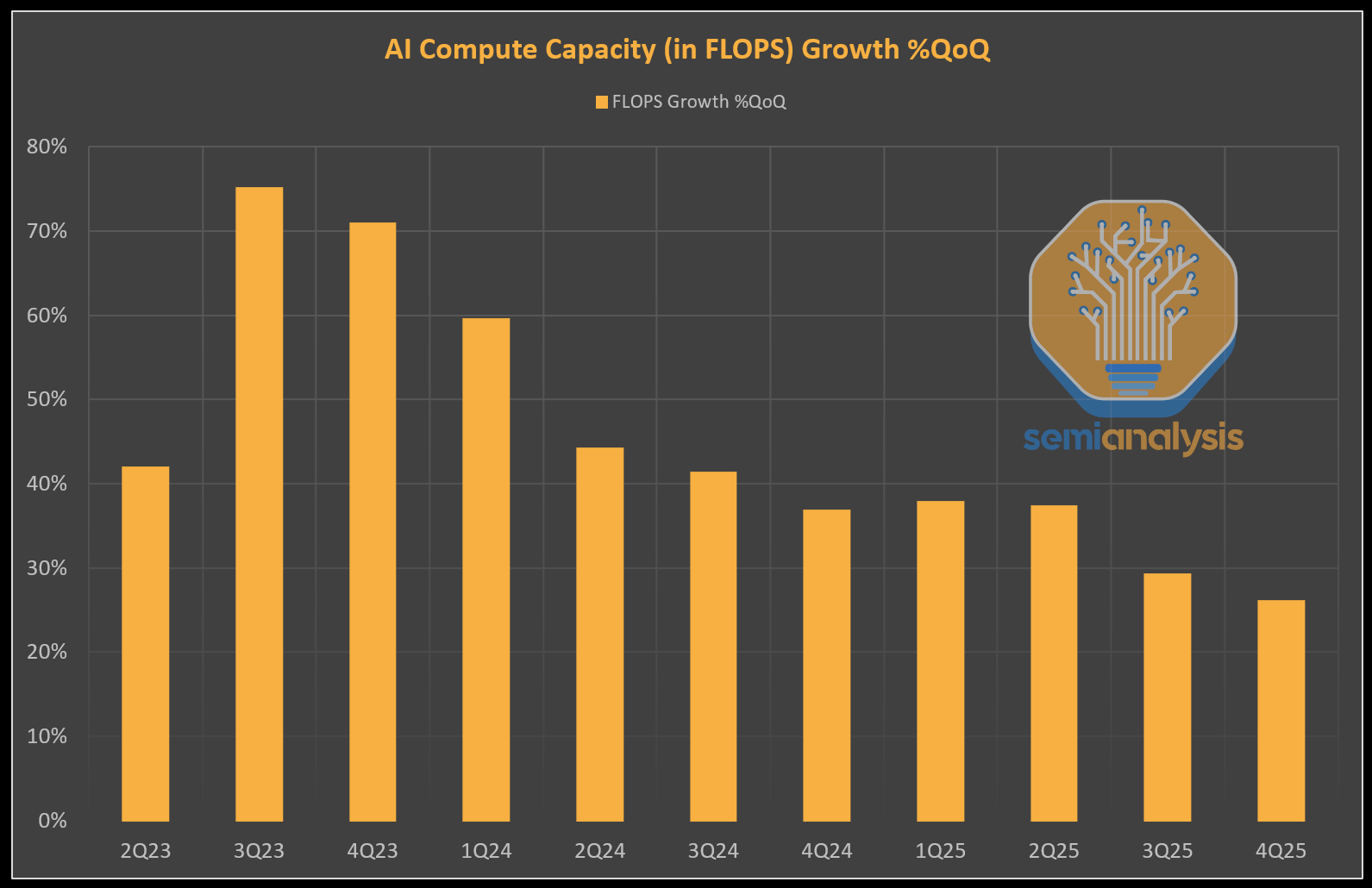
명확히 말하자면, 물리적 인프라의 한계에 대한 그의 지적은 대부분 옳습니다. 하지만 컴퓨팅 성능이 매 6개월마다 10배 증가하는 것은 사실이 아닙니다. 우리는 주요 하이퍼스케일러와 상업용 실리콘 기업들의 CoWoS, HBM, 서버 공급망을 추적하고 있으며, 2023년 1분기부터 현재까지 AI 컴퓨팅 용량은 이론적인 최대 FP8 FLOPS 기준으로 분기별 50~60%의 빠른 속도로 증가하고 있습니다. 즉, 6개월에 10배 성장과는 거리가 멉니다. CoWoS와 HBM의 성장 속도는 단순히 그렇게 빠르지 않기 때문입니다.
생성형 AI의 붐은 트랜스포머(Transformers)로 구동되며, 실제로 많은 변압기, 발전기, 그리고 다양한 전기 및 냉각 장치들이 필요하게 될 것입니다.
많은 경우, 간이 계산이나 지나치게 경고적인 이야기들은 오래된 연구에 근거하고 있습니다. IEA(국제에너지기구)의 최근 보고서 "Electricity 2024"에 따르면, 2026년까지 AI 데이터 센터에서 90 테라와트시(TWh)의 전력 수요가 발생할 것으로 예상되며, 이는 약 10 기가와트(GW)의 데이터 센터 핵심 IT 전력 용량에 해당하며, H100 GPU 730만 대에 해당하는 전력 소모량과 비슷합니다. 우리의 추정에 따르면, Nvidia는 2021년부터 2024년 말까지 H100을 포함해 H100과 유사한 전력 요구를 가진 가속기를 500만 대 이상 출하할 것으로 예상되며, AI 데이터 센터의 전력 수요는 2025년 초에 10GW를 넘길 것으로 보입니다.
위 보고서는 데이터 센터 전력 수요를 과소평가한 측면이 있지만, 그와 반대로 지나치게 과장된 예측도 많습니다. 특히, 일부 경고적인 주장은 가속 컴퓨팅이 널리 채택되기 전 작성된 오래된 연구를 인용하여, 데이터 센터가 2030년까지 7,933 테라와트시(TWh), 즉 전 세계 전력 생산의 24%를 소비할 것이라는 최악의 시나리오를 재활용하고 있습니다!
이런 이야기 속에서는 마치 데이터 센터가 메뚜기 떼, 다이슨 구체, 마트료시카 브레인처럼 끝없이 전력을 삼킬 것이라는 비유가 등장합니다!
많은 이러한 간이 계산 추정치는 전 세계 인터넷 프로토콜 트래픽 성장 예측에 기반하고, 단위 트래픽당 사용되는 전력에 대한 예측은 효율성 향상에 의해 조정됩니다. 하지만 이러한 모든 수치는 추정하기 매우 어려우며, 일부는 AI 도입 이전에 만들어진 데이터 센터 전력 소비 추정을 사용합니다. 맥킨지(McKinsey)의 추정치 또한 웃음을 자아낼 정도로 부정확하며, 단순히 무작위 CAGR을 선택하고 이를 멋진 그래픽으로 반복하는 수준입니다.
이제는 이러한 잘못된 서사를 바로잡고, 데이터 센터 전력 부족 문제를 실증적 데이터를 통해 정량화해봅시다.
우리의 접근법은 기존 콜로케이션 및 하이퍼스케일 데이터 센터를 포함한 북미에 있는 3,500개 이상의 데이터 센터를 분석하여 AI 데이터 센터의 수요와 공급을 예측합니다. 여기에는 개발 중인 데이터센터의 건설 진행률 예측이 포함되며, 이 연구 유형으로는 처음으로 우리의 AI 가속기 모델에서 파생된 AI 가속기 전력 수요를 데이터베이스와 결합하여 AI 및 비-AI 데이터 센터의 핵심 IT 전력 수요와 공급을 추정합니다. 또한, Structure Research가 수집한 북미 외 지역(아시아 태평양, 중국, EMEA, 라틴 아메리카)에 대한 지역별 추정치와 이 분석을 결합하여 전 세계 데이터 센터 트렌드에 대한 전체적인 시각을 제공합니다. 말레이시아 조호르바루의 최대 1,000MW 규모의 개발 계획(주로 중국 기업에 의해)과 같이 주목할만한 개별 클러스터와 건설 진행 상황을 위성 이미지를 통해 추적하는 방식으로 지역별 추정치를 보완합니다.
우리는 이러한 추적을 하이퍼스케일러별로 진행하며, AI 분야에서 가장 큰 플레이어들 중 일부가 중기적으로는 다른 기업들보다 배포 가능한 AI 컴퓨팅에서 뒤처질 것이라는 점이 명확합니다.
AI 붐은 데이터 센터의 전력 소비 성장률을 빠르게 가속화할 것이 분명하지만, 전 세계 데이터 센터 전력 사용량은 단기적으로 전체 에너지 생산량의 24%라는 종말론적 시나리오보다 훨씬 낮은 수준을 유지할 것입니다. 우리는 2030년까지 데이터 센터가 전 세계 에너지 생산량의 4.5%를 사용할 것으로 보고 있습니다.
The Real AI Superpowers
데이터 센터의 전력 용량 성장률은 향후 몇 년 동안 연평균 성장률(CAGR) 12-15%에서 25%로 가속화될 것입니다. 전 세계 데이터 센터 핵심 IT 전력 수요는 2023년 49 기가와트(GW)에서 2026년까지 96 GW로 급증할 것이며, 이 중 약 40 GW는 AI가 소비할 것입니다. 하지만 실제로는 이 성장 과정이 그렇게 순탄하지 않으며, 곧 심각한 전력 부족 사태가 다가올 것입니다.
AI 데이터 센터의 수요 급증을 충족하기 위해서는 풍부하고 저렴한 전력, 전력망 용량의 신속한 확장, 그리고 하이퍼스케일러의 탄소 배출 목표를 동시에 달성할 필요가 있습니다. 여기에 칩 수출 제한까지 겹치면서, 이러한 수요를 충족할 수 있는 지역과 국가가 제한될 것입니다.
미국과 같은 일부 국가 및 지역은 낮은 전력망 탄소 집약도, 저렴하고 안정적인 연료 공급원 덕분에 유연하게 대응할 수 있을 것입니다. 반면, 유럽은 지정학적 현실과 전력에 대한 구조적 규제 제약으로 인해 사실상 손발이 묶일 것입니다. 또 다른 국가들은 환경 영향을 고려하지 않고 단순히 용량을 확장하는 방향으로 나아갈 것입니다.
Key Needs of Training and Inference
AI 학습(Training) 워크로드는 기존 데이터 센터에 배치된 전형적인 하드웨어와 매우 다른 고유한 요구 사항을 가지고 있습니다.
첫째, 모델 학습(train)은 몇 주 또는 몇 달 동안 진행되며, 네트워크 연결 요구 사항은 학습 데이터의 입력에 국한되어 상대적으로 제한적입니다. AI 학습(Training)은 지연 시간(latency)에 민감하지 않으며 주요 인구 밀집 지역 근처에 위치할 필요가 없습니다. 따라서 AI 학습 클러스터는 데이터 거주성 및 규정 준수만 충족하면 전 세계 어디에서든 경제적으로 합리적인 장소에 배치될 수 있습니다.
두 번째로 중요한 차이는 다소 명백한데, AI 학습 워크로드는 엄청난 전력을 소모하며, 전통적인 비가속 하이퍼스케일 또는 엔터프라이즈 워크로드보다 AI 하드웨어가 열 설계 전력(TDP)에 가까운 전력 수준에서 실행되는 경향이 있습니다. 또한, CPU와 스토리지 서버는 1kW 수준의 전력을 소비하지만, 각 AI 서버는 이제 10kW를 초과하고 있습니다. 지연 시간에 덜 민감하고 인구 밀집 지역 근처에 있을 필요가 적기 때문에, 저렴하고 풍부한 전력(그리고 향후에는 어떤 전력망에도 접근 가능성)이 AI 학습 워크로드에서는 전통적인 워크로드보다 훨씬 더 중요한 요소로 작용합니다. 흥미롭게도, 이러한 요구 사항 중 일부는 무의미한 암호화폐 채굴 작업과 공유되지만, 암호화폐 채굴은 단일 사이트에서 100메가와트를 초과하는 확장 이점이 없다는 점에서 차이가 있습니다.
반면, 추론(Inference)은 결국 학습보다 더 큰 워크로드를 처리하지만, 분산될 수 있는 특성을 가지고 있습니다. 칩들이 중앙 집중화될 필요는 없지만, 칩의 sheer 양(부피) 자체는 매우 클 것입니다.
Datacenter Math
AI 가속기의 전력 사용률은 비교적 높게 유지됩니다(전력 사용 측면에서, MFU가 아닌). DGX H100 서버의 정상 작동 시 예상되는 평균 전력(EAP)은 약 10,200W이며, 이는 서버당 8개의 GPU 각각에 대해 1,275W로 환산됩니다. 이 수치는 H100 자체의 700W 열 설계 전력(TDP)과 더불어, Dual Intel Xeon Platinum 8480C 프로세서, 2TB의 DDR5 메모리, NVSwitches, NVLink, NICs, 리타이머, 네트워크 트랜시버 등에 GPU당 약 575W가 할당된 값을 포함합니다. 스토리지 및 관리 서버, 다양한 네트워킹 스위치 등을 포함한 전체 SuperPOD의 전력 요구 사항을 추가하면 DGX 서버당 11,112W 또는 H100 GPU당 1,389W의 전력 소모가 발생합니다. DGX H100 구성은 스토리지와 기타 항목 측면에서 HGX H100에 비해 다소 과도하게 제공된 측면이 있으며(overprovisioned), 이를 반영한 계산입니다. Meta와 같은 기업들은 전체 구성에 대한 충분한 정보를 공개하여 시스템 레벨에서의 전력 소비를 추정할 수 있도록 했습니다.
Critical IT Power는 데이터 센터 내에서 서버 랙에 배치된 컴퓨팅, 서버, 네트워킹 장비가 사용할 수 있는 전기 용량을 의미합니다. 여기에는 냉각, 전력 공급, 기타 시설 관련 시스템을 운영하는 데 필요한 전력은 포함되지 않습니다. 이 예시에서 필요한 Critical IT Power 용량을 계산하려면 배치된 IT 장비의 총 예상 전력 부하를 합산해야 합니다. 예를 들어, 1,389W의 전력을 소비하는 20,480개의 GPU는 28.4 MW의 Critical IT ...