
1.서론
CES 2026에서 공개된 엔비디아와 메르세데스-벤츠의 협력 프로젝트인 ‘Alpamayo(알파마요)’에 관한 정리 내용입니다. 많은 미디어에서 지난 10여 년간 자율주행 산업이 봉착했던 한계를 돌파하기 위해 “AI가 텍스트와 이미지를 넘어 물리 세계(Physical World)를 이해하고 행동하는 단계”로 진입했음을 알리는 신호탄 이라고 합니다.

엔비디아(NVIDIA). (2026. 1. 5.). 「NVIDIA Announces Alpamayo Family of Open-Source AI Models and Tools to Accelerate Safe, Reasoning-Based Autonomous Vehicle Development」(보도자료). NVIDIA Newsroom. https://nvidianews.nvidia.com/news/alpamayo-autonomous-vehicle-development
업계 전문가들과 기술 분석에 따르면, 이번 발표의 핵심 의의는 단순한 자율주행 기능의 추가가 아니라, 개발 방법론 자체의 혁신에 있다고 합니다.
기존의 자율주행이 미리 정해진 규칙(Rule-based)이나 단순한 패턴 매칭에 의존했다면, Alpamayo는 인간처럼 상황을 언어로 ‘추론(Reasoning)’하고, 그에 맞춰 ‘행동(Action)’하는 새로운 표준을 제시하고 있습니다.
엔비디아의 젠슨 황 CEO가 이를 두고 “물리적 AI의 챗GPT 모멘트”라고 정의한 것은, 생성형 AI의 파급력이 이제 모니터 속을 벗어나 실제 도로 위를 달리는 거대한 기계 장치로 확장되었음을 의미합니다.
제가 이 분야에 정통한 식견을 갖춘 전문가는 아니오나, 평소 자동차 산업의 기술적 진보에 대해 관심을 기울여 온 한 사람으로서, 그저 이번 혁신이 가지는 의미를 조금 더 깊이 있게 탐구해보고자 합니다.
2. Alpamayo의 기술적 본질: VLA와 CoT의 결합
이 시스템을 이해하기 위해서는 기존 자율주행의 한계와 이를 극복하기 위한 새로운 아키텍처인 VLA(Vision-Language-Action) 모델, 그리고 CoT(Chain-of-Thought) 기술을 간단히 이해하여 함.
2.1 기존 ‘모듈식’ 접근의 한계와 붕괴
과거의 자율주행 시스템은 철저히 분업화된 모듈식 구조였음.
인지(Perception): 카메라가 "앞에 있는 물체는 사람이다"라고 식별함.
측위(Localization): GPS와 정밀지도로 "내 차는 현재 A도로 3차선에 있다"고 확인함.
예측(Prediction): "저 사람은 3초 뒤에 횡단보도로 진입할 것이다"라고 계산함.
제어(Control): "그러므로 브레이크를 밟아라"라고 명령함.
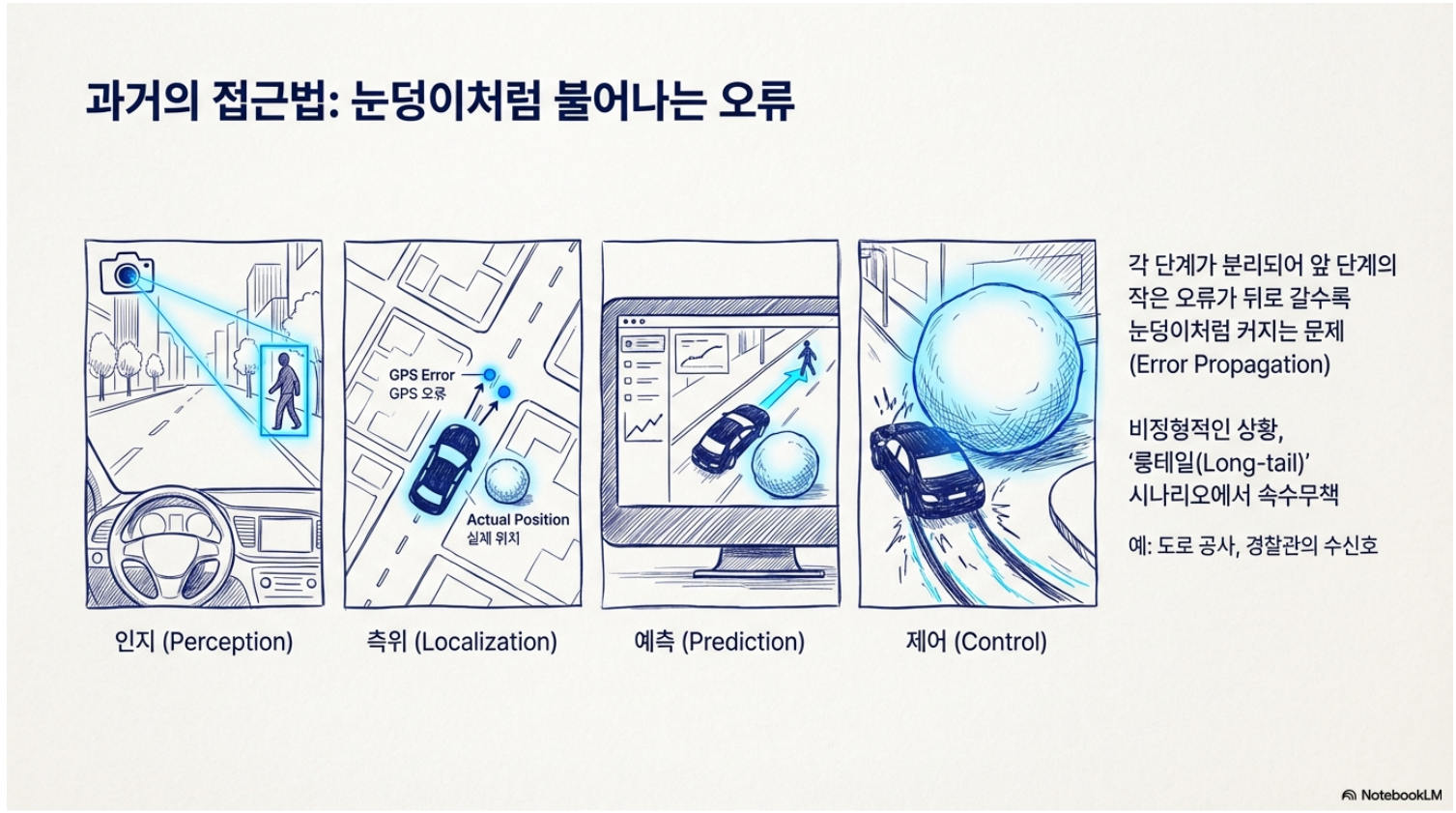
이 방식은 고속도로처럼 변수가 적은 환경에서는 잘 작동함. 그러나 각 단계가 분리되어 있어 앞 단계의 작은 오류가 뒤로 갈수록 눈덩이처럼 커지는(Error Propagation) 문제가 발생함. 특히 비정형적인 상황, 이른바 ‘롱테일(Long-tail)’ 시나리오에서 이 방식은 속수무책이었음. 예를 들어, 도로 공사로 차선이 지그재그로 엉켜 있거나, 수신호를 하는 경찰관의 손짓 같은 미묘한 상황을 규칙으로 다 정의할 수 없기 때문임.
2.2 VLA: 보고, 이해하고, 즉시 행동한다
Alpamayo는 이러한 모듈의 장벽을 허물고 엔드투엔드(End-to-End) 방식을 채택함. 여기서 핵심이 VLA(Vision-Language-Action)임.
Vision: 시각 데이터를 받아들임.
Language: 그 상황을 언어적 맥락으로 해석함.
Action: 해석된 내용을 바탕으로 즉각적인 주행 궤적(Trajectory)을 생성함.
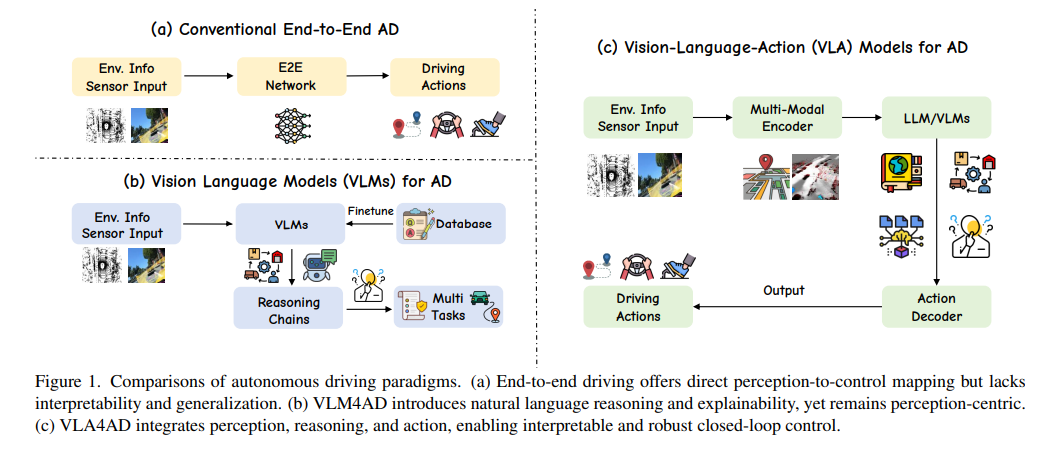
설명 : 그림은 "무조건 따라 하기(a)"에서 "말로만 이해하기(b)"를 거쳐, "이해한 대로 직접 운전하기(c)"로 기술이 완성되는 과정을 보여주는 것. 엔비디아의 Alpamayo는 바로 이 (c) 단계에 해당. (출처 : NVIDIA & Mercedes-Benz. (2026). Alpamayo: A Vision-Language-Action (VLA) Model for Autonomous Driving. NVIDIA Technical Report.)
최근 공개된 연구 논문(Alpamayo-R1 등)에 따르면, 이 모델은 단순한 모방 학습(Imitation Learning)을 넘어섬. 과거의 엔드투엔드 모델이 "사람이 여기서 핸들을 꺾었으니 나도 꺾는다"는 식으로 데이터의 겉모습만 흉내 냈다면, VLA 모델은 "왜 꺾어야 하는지"를 이해하는 구조임. 이는 자율주행뿐만 아니라 로봇, 드론 등 다양한 물리 AI 분야로 확장될 수 있는 강력한 기술적 기반이 됨.
2.3 CoT: AI가 내놓는 ‘생각의 꼬리 물기’
Alpamayo의 가장 큰 차별점은 CoT(Chain-of-Thought) 기술의 적용임. 이는 AI가 결론만 내는 것이 아니라, 결론에 도달하는 논리적 과정을 텍스트로 생성하는 기술임.
기존 AI: (전방 장애물 감지) → [급제동 수행] (이유 설명 없음)
Alpamayo:
"전방 30m 지점 갓길에 어린이가 서 있음."
"어린이의 시선이 도로 반대편을 향하고 있어 갑자기 튀어나올 가능성이 높음."
"현재 속도 50km/h는 위험하므로 30km/h로 사전 감속이 필요함."
"차량을 차선 왼쪽으로 붙여 안전거리를 확보하겠음."
[감속 및 조향 수행]
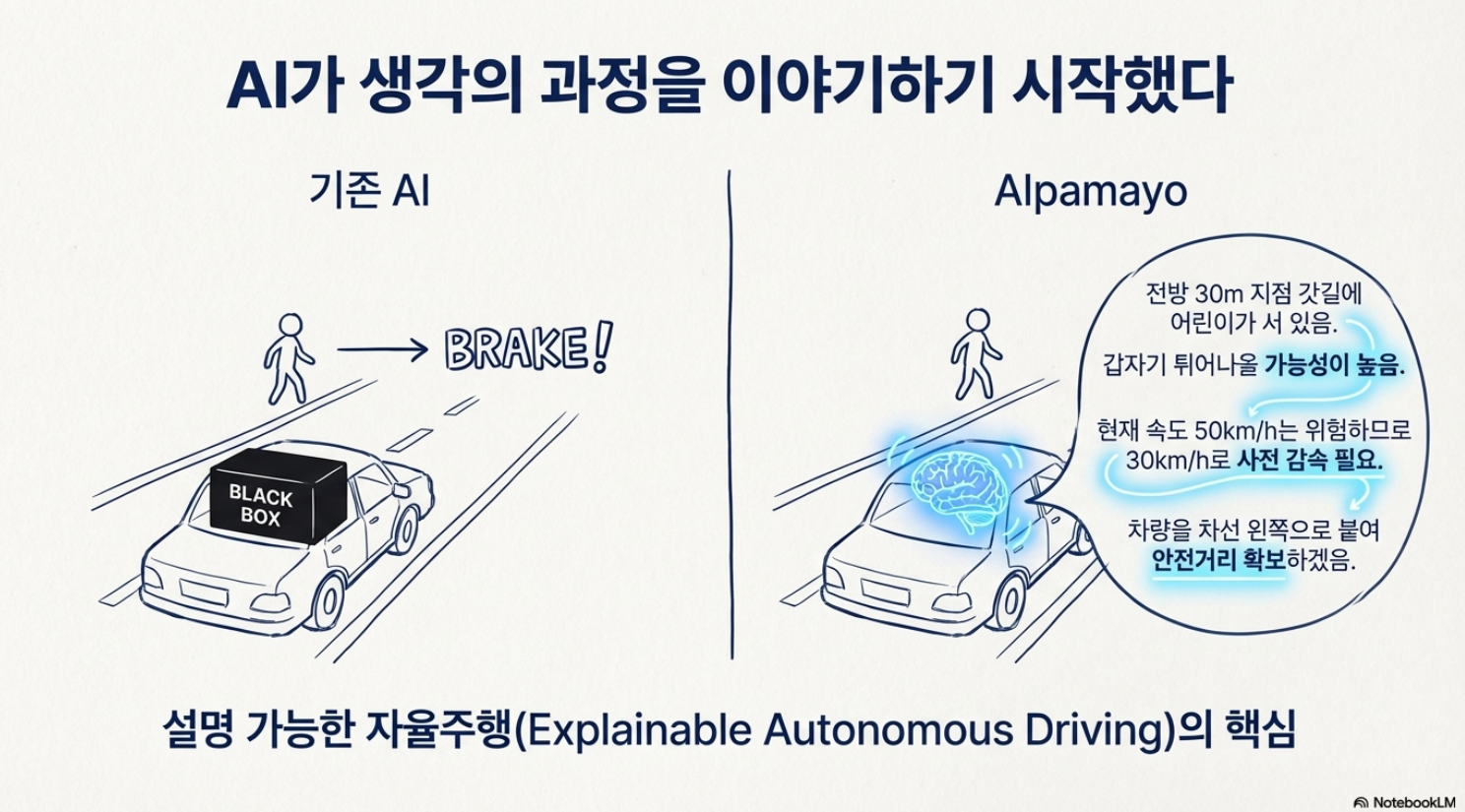
이러한 추론 과정의 노출은 연구 개발 관점에서 혁명적인 변화를 가져옴. 개발자들은 AI가 왜 실수를 했는지, 혹은 왜 잘했는지를 텍스트 로그를 통해 직관적으로 파악할 수 있게 됨. 엔비디아가 강조하는 "설명 가능한 자율주행(Explainable Autonomous Driving)"의 핵심이 바로 여기에 있음.

설명 : 이 표는 자율주행이 한 순간에 “무슨 결정을 했는지”를 사람도 AI도 같은 기준으로 기록하게 만드는 표준 메뉴판임.
운전 행동을 앞뒤(속도 결정)랑 좌우(차선/방향 결정) 두 축으로 나눔
각 주행 장면(클립)마다 종방향 1개 + 측면 1개를 정해진 목록에서 고르게 함
이렇게 하면 “감속했다/조심했다”처럼 사람마다 다른 표현이 아니라, 일관된 라벨(결정 의도)로 데이터가 쌓임
그 결과, CoC(인과 연쇄) 설명도 항상 같은 형태의 결론(결정 라벨)에 붙어서 정리 가능해짐
출처: Shi, T., Cheng, X., Lu, Z., & Niu, J. (2019). Driving decision and control ...



![중국 부동산 ‘완커(Vanke) 사태’ 해부 [1부 + 2부 합본]](https://post-image.valley.town/uA-ZCToaOQUqiLEszfoav.png)


