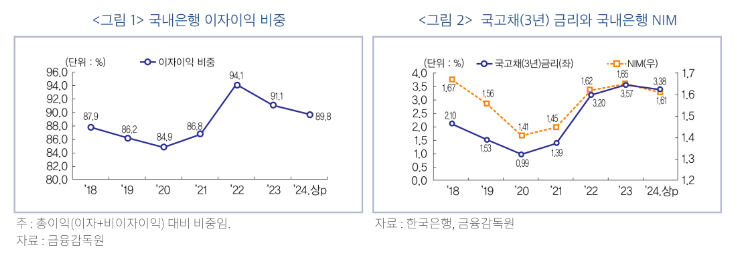
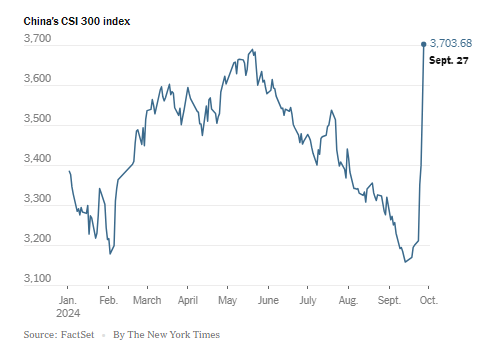
Introduction
NeuroFusion의 'AI 메가트렌드의 핵심, Nvidia 기업분석'을 읽던 중, 흥미로운 주제에 대해 언급한 부분을 발견했다. 기존에는 데이터의 양은 한정적이기 때문에 언젠가는 모든 데이터를 학습할 테고, 이후 기존 생성형 AI의 '증강'을 활용하여 데이터 부족 현상을 해결할 수 있지 않을까 기대했다.

그런데 Valley에서 언급한 논문에 따르면 LLM(대형 언어 모델) 학습에 있어 생성된 데이터가 모델 붕괴를 유발할 수 있다는 내용을 다루고 있었다. 이에 호기심이 생겨 논문을 읽어보기 시작했다. 논문의 제목은 'AI models collapse when trained on recursively generated data'이며 관심 있으실 분들을 위해 링크를 연결해 두겠다.
(필자는 전문가는 아니기에 쉬운 언어로 설명하고자 하며, 오류가 있음을 유의하길 바란다)

본론
What is model collapse?
우선 '모델 붕괴'의 정의를 살펴볼 필요가 있다.
Model collapse is a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation.
논문에서 설명하는 모델 붕괴란 생성형 모델(ex: LLM, Variational Autoencoder(VAE), Gaussian Mixture Model(GMM))이 점차 실제 데이터 분포를 반영하지 못하고, 왜곡된 결과를 도출하게 되는 과정을 의미한다. 쉽게 말해, 원본 데이터의 중요한 정보들을 잃어버리는 현상이라고 볼 수 있다.
이어서 모델 붕괴의 주요 특징을 아래 3가지로 정리한다.
Statistical approximation error : '통계적 근사 오류'. 샘플 수가 유한하기 때문에 발생하는 오류로 샘플이 무한히 많아지면 사라진다.
Functional expressivity error : '함수 표현의 오류'. 함수 근사치의 표현력이 제한되어 있기에 발생하는데 신경망 같은 함수 근사 기법은 크기가 무한대에 가까워져야 비로소 완벽한 근사를 할 수 있다.
Functional approximation error : '기능적 근사 오류'. 학습 절차의 한계로...