
Wong
구독자 22명구독중 4명
안녕하세요. 개발과 경제에 관심있는 ADAS 연구원입니다.
https://github.com/Wong-Woo
이론 정리는 다했는데, 수식때문에 포스팅 진도가 안나가네요.. 불가피하게 md로 올립니다.
# **기본 프로세스**
의사결정 트리는 자주 사용되는 머신러닝 학습법 중 하나이다. 이름 그대로 트리 구조에 기반하여 결정한다.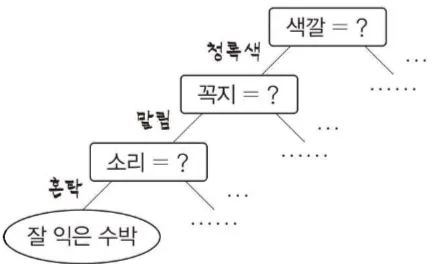
일반적으로 하나의 루트노드를 가지고, 여러개의 내부 노드와 여러개의 리프 노드를 가진다. 리프 노드는 결정 결과에 상응하고, 가타 다른 노드들은 하나의 속성 테스트를 구현한다. 샘플 집합은 루트노드에서 시작해 각 테스트 결과에 따라 하위 노드로 분류된다.
의사결정 트리의 학습 목표는 일반화 성능이 뒤어난 트리를 얻는 것이다. 기본적인 프로세스는 재귀적으로 간단하고 직관적인 분할 정복 전략을 기본으로 한다.
다음과 같은 속성집합 A를 갖는 훈련 세트 D로부터,
- 훈련 세트 $D = \{(\boldsymbol{x}_1, y_1), (\boldsymbol{x}_2, y_2), \dots, (\boldsymbol{x}_m, y_m)\}$
- 속성 집합 $A = \{a_1, a_2, \dots, a_d\}$
기본적인 의사결정트리 의사코드는 다음과 같다.
```
TreeGenerate(D, A)
1: node 생성
2: if $D$의 샘플이 모두 같은 클래스 $C$에 속하면 then
3: 해당 node를 레이블이 $C$인 터미널 노드로 정한다 return
4: end if
5: if $A = \emptyset \space or \space D$의 샘플이 $A$ 속성에 같은 값을 취한다면 then
6: 해당 node를 터미널 노드로 정하고, 해당 클래스는 $D$ 샘플 중 가장 많은 샘플의 수가 속한 속성으로 정한다 return
7: end if
8: $A$에서 최적의 분할 속성 $a_*$를 선택한다
9: for $a_*$의 각 값 $a_*^v$에 대해 다음을 행한다 do
10: node에서 하나의 가지를 생성한다. $D_v$는 $D$는 $a_*^v$ 속성값을 가지는 샘플의 하위 집합으로 표기한다
11: if $D_v$가 $\emptyset$ 이면 then
12: 해당 가지 node를 터미널 노드로 정하고, 해당 클래스는 $D$ 샘플 ...
![[BOOK] 단단한 머신러닝 2 (모델 평가 및 선택)](https://post-image.valley.town/c6B3hUaQEIxG0ZLjcuH32.png)
![[BOOK] 단단한 머신러닝 1](https://post-image.valley.town/o6fervRKUtMvkz2p-poIt.png)
![[BOOK] AFML 5](https://post-image.valley.town/V-KrfT5_g1JywwZiVq3nH.png)