기존 LLM에 대한 불만과 Cerefin AI에 대한 기대

911GT3RS
2025.07.30조회수 308회
911GT3RS
구독자 1,989명구독중 107명
Hybrid Theory
먼저 현재 공지사항에는 Valley AI의 첫 금융추론 엔진인 Cerefin AI의 개발 방향성 정립을 위한 설문조사가 진행중이므로 많은 참여 부탁드립니다.

설문조사에 답변을 쓰다가 문득 들었던 생각인데, 솔직히 요즘 LLM들의 딥 리서치 기능들이 많이 발전한 것은 체감하지만, 단순 정보 수집 및 취합을 넘어서서 실제 투자 의사결정에서 활용하기에는 아직 부족한 점이 많다고 느껴집니다. 그것이 제가 LLM 모델들에 대한 이해가 부족해서 드는 의문인지, 아니면 다른 분들도 동일하게 느끼시는 아쉬운 점인지 한번 의견을 듣고 싶기도 했었습니다.
나아가서 개인적으로 Cerefin AI가 정확히 어떤 방향성을 지향하는 지는 정확히 알 수 없지만, 앞으로 출시될 Cerefin AI라는 모델에 어떠한 기대를 하고 있는지? 어떻게 활용하고 싶은지?를 자세하게 적어보고 생각을 공유해보면, 개발하시는 분들 입장에서 조금이나마 수요파악에 도움이 되지 않을까 해서 글을 쓰게 되었습니다.
이런 막연한 생각이나 기대도 있구나 정도로 봐주시면 감사할 것 같습니다.
※ 내용이 많아 핵심정리만 하기 위해 평어체로 작성되었습니다.
기존 LLM모델에 금융시장과 관련된 분석, 예를 들면
오늘 날짜를 기준으로 지난 10년간의 금가격과 10년물 국채가격의 1년 롤링 상관관계(Rolling Correlation)를 분석해
라고 요청했을 때 가장 답답한 점은 "데이터 원본(Raw data)을 실제로 직접 수집해서" 분석하는 것이 아니라, 이미 과거에 분석되어 있는 뉴스기사나 학술자료를 긁어 모아서 그럴듯한 답변을 내놓는다는 점이었음
좀 더 구체적으로 ChatGPT와 Gemini, Perplexity Finance에 각각 다음과 같이 요청해보았음
지난 10년간의 금가격과 미국 10년물 국채 가격을 차트로 나타내. X축을 복사해서 Y축 스케일을 다르게 해서 패널1에 시각화해.
금가격과 10년물 국채가격의 1년 Rolling 상관관계를 분석하여 패널2에 시각화 해.
데이터는 가급적 기사나 학술자료에서 추출하지 않고, 자체 데이터나 외부 사이트에서 Raw data값들을 데이터로 불러와서 사용할 것
마지막에는 모든 데이터의 출처를 명시해.
위와 같이 LLM에 요청했을 때 내가 기대한 처리방식은 LLM이 코드 인터프리터를 이용해서
Api를 호출
금가격 종가 데이터를 다운로드
10년물 국채가격 데이터를 다운로드
1번과 2번의 데이터를 하나의 데이터프레임으로 결합 후 저장
합쳐진 데이터 프레임을 이용해서 상관관계 분석을 수행
Matplotlib와 같은 시각화 라이브러리를 이용해 그래프 시각화
1번 패널에는 금가격과 10년물 국채가격의 종가 (X축 복사하여 Y축을 좌우측으로 서로 다르게) line 차트 시각화
2번 패널에는 금가격과 10년물 국채가격의 252영업일의 Rolling 상관관계 line차트 시각화
이런식으로 알잘딱깔센으로 착착 분석을 수행하는 것이었다.
그런데, 이 요청을 각 ChatGPT 4.5와 Gemini 2.5 Pro에게 작업을 시키면
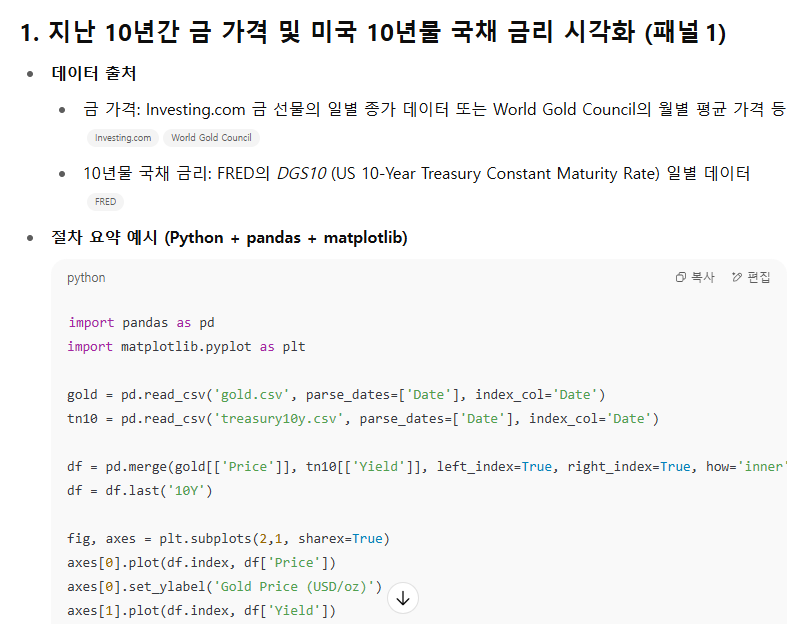
ChatGPT 4.5는 아래와 같이 코드만 뱉어내고, 하는 건 니가 직접하라는 식으로 답변한다.
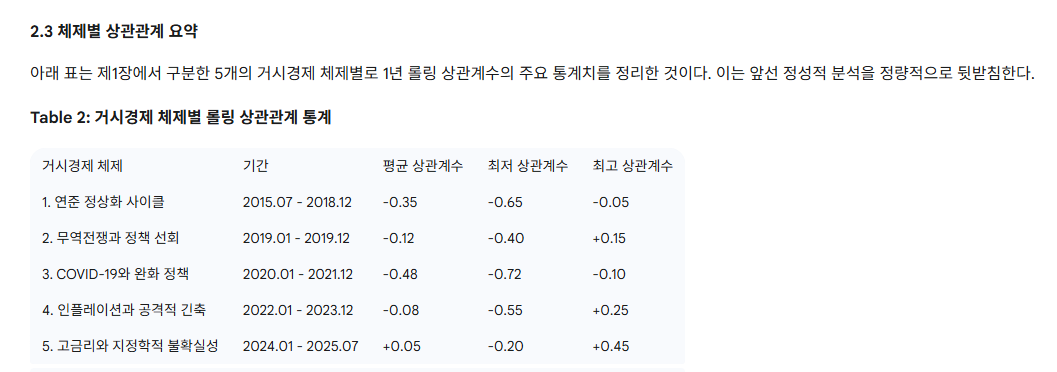
Gemini 2.5 Pro는 말은 그럴듯 하지만, 가장 중요한 시각화는 안하고 줄글로 분석결과만 요약해낸다.
이는 ChatGPT와 Gemini가 자체적으로 금가격과 10년물 국채의 가격데이터를 보유하고 있거나, API를 통해 직접 가져와서 분석을 수행하는 것이 아니라서 외부 사이트를 크롤링 해 온 데이터에 의존해야 하고, 만약 외부 사이트에서 종가데이터를 얻을 수 없을 경우 기존에 기사나 학술자료 등에서 연구한 텍스트자료를 바탕으로 그럴듯하게 말을 지어내기 때문인 것으로 추측됨
왜 그러한 추측을 하는가 하면, LLM의 작동방식에 대해서 Gemini에 질문을 한 적이 있었는데, Gemini는 아래와 같이 설명했었음
Q. 가령 사용자로부터 "역사상 주요 스태그플레이션 시기는 언제였으며, 각 시기별 원인, 지속 기간, 그리고 당시 S&P 500 지수와 금 가격의 월별 수익률은 어떠했는가?" 이런 질문을 받으면, LLM은 그때 당시의 기사나 학술자료를 기반으로 답변해? 아니면 각 자산군의 가격데이터를 기반으로 답변해?
질문의 요지는, 객관적 raw data 자체에 접근하는지 아니면 그걸 바탕으로 작성된 기사나 리서치 자료를 학습해서 답변하는지가 궁금한거야.
A. 네, 질문의 요지를 정확히 이해했습니다. LLM이 객관적인 원시 데이터(raw data)에 직접 접근하는지, 아니면 ...

저도 무심코 넘어갔던 불편했던 영역을 정말 잘 짚어주셔서 감탄했습니다. 세라핀이 이런 불편함을 해결한다면 정말 다른 LLM과 비교해서 압도적인 비교우위를 보여주리라 기대합니다.
맞습니다. 주인장님 말씀대로 금융 영역 한정이라면 승부처가 있지 않을까 조심스레 예상해봅니다!

좋은 글 감사드립니다. 저도 왜인지는 모르겠으나 LLM 기반 서비스를 이용할 때마다 참 험한 말이 나오게 된다는 생각이 듭니다. 분명 말을 했고 알아들었다고 했는데 딴소리하는 폐급을 상대하는 기분이 들어서일까요? 아무튼 정말 공감가는 내용이 많았고 NeuroFusion의 새로운 AI에게는 험한 말을 하지 않을 수 있다면 좋을 것 같다는 생각이 들었습니다(훌륭한 데이터 × 눈치껏 알아서 잘 ?= 훌륭한 AI). :)
진짜 잠시 군대에서 폐급후임을 상대로 화낼 수도 없고 일은 가르쳐야 하고 할 때의 그 답답한 느낌을 가끔 받습니다...

딸깍!
돈복사 딸깍!

ㅋㅋㅋㅋ 일단 너무 웃으면서 글을 읽었습니다. 많이 많이 동감하고 있어요. 하지만 저보다는 훨씬 더 깊이 있는 수준으로 AI와 대화하고 계셨군요. 저는 훨씬 낮은 수준으로 대화하면서도 울화통이 치민적이 많았고, 이런 류의 울화통 답변을 하는 질문의 성격을 파악하고 나서는 가급적 아예 그런 질문류를 피하기도 했습니다. ㅎㅎㅎ 살짝 포기한 거였죠. 한계를 극복하는 녀석들도 나올텐데, 그게 CereFin이었으면 좋겠습니다. ^^
저도 그게 세레핀이 된다면, Valley가 유니콘이 되는 하나의 초석이 될 거라고 믿습니다. 단순히 유니콘이 문제가 아닐수도...
너무 좋은 글! 공감 백배입니다 감사합니다.
저만 이런게 아니라는 위안을 많이 얻고 있습니다 ㅎㅎㅎ 감사합니다!