260311 MS - China AI GPUs – Closing the Gap with the US

콜드브루
2026.03.19조회수 95회
콜드브루
구독자 390명구독중 17명
리포트 정리해 두는 블로그입니다.
정보 습득에 있어 편식이 많은 편이니 양해 부탁드립니다.
64페이지짜리 리포트라 내용이 많습니다...
높은 AI 자본지출과 지속적인 정책 지원이 중국의 AI GPU 생태계를 촉진했다. 본 보고서에서는 해당 산업의 상업적 가치, 경쟁력, 그리고 향후 통합 경로를 평가하기 위한 프레임워크를 제시한다.
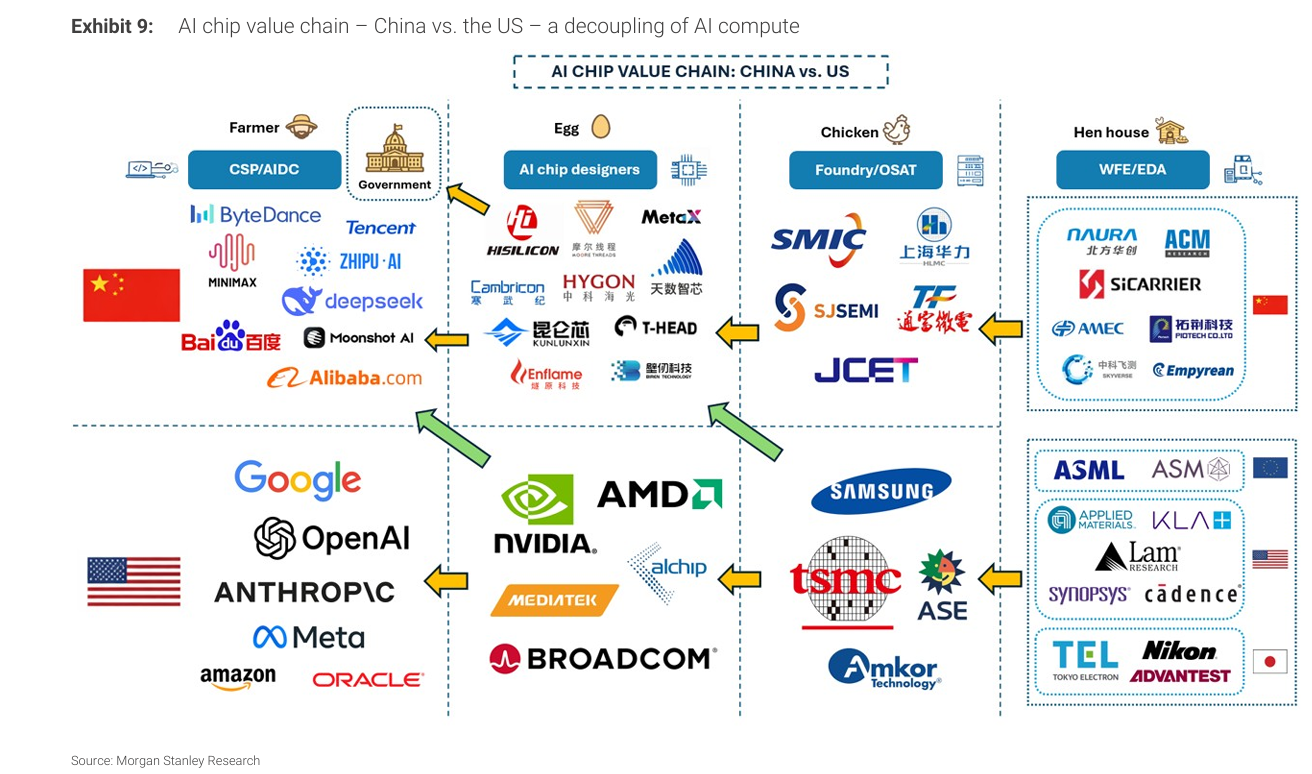
AI 기술의 빠른 확산은 중국 경제를 더 높은 질의 성장 모델로 전환시키고 있다. 우리는 지난해 “China – AI: The Sleeping Giant Awakens” 보고서를 통해 중국 AI의 현재 상태와 2030년 이후까지의 경로를 분석했다. 이번 보고서에서는 중국 AI 인프라의 핵심인 AI 칩에 집중하여, 수요 전망, 파운드리 공급 제약, 그리고 경쟁 환경을 분석한다.
중국 내 AI GPU 공급은 상당한 진전을 이루었다. 과거에는 중국의 AI 확산이 전력, 데이터, 인재 부족이 아니라 미국의 수출 규제로 인해 첨단 AI 칩 접근이 제한된 것이 가장 큰 제약이었다. 중국은 2020년부터 자체 AI GPU 개발을 시작했으며, 첨단 공정 접근이 제한된 상태였다. 2022년 이후 규제가 강화되며 이 창구는 사실상 닫혔지만 산업 성장은 멈추지 않았다. 지난 12개월 동안 중국은 장비 및 파운드리 병목을 완화하는 데 의미 있는 진전을 이루었다. 정책 지원 하에 2028년 전후로 핵심 수요를 충족할 수 있는 수준의 공급이 가능할 것으로 본다.
정책 지원은 초기 발전을 가속화하지만, 장기적인 가치는 상업적 경쟁력에 달려 있다. 중국 AI GPU 기업들은 2028년 이후에도 성장을 지속하기 위해 경제성을 입증해야 한다. 분석 결과, 중국 데이터센터의 총소유비용(TCO)은 낮은 칩 가격, 저렴한 전력, 개선된 인프라 덕분에 경쟁력이 있다. 특히 추론(inference)에서는 최고 성능보다 토큰당 비용이 중요하며, 이는 중국 솔루션의 경쟁력을 강화한다.
산업 및 투자 시사점: 중국의 로컬화 전략(칩, 파운드리, 장비 확대)은 계속 진전 중이다. 낙관적 시나리오에서는 중국 GPU가 학습 영역까지 확장되고 해외 채택도 가능하다. 비관적 시나리오에서는 차별화가 약화되어 commoditization과 통합이 진행된다. 직접적인 GPU 종목 추천은 하지 않지만, SMIC, NAURA, ASM Pacific과 같은 공급망 기업 및 AI 투자로 전략적 위치를 강화하는 인터넷 기업들에 대해 긍정적으로 본다.
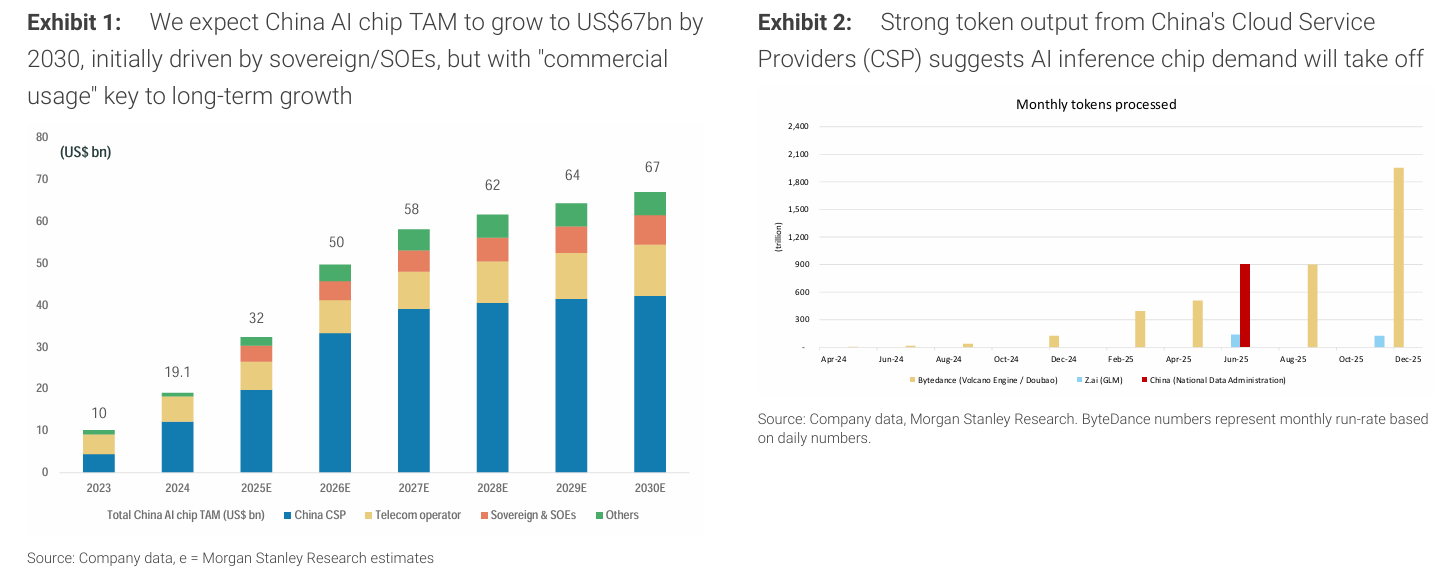
중국 AI 칩 시장은 2030년까지 약 670억 달러 규모로 성장할 것으로 예상되며, 초기에는 국유기업 중심이지만 장기적으로는 상업적 수요가 핵심이 된다.
중국 CSP들의 토큰 처리량 증가를 보면 AI 추론 칩 수요가 빠르게 증가할 가능성이 높다.
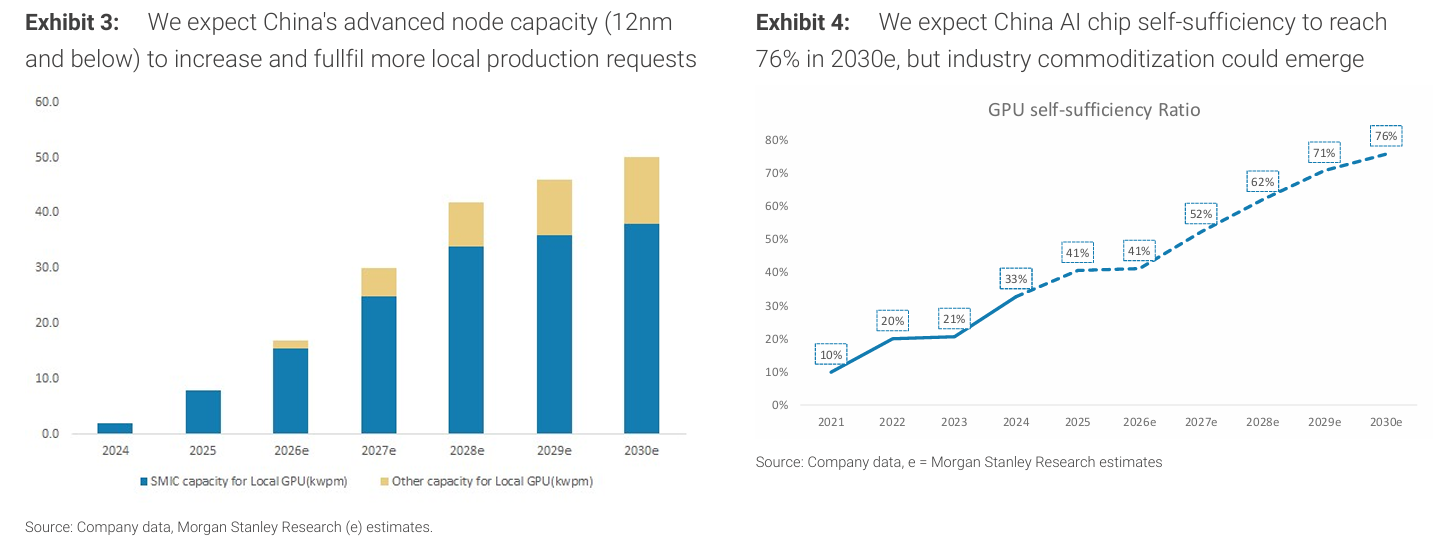
중국의 첨단 공정(12nm 이하) 생산 능력은 지속적으로 확대되며 로컬 생산 수요를 더 많이 충족할 것으로 예상된다.
AI 칩 자급률은 2030년 76%까지 상승할 전망이다. 다만 산업의 commoditization 가능성도 존재한다.
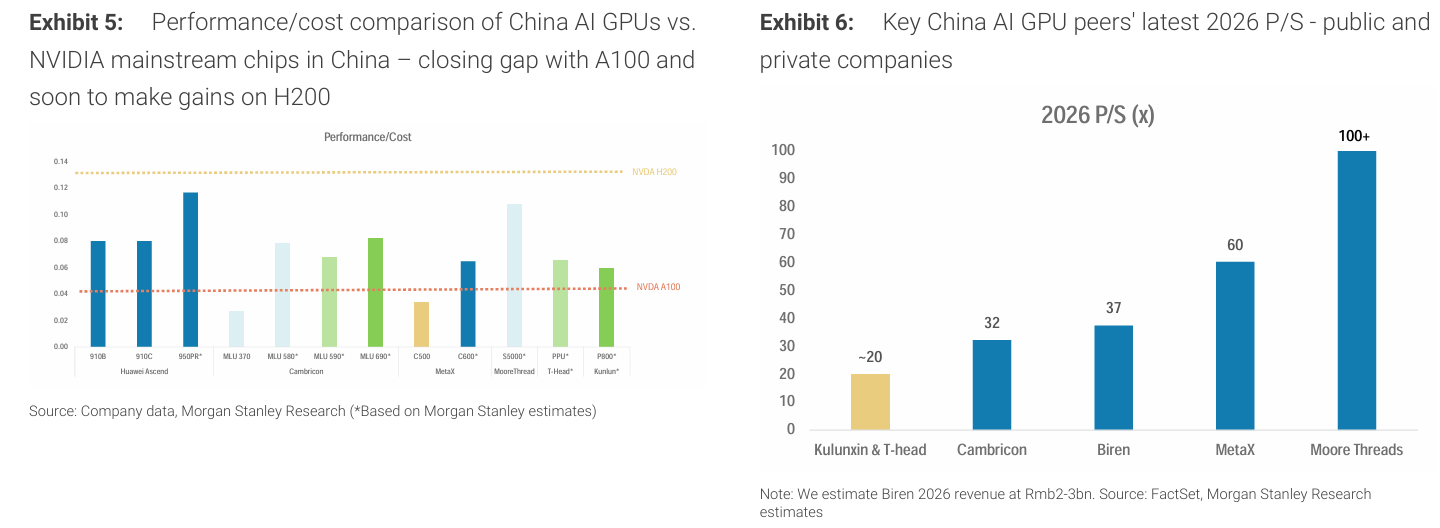
중국 GPU는 성능 대비 비용 기준에서 NVIDIA A100과의 격차를 줄였으며, 향후 H200 수준까지 접근할 가능성이 있다.
주요 중국 GPU 기업들은 높은 P/S 밸류에이션을 받고 있다.
중국은 시스템 수준 혁신과 비용 중심의 추론 경제성을 통해 AI 컴퓨팅 격차를 빠르게 좁히고 있다. 이 흐름은 자급률을 약 76%까지 끌어올리고 향후 글로벌 AI 반도체 경쟁 구도를 재편할 가능성이 있다.
미국 기업들은 여전히 칩 기술에서 우위를 유지하지만, 중국은 저비용 추론 중심 전략으로 중기적으로 글로벌 AI 경제성에 압박을 줄 수 있다.
본 보고서는 중국 AI GPU 수요, 공급, 경쟁 구조를 분석하고, 투자자들이 산업을 평가할 수 있는 프레임워크를 제시한다.
2026~2027년은 공급 제약으로 인해 시장이 공급 중심으로 움직인다.
AI GPU 시장은 빠르게 성장 중이며, CSP와 정부 주도의 투자로 수요가 증가하고 있다.
2026년 시장 규모는 약 500억 달러, 2030년에는 670억 달러까지 성장할 전망이다.
로컬 공급은 빠르게 증가하여 2027년에는 약 300억 달러 수준에 도달할 것으로 보이며, 전체 수요의 절반 이상을 커버할 수 있다.
하지만 2027년까지는 여전히 공급 중심 시장이 유지된다.
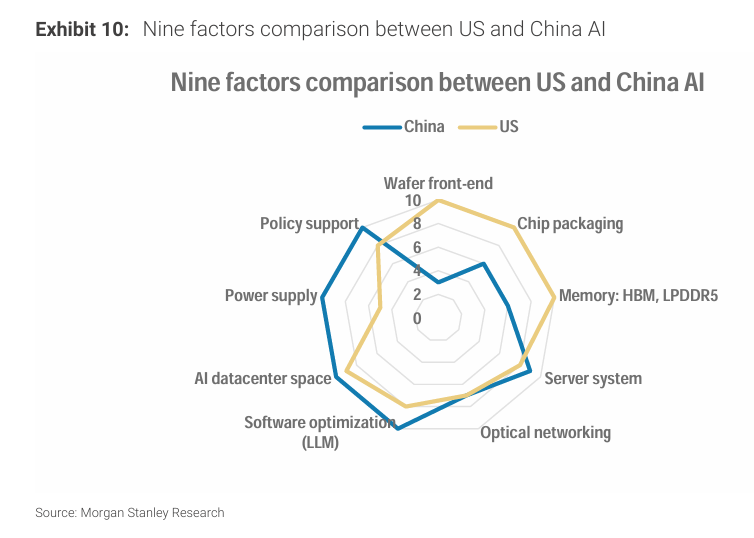
AI 인프라 측면에서 중국은 칩 수준에서는 뒤처져 있지만, 시스템과 정책 측면에서는 경쟁력이 있다.
현재 중국 GPU는 주로 추론에서 경쟁력을 보이며, 학습 영역은 여전히 NVIDIA 의존도가 높다.
공정 노드만 기준으로 비교하면 중국과 미국의 격차는 과장된다.
성능/전력/비용 기준으로 보면 격차는 상당히 좁혀진다.
중국은 낮은 전력 비용과 낮은 마진 구조 덕분에 경제성이 개선된다.
현재 10개 이상의 GPU 기업이 존재하며, 다양한 형태(상업형, 자체 설계, 국영 지원)가 혼재한다.
바이트댄스는 삼성 4nm 공정을 활용한 ASIC을 생산하고 있다.
NVIDIA H200 일부 수입이 허용될 가능성도 있으며, 이는 “완전 대체”가 아닌 “병행 전략”을 의미한다.
LLM 가격 상승은 AI 수익성을 개선하고 GPU 경제성을 강화한다.
산업 구조상 commoditization 위험이 존재한다.
Commoditization 위험 = 제품 간 차별이 사라지고, 결국 가격 경쟁으로 가버리는 상황
공급 플레이어(Huawei Cambricon MetaX Moore Threads Kunlun T-Head)가 많고 고객은 알리바바, 텐센트, 바이트댄스 같은 초대형 기업 & Alibaba → T-Head / Baidu → Kunlun / ByteDance → 자체 ASIC 와 같이 고객이 자체칩도 생산함.
-> 성능 차이가 줄어들고 공급자가 많고, 고객은 강한 상태가 되어 기술이 아니라 가격 싸움 산업으로 변하는 리스크가 있음.
대형 CSP와 정부는 최소 하나의 국산 GPU 기업을 지원하려는 유인이 있다.
동시에 CSP들은 자체 칩도 개발한다.
이로 인해 독립 GPU 기업의 시장은 제한될 수 있다.
2027년 이후 파운드리 공급이 확대되면 경쟁 심화와 마진 하락 가능성이 있다.
향후 2~3년 내 산업 통합 가능성이 높다.
중국이 경쟁력 있는 GPU를 대량 생산할 수 있는가
시장 규모는 얼마나 커질 것인가
기업 가치를 어떻게 평가할 것인가
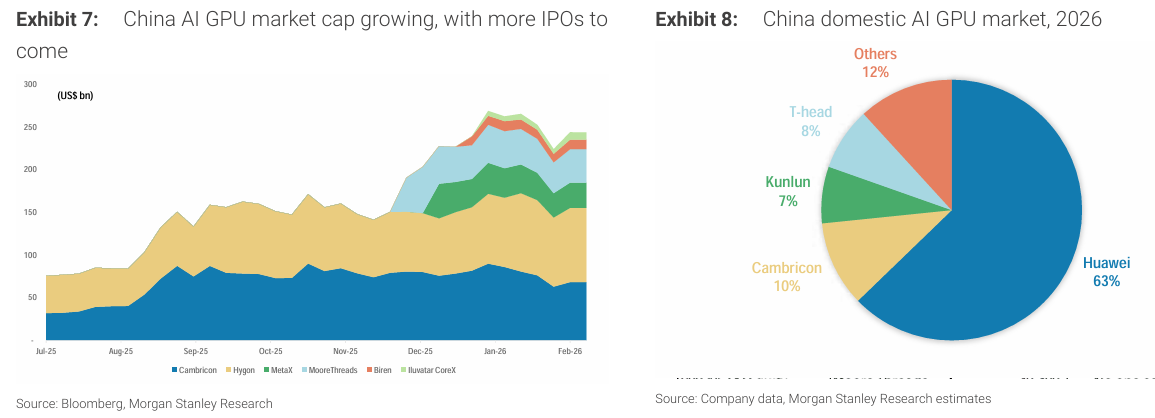
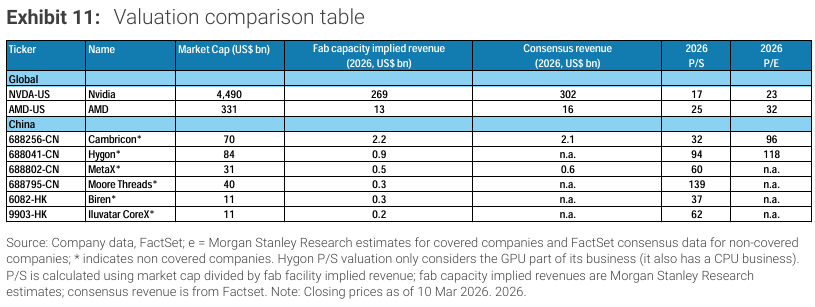
중국 AI 반도체 설계 기업들은 글로벌 동종 기업 대비 훨씬 높은 P/S 밸류에이션에서 거래되고 있다. 이는 아직 매출 규모가 작고 수익성이 초기 단계임에도 불구하고 향후 성장 기대가 크게 반영된 결과다.
Cambricon은 2026년 기준 약 32배 P/S, 96배 P/E 수준에서 거래되고 있으며, 이는 빠른 국산 대체 기대를 반영한 프리미엄이다.
Hygon은 약 94배 P/S, 1118배 P/E로 매우 높은 밸류를 받고 있으며, 이는 CPU/GPU 수요를 동시에 흡수할 것이라는 기대를 반영한다.
MetaX와 Moore Threads는 각각 약 60배, 139배 P/S로 거래되며, 아직 실질적인 이익은 거의 없는 상태다.
Biren과 Iluvatar CoreX 역시 약 37배, 62배 수준의 높은 P/S를 받고 있다.
전반적으로 중국 AI GPU 기업들은 매출 대비 매우 높은 밸류에이션을 받고 있으며, 이는 성장 기대와 정책 프리미엄이 반영된 결과다.
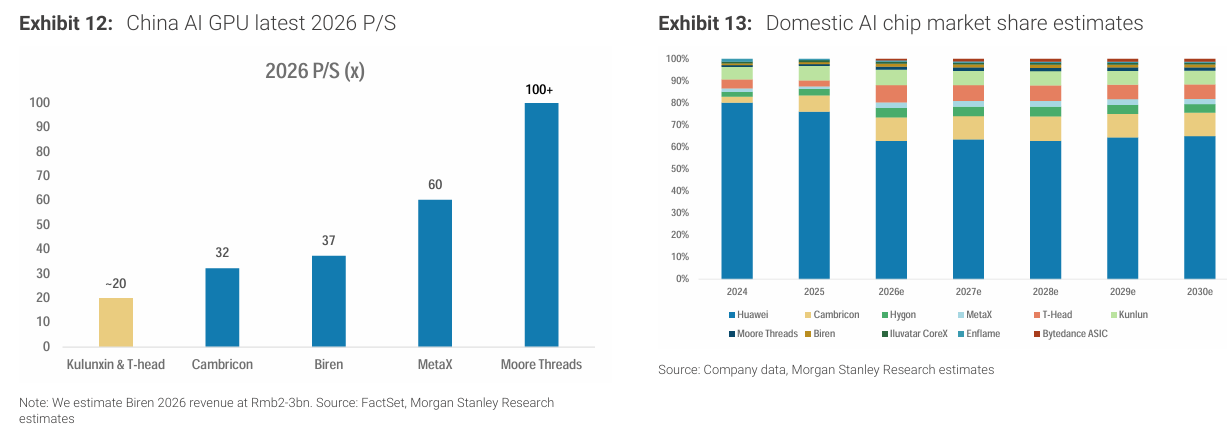
1) Kunlunxin
China Mobile, Tencent 등 외부 고객으로 판매를 확대하고 있다.
2025년 매출은 약 60억 위안으로 추정되며, 절반 정도가 외부 매출이다. 2026년에는 70억~130억 위안까지 성장할 것으로 예상된다.
시장 점유율은 한 자릿수 후반 수준이며, Huawei(63%), Cambricon(11%)에 이어 주요 플레이어다.
Kunlunxin의 밸류에이션은 200억~610억 달러로 평가된다.
이는 Cambricon 대비 0~40% 할인된 20~33배 P/S 기준이다.
Baidu의 지분 가치는 약 80억~260억 달러 수준으로 환산된다.
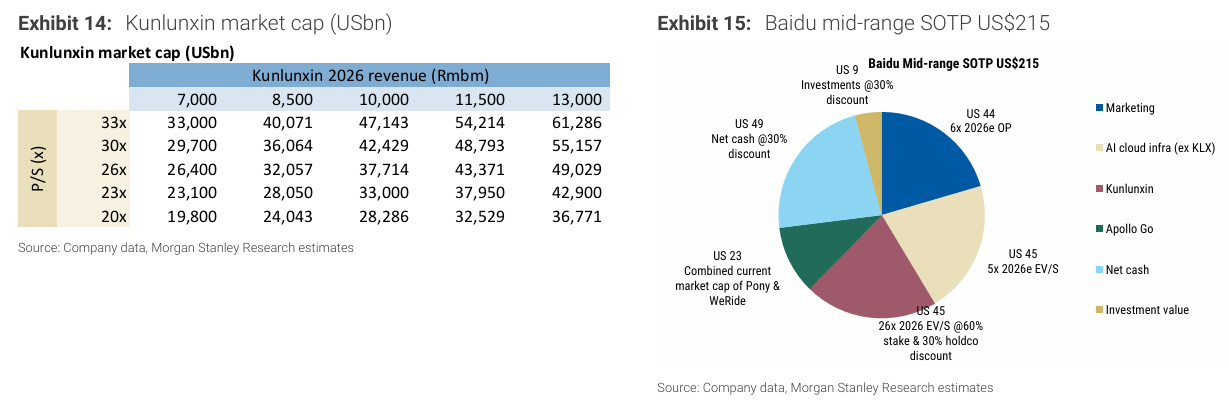
2) T-Head
2026년 매출 140억~260억 위안으로 예상되며, 절반은 GPU, 나머지는 CPU에서 발생한다.
시장 점유율은 Kunlunxin과 유사한 한 자릿수 후반 수준이다.
밸류에이션은 280억~860억 달러 범위로 평가된다.
이는 역시 20~33배 P/S 기준이다.
Alibaba SOTP에서 T-Head는 상당한 가치 비중을 차지한다.
세 가지 시나리오가 제시된다.
기본 시나리오는 수출 규제가 지속되는 가운데 점진적 개선이 이루어지는 경우다. SMIC는 생산 능력을 확대하지만 장비 제약으로 속도는 제한된다. NVIDIA H200 수입은 제한적이다.
낙관적 시나리오는 국내 생산 능력이 빠르게 개선되고 해외 파운드리 접근성이 일부 회복되는 경우다. 이 경우 생태계 성장이 가속된다.
비관적 시나리오는 장비 규제가 더 강화되고 NVIDIA GPU 접근성이 다시 확대되는 경우다. 이 경우 국산 대체 속도가 둔화된다.
시장에서는 주로 공정 노드 기준으로 경쟁력을 평가한다. 예를 들어 NVIDIA는 TSMC 4nm, 중국은 SMIC 12nm라는 식이다.
하지만 보고서는 성능/전력/비용 기준으로 보면 격차가 크게 줄어든다고 본다.
MetaX C600은 이 기준에서 NVIDIA A100과 유사한 수준에 도달한다.
향후 C700은 H200과 경쟁 가능성이 있다고 본다.
다만 장기적으로 장비 병목은 계속 존재할 가능성이 높다.
중국은 향후 5년 동안 EUV 없이 DUV 기반 다중 패터닝에 의존할 것으로 예상된다.
시장 시각: 글로벌 투자자들은 미국과 중국 AI 칩을 비교할 때 주로 공정 노드에만 집중한다. 예를 들어 NVIDIA는 TSMC 4nm, MetaX는 SMIC 12nm와 같은 식이다. 이 기준에서는 중국 AI 칩이 경쟁력이 없다고 결론 내리는 경우가 많다.
우리의 시각: 성능/전력/비용 기준(performance per watt per dollar)으로 보면 이 격차는 상당히 줄어든다. 특히 중국에서는 전력 요소의 중요도가 상대적으로 낮다.
MetaX와 NVIDIA 비교 사례에서 MetaX의 C600은 performance per watt per dollar 기준으로 NVIDIA A100과 유사한 수준을 보인다. 향후 C700으로 발전하면 H200과도 경쟁 가능하다고 본다.
다만 장기적으로는 시장이 일부 장비 병목 해소 가능성을 과도하게 낙관하고 있다고 판단한다. 예를 들어 향후 5년 동안 중국 파운드리는 자체 리소그래피 장비 대신 ASML의 DUV를 활용한 멀티 패터닝에 계속 의존할 것으로 본다.
모니터링 지표:
첨단 공정 생산능력(wpm) 및 수율 개선 속도
대규모 클러스터 안정성
소프트웨어 및 CUDA 유사 생태계 발전
리스크 요인:
수율 개선 속도 지연
장비 병목 장기화
소프트웨어 생태계 구축 난이도
중국이 경쟁력 있는 AI GPU를 대량 공급할 수 있는지를 판단하기 위해 공급 측면, 특히 파운드리 생산 능력부터 분석한다.
단순한 생산능력 확대뿐 아니라, 상위 공급망 요소들의 성숙도와 가용성이 중요한 변수다. 이러한 이유로 AI GPU 공급망 전반에서 다양한 병목이 존재한다.

AI GPU 공급망은 장비(WFE), EDA, 파운드리, 패키징, 설계, CSP까지 이어지는 구조를 가진다.
이 중 가장 큰 제약은 WFE와 EDA다.
WFE 측면에서는 일부 장비(에피택시 등)는 국산화가 진행되었지만, 리소그래피와 검사 장비는 여전히 글로벌 기업 의존도가 높다.
중국은 2025년 ASML DUV 장비를 대량 수입하여 향후 규제에 대비했다.
SMIC에서는 검사 및 계측 장비 부족으로 인해 일부 공정을 축소하고 핵심 레이어 중심으로 운영하고 있다. 이는 생산량은 유지하지만 수율에는 부정적인 영향을 줄 가능성이 있다.
EDA는 또 다른 핵심 병목이다.
중국의 Empyrean은 글로벌 시장 점유율이 1~2% 수준이며, 첨단 공정 GPU 설계에 필요한 풀 스택 EDA 솔루션을 제공하지 못하고 있다.
반면 Cadence, Synopsys, Siemens는 80% 이상의 점유율을 차지하고 있다.
미국은 GAA 구조에 필요한 EDA 소프트웨어 수출을 제한하고 있으며, 이는 중국의 3nm 및 2nm 개발을 제약한다.
이로 인해 중국 AI 칩 설계 기업들은 첨단 공정으로의 전환에 어려움을 겪고 있다.

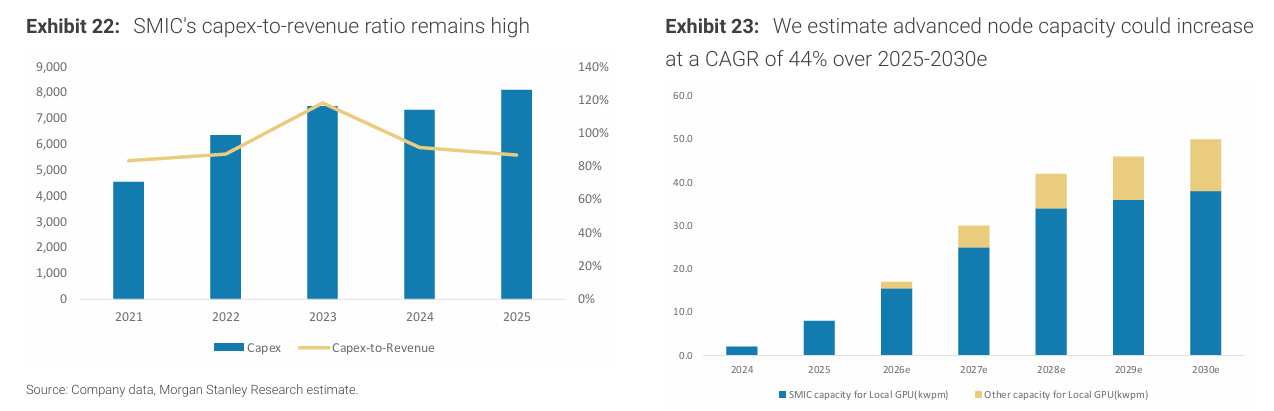
SMIC의 생산능력 확대는 첨단 공정 병목을 완전히 제거하지는 못하고, 오히려 병목의 위치를 장비에서 파운드리 실행 및 용량 배분으로 이동시키고 있다. 그 결과, SMIC는 사실상 중국 AI GPU 생산 확대의 핵심 병목 지점이 되었다.
여러 중국 AI 칩 기업들은 생산을 다시 중국 본토로 이전하고 있으며, SMIC의 N+2(7nm) 및 N+1(12nm) 공정을 활용해 AI 가속기를 테이프아웃하려 하고 있다. 이는 해외 의존도를 줄이고 제약을 완화하려는 시도다.
현재 중국의 첨단 공정 생산능력은 SMIC South에 집중되어 있으며, DUV 멀티 패터닝을 통해 N+2 공정이 구현되고 있다. 이론적으로는 N+3(약 5nm 수준)까지 확장 가능성이 언급된다.
SMIC의 N+2 생산능력은
2025년 약 22k wpm → 2026년 40k → 2027년 51k로 증가할 것으로 추정된다.
하지만 이 생산능력은 스마트폰 및 자동차 SoC 수요와 경쟁해야 하며, AI GPU에 전량 배정되지는 않는다.
일부 기업들은 N+1 공정을 선택하고 있다. 이는 생산 안정성, 수율, 비용 측면에서 현실적인 선택이다. 다만 N+1 기반 칩은 연산 밀도와 전력 효율에서 구조적으로 불리하며, 대규모 학습보다는 추론 workload에 적합하다.
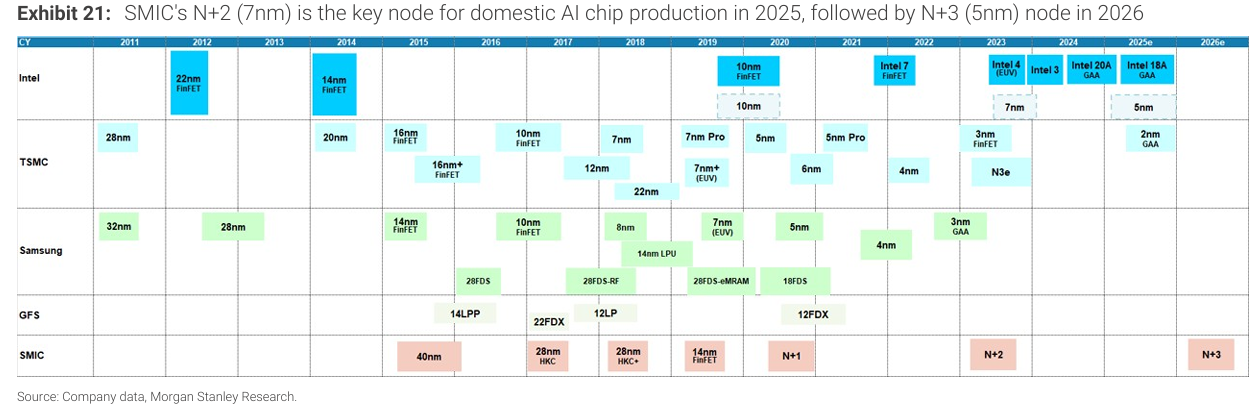
앞서 언급한 것처럼 SMIC의 생산능력 확대는 공정 격차를 완전히 해소하지 못한다. 이에 따라 중국 AI 칩 기업과 CSP들은 공정 자체를 따라잡기보다는 시스템 및 아키텍처 수준에서 보완하는 전략을 채택하고 있다.
중국 AI 가속기는 여전히 성능과 전력 효율에서 글로벌 경쟁사 대비 열위에 있다. 이러한 상황에서 세 가지 대응 전략이 나타난다.
첫 번째 전략: “하나의 다이가 충분히 강력하지 않다면, 여러 개를 묶어 하나의 칩으로 만든다.”
공정 및 설계 제약으로 인해 단일 다이 성능이 낮기 때문에, 멀티 다이 구조와 첨단 패키징을 통해 성능을 보완한다. 이는 공정 업그레이드 없이도 성능을 일정 부분 끌어올릴 수 있는 방법이다.
두 번째 전략: “하나의 칩이 부족하다면, 더 큰 랙과 클러스터를 구축한다.”
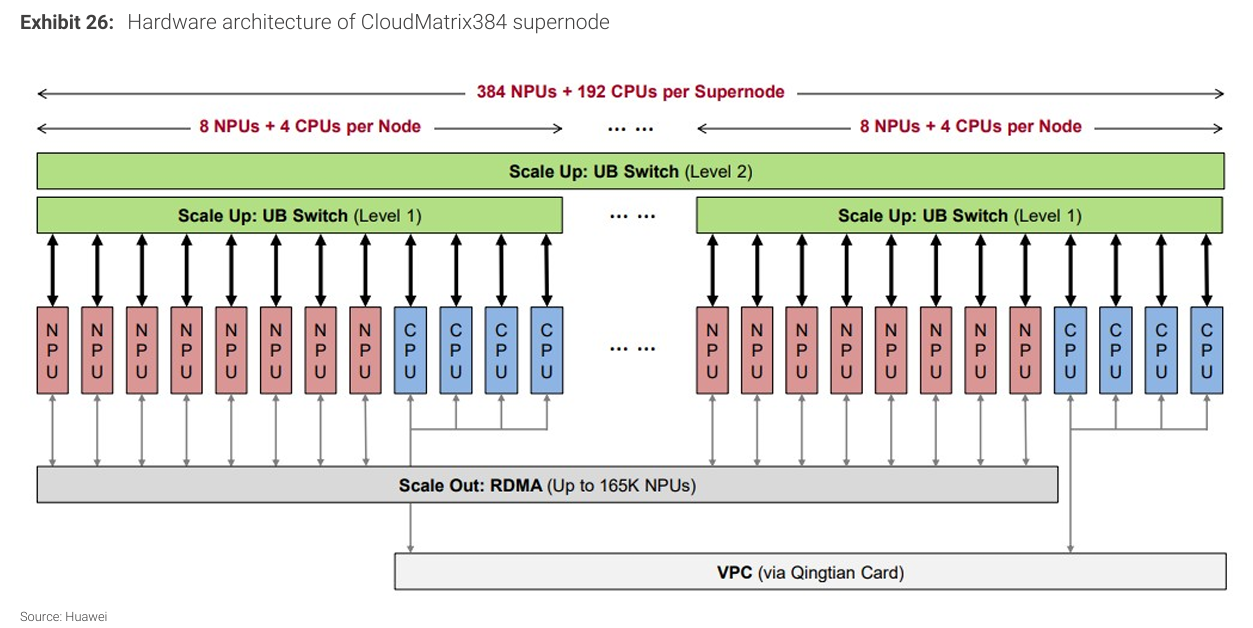
기존 AI 서버는 4~8개의 GPU를 사용하지만, NVIDIA NVL72는 72개의 GPU를 하나의 시스템으로 연결한다. 중국 기업들도 유사한 scale-up 아키텍처를 채택하고 있다.
Huawei CloudMatrix 384
Alibaba PPU 기반 랙
ByteDance 256 가속기 랙
이러한 구조는 GPU 간 연결 대역폭을 높이고 랙 단위 성능을 크게 개선한다.
세 번째 전략: “파운드리가 부족하다면, 생산능력을 확장한다.”
SMIC는 지속적으로 대규모 CAPEX를 집행하고 있으며, DUV 장비 확보도 확대하고 있다. 이는 중기적으로 첨단 공정 생산능력 확대를 지원하지만, 글로벌 선도 공정과의 격차를 완전히 해소하지는 못한다.

공정 제약으로 인해 일부 칩은 이전 세대 대비 성능이 낮아지는 현상도 나타난다. 예를 들어 Ascend 950PR은 910C 대비 약 38% 낮은 연산 성능을 보이는 것으로 알려져 있다.
이러한 한계를 보완하기 위해 멀티 다이 패키징이 활용되며, 절대적인 연산 성능은 일정 부분 회복된다.
시스템 수준에서는 scale-up 아키텍처가 빠르게 확산되고 있다. NVL72는 기존 서버 구조에서 벗어나 72개의 GPU를 단일 시스템으로 연결하며, GPU 간 통신 병목을 크게 줄인다.
중국 기업들도 이와 유사한 구조를 도입하고 있다. Huawei의 CloudMatrix 384, Alibaba의 PPU 기반 랙, ByteDance의 256 가속기 랙이 대표적이다.
이러한 접근 방식은 개별 칩 성능의 한계를 시스템 수준에서 보완한다.
중국은 칩 단위 성능 격차를 완전히 해소하지 못하고 있지만, 시스템 아키텍처를 통해 경쟁력을 확보하고 있다. 특히 광학 네트워킹과 대규모 랙 설계에서 빠른 진전을 보이고 있다.
Huawei의 Ascend CloudMatrix 384는 광학 인터커넥트를 활용하여 대규모 연결 구조를 구현한다.
차세대 Ascend 플랫폼에서는 최대 8,192개의 칩까지 확장이 가능하다고 주장된다.
또한 Ascend 950PR 및 950DT는 최대 2TB/s의 인터커넥트 대역폭을 제공하며, 이는 NVIDIA NVLink Gen5(1.8TB/s)를 상회하는 수준이다.
즉, 네트워크 연결 측면에서는 이미 글로벌 경쟁력을 확보하고 있다.
글로벌 AI 시스템에서는 연산 성능 증가 속도에 비해 네트워크 성능 개선이 상대적으로 제한적이다. 이는 일부 GPU 자원이 유휴 상태로 남는 비효율을 초래한다.
반면 중국 시스템은 상대적으로 균형 잡힌 구조를 보인다. 절대적인 연산 성능은 낮지만, 네트워크와의 균형이 잘 맞기 때문에 시스템 효율성이 높을 수 있다.
특히 inference 중심 환경에서는 이러한 균형이...

재밌게 본 리포트인데 역시 공유해주시는군요👍👍