Dirtycat
구독자 133명구독중 96명
휴스턴 시골 아재
달리기와 독서 그리고 아이들과 놀아주는 것을 좋아합니다.
오늘은 UCLA와 MIT에서 작성한 TradingAgents 논문을 들고 왔습니다. 헤지펀드의 투자 의사 결정을 다중 에이전트 LLM 트레이딩 프레임워크로 따라해보자는 내용입니다. 사실 작년에 발표된 논문인데 최근 깃허브 리포가 입소문을 타고 유명해져서 저도 따라해봤습니다. 새롭거나 신기한건 일단 시도해봐야죠.
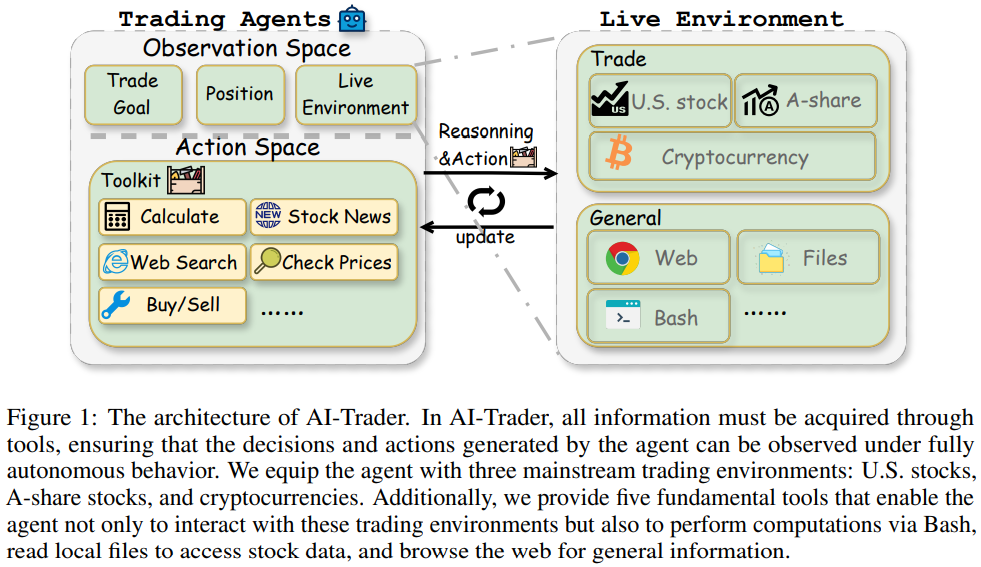
예전 글에서 금융 의사결정을 위한 LLM 에이전트 내용을 소개해드렸습니다. AI모델이 트레이딩 모델을 만들고 인간의 개입 없이 스스로 수익을 낸다는 내용이었는데, 자세히 뜯어보면 취약한 리스크 관리 능력 등 아쉬운 부분이 많았었습니다. 그에 반해 오늘 소개해드릴 논문은 실제 투자 회사처럼 7명의 에이전트들이 아래와 같이 각자 역할을 합니다.
펀더멘털 애널리스트: 재무제표, 어닝 보고서, 내부자 거래 분석. 기업 내재가치 평가.
감성 애널리스트: Reddit·X/Twitter 소셜 미디어 감성 점수 분석. 단기 심리 예측.
뉴스 애널리스트: Bloomberg·Finnhub 뉴스, 정부 발표, 거시경제 지표 분석.
기술적 애널리스트: MACD·RSI·볼린저밴드 등 60개 기술 지표 계산 및 패턴 분석.
리서처 (강세/약세): 불리시·베어리시 두 에이전트가 토론. 투자 위험·기회를 다각도로 검토.
트레이더: 분석 종합 후 매수·매도·보유 신호 생성. 타이밍·규모 결정.
리스크 매니저 & 펀드 매니저: 공격적·중립·보수적 시각으로 리스크 조정. 최종 승인 및 실행.
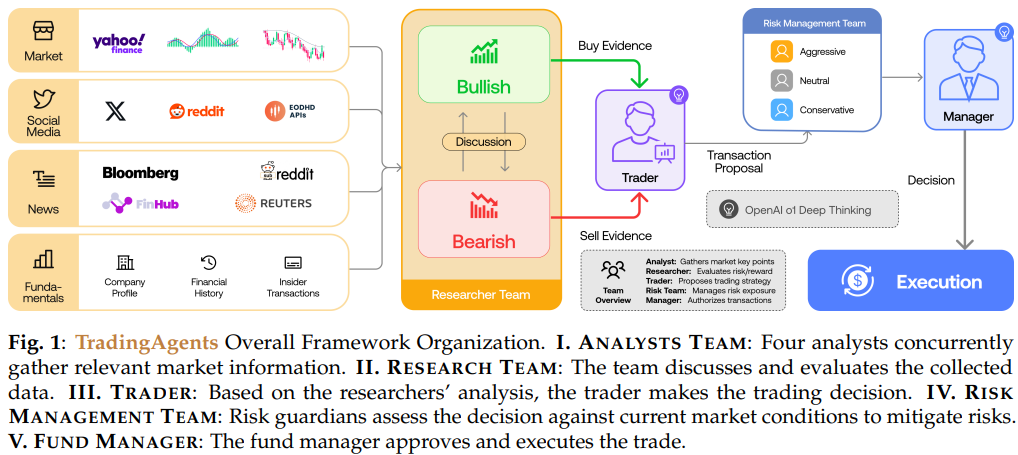
정리하자면
펀더멘털·감성·뉴스·기술적 애널리스트 4명이 병렬로 데이터를 ...

한 번 해봐야겠네요! 곧 토스증권도 API나온다고 하는데 정말 에이전틱 매매 시대가 오려나요?ㅎㅎ
제가 예상하는 미래는 아마 95% 이상의 매매가 사람의 클릭 없이 컴퓨터로 이뤄질듯 합니다. 그렇다면 우리 휴먼 입장에서는 이러한 알고리즘들이 어떻게 트리거되는지, 어떠한 외부환경에 어떻게 반응하는지를 연구하고 그에 맞춰서 대응해야 할 것 같아요.
GLM으로 써서 그런 것인지 아니면 커뮤니티 디폴트가 레딧같은 곳이라 그런지 모르겠지만 한국주식은 어렵겠네요 ㅠㅠ
맞아요 한국 주식에 대한 정보는 X나 레딧, EODHD api에서 찾기 힘들죠. TradingAgents가 과연 네이버 종토방을 찾을 수 있을지 의문이에요.
한국 주식용으로 쓰려면 오픈소스니까 좀 만져서 써야겠습니다. 보고서 펠로우 게시판에 공유해드릴께요!
방금 결과가 끝났는데 한국주식은 재무제표 데이터부터 틀려서 그냥 긴 쓰레기가 완성됐습니다... 미국 주식으로 돌려보겠습니다...
긴 쓰레기가 나오다니 또르르
역시 가비지인 가비지 아웃인가봐요

아주 흥미롭고 신기하네요!
토론 과정이 다른 모델에서 못보던 것이라 저도 신기했어요. 재밌게 읽어주셔서 감사합니다

아무래도 본업 이외의 부분에 토큰이 많이 들어가면 부담스럽죠.. 그래서 저는 요즘 테스트 해보는 것이, 프리셋 효율화입니다. 시간이 걸리더라도 2~3주 정도 데이터 클리닝과 Parquet Aligning에 시간 쏟고, 1주 정도는 정리된 부분에 편향이 없는지 실제 모델링 중에 오류가 나거나, 문제될 만한 부분은 상황에 따라 1주 정도 더 추가된다고 생각하고 진행하고 있습니다. 이제 딱 4주차에 거의 모든 분석들 돌리는데 기존 대비 2~3배 정도 토큰 소모량이 효율/경량화 된 것 같습니다. 재미삼아 제약 조건을 걸긴 했는데.. 클로드 프로 (제일 싼 모델) 기준으로 가능한 것 보면 더 좋은 방법도 많을 것 같긴 합니다 ㅎㅎ 헤비하면 헤비할수록 미리 준비하는 부분에 상당히 공을 들이는 게 중요하지 않겠나 싶어서 해봤는데 (아직까지는) 잘 됩니다.
저도 처음에 클로드 프로로 openclaw 돌린다고 미리 준비하는 부분에 상당히 공을 들였던 기억이 나네요!
실체감 예시로, 예전에는 "아니.. 여기서 사용량 끝난다고?" 했던 부분이 지금은 "와 아직 많이 남았네" 할 정도로 체감되긴 합니다. 참고로 밸리 스페이스에 올리는 경제학 통계들이랑 모델링들은 위 제약조건 (제일 싼 클로드) 으로 돌리는 중입니다.. 아마 Dirtycat 선생님께 맞는 방법 찾으시면 효율/최적하시는 재미가.. 있으실 겁니다..
아, 쓰다보니 또 생각난 부분은, 아직까지 LLM으로 처리하기 힘든 부분이 상당히 많이 남아있는 것 같긴 합니다. 제 개인적인 의견입니다만, 트레이딩 엣지보다는 롱텀 엣지가 훨씬 더 빛을 발하는 곳이 많아서, 위 헤지펀드 에이전트들의 Role 부분도 하나 하나 독립적으로 보고 그 사이를 이어주는 Context는 LLM이 아예 무슨 말인지 이해를 못하는 부분들이 많았었습니다. Context Engineering을 한다고는 하는데, 저는 이 부분은 개인 역량에 달려있는 것 같다는 생각이 강화되고 있습니다. 아마 AI가 추월하기 힘든 부분일 것이라고 봅니다 ㅎㅎ
Fine님이 알려주신 인풋 데이터 클리닝 및 최적화를 하고 모델을 돌리면 토큰도 절약되고 결과도 신뢰성도 함께 올라가겠네요. 저도 좀 더 고민을 해봐야겠어요.
에이전트 사이를 이어주는 컨텍스트는 위 논문에서 리포트 형식과 자연어 처리를 섞어서 극복했다고 하는데, 그래도 놓치는 부분이 생길 수 있을것 같아요. 역시 개인 역량에 따라 어떻게 지시를 내리고 방향을 수정해주는지가 중요하겠군요. 아이러니하게도 AI시대에 가장 중요한게 사람의 사고 깊이와 그것을 AI에게 효과적으로 전달하고 결과를 독립적으로 판단하는 부분이라고 생각합니다.
Fine님과 몽사님 두분의 대화가 많은 도움이 되었습니다 감사합니다!

좋은 글 감사드립니다. 한번쯤 따라가면서 배울 것만 쏙 빼먹고 직접 해야할 것 같다는 생각이 들었습니다. :)
uyru님도 직접 한번 돌려보세요 생각보다 쉬워요! 글을 읽는것과 직접 해보는건 생각보다 차이점이 크답니다