앞선 반도체 그리고 AI 이제 끝인가?라는 주제로 두 편의 글을 쓰고, 다음 글은 ChatGPT5 출시 이후에 다시 그 주제로 글을 작성하고자 하였으나, 오히려 해당 사이클의 산업을 좀 더 자세히 다루며 공부하고자 하여 이 글을 작성하게 되었습니다.
(최대한 많은 자료들을 수집하여, 정리하며, 혹시 기억이 안날수도 있기에 기초적인 부분도 같이 작성해서 저나 어머니도 두고두고 다시 볼 수 있는 글을 목표로 하며 작성중입니다. 특히 아마도 제가 관심 있는 영역에 좀 더 많은 힘을 줄 것으로 예상됩니다; 추후에도 계속 업데이트도 할 예정입니다 업데이트되었을시 제목에 업데이트 내역을 표기하겠습니다; 추후에 몇몇 기업들은 재무제표부터 시작해서 Valuation을 해볼것 같습니다.(그전에 ValC 먼저 나가야 하지 않을까.... 크흠) )
AI cycle: 데이터센터에 대하여 (1)
앞선 글들의 주요 핵심 프레임만 빼서 다시 복습해봅시다.(자세한 설명은 앞선 두 글과 월가아재님의 영상에서 확인하실 수 있습니다: (1), (2), (영상))
AI 사이클이라는 산업을 투자함에 있어서 고려해야하는 3가지의 프레임이 존재하는 것 같습니다.
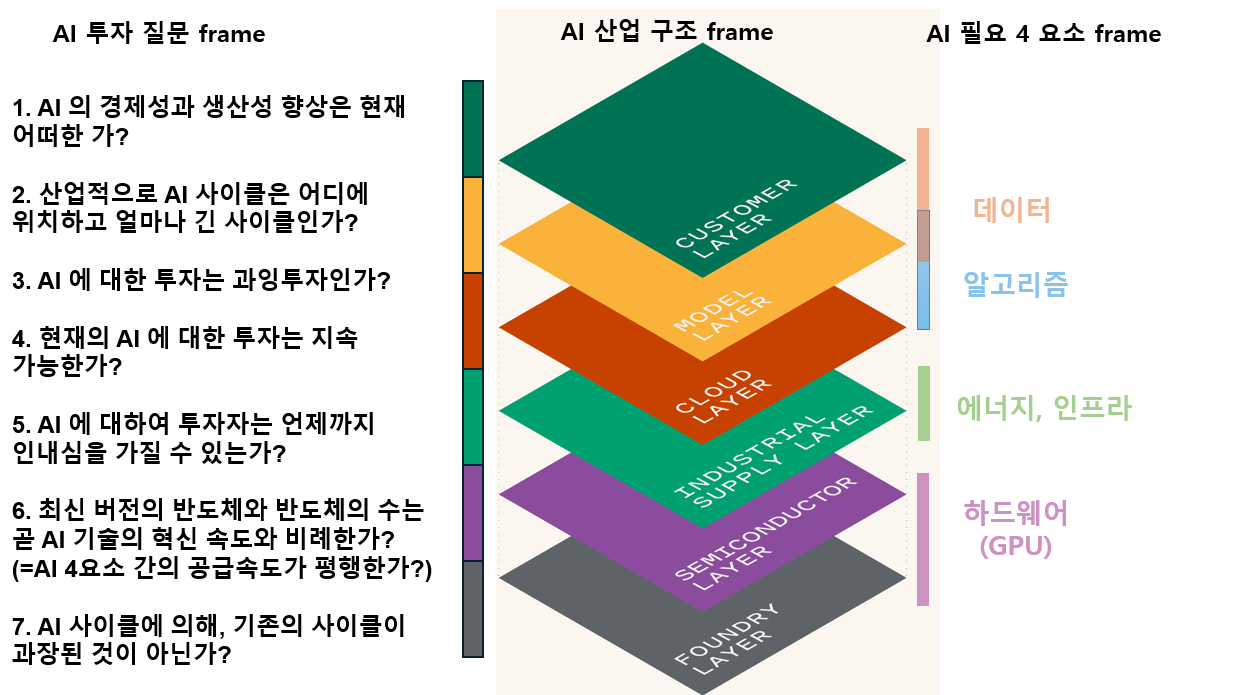
AI 투자에 대한 7가지 질문
AI의 경제성과 생산성 향상은 현재 어떠한가?
산업적으로 AI 사이클은 어디에 위치하고 얼마나 긴 사이클인가?
AI에 대한 투자는 과잉투자인가?
현재의 AI에 대한 투자는 지속 가능한가?
AI에 대하여 투자자는 언제까지 인내심을 가질 수 있는가?
최신 버전의 반도체와 반도체의 수는 곧 AI 기술의 혁신 속도와 비례한가?
(=AI 4요소 간의 공급속도가 평행한가?)
AI 사이클에 의해, 기존의 사이클이 과장된 것이 아닌가?
AI 산업 레이어
파운드리 레이어
반도체 레이어
공급망 레이어
클라우드 레이어 (현재 AI 산업의 리스크를 책임지고 있는 레이어)
모델 레이어
소비자 레이어
AI의 필요조건
하드웨어(GPU)
에너지와 인프라
알고리즘
데이터
이 AI 산업 또한 좀 더 세분화를 하자면, 각 산업레이어 구성과 필요조건과 질문의 우선순위는 달라질 수 있을겁니다.
그 중 이번 포스팅에서 다룰 영역은 Datacenter입니다.
데이터센터는 데이터센터는 기업이나 조직이 데이터를 저장하고 처리하는 데 사용되는 물리적 공간으로 현재 AI 산업에 있어서 가장 메인이 되고 있는 파트이면서도, AI’s $600B Question의 세콰이어 조차 2025년을 자칭 데이터센터의 해라 이야기할 정도로,여전히 저평가되어 있다고 이야기할 수 있는 파트입니다.
이번 글의 주요 참조 글은 ERIC FLANINGAM이라는 리서처의 A Primer on Data Centers - by Eric Flaningam (generativevalue.com)입니다.
(한글 번역은 퀄리티기업연구소님의 [IT] 데이터 센터 입문서 from EricFlaningamMoonlight (valley.town) 로 보실수 있습니다; 사실상 이글은 eric flaningam의 글에 추가적으로 여러가지 살을 붙힌 형태를 띄었습니다.)
ERIC FLANINGAM이 정리한 데이터센터 밸류체인은 다음과 같습니다.
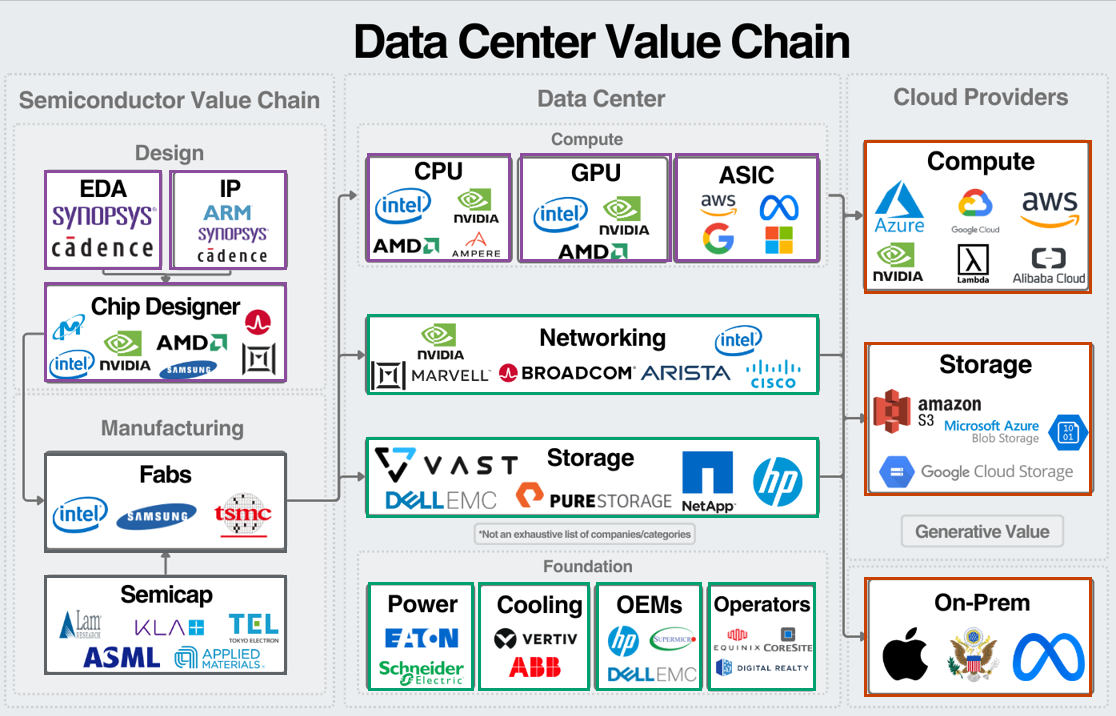
(그림에 회색: 파운드리레이어, 보라색: 반도체레이어, 초록색: 공급망레이어, 주황색: 클라우드레이어; 어떤 기업이나 산업은 여러 레이어가 중복되어 속한다고 볼수 있기에 정확하지 않을 수 있습니다.)
데이터센터 밸류체인은 다음과 같이 크게 3개로 나누어 반도체 밸류체인 -> 데이터센터 -> 클라우드로 이야기할수 있으며 그중 데이터센터의 영역은 1. 컴퓨팅, 2. 네트워킹, 3.스토리지로 구성되며 이를 뒷받침해주는 서버, 파워, 냉각시스템, Operators 등이 있습니다.
이를 다시 저희가 이야기한 AI 레이어 측면에서 이야기한다면, 데이터센터 밸류체인이란, 반도체벨류체인 즉 반도체레이어와 파운드리레이어 에서 데이터센터라는 반도체레이어와 공급망레이어에 속한 기업들 마지막으로 클라우드 레이어에 속한 기업들로 가는 체인이라는 것입니다
따라서 오늘 주로 다룰 레이어는 아마 반도체 레이어와 공급망레이어에 속한 산업과 기업 이야기를 할 것이며 앞선 데이터센터 영역의 분류를 따라 이야기를 해보죠.
일단 각 영역별로 들어가기 전에 해당 데이터센터 전체 시장 규모와 예상 규모를 이야기해봅시다.
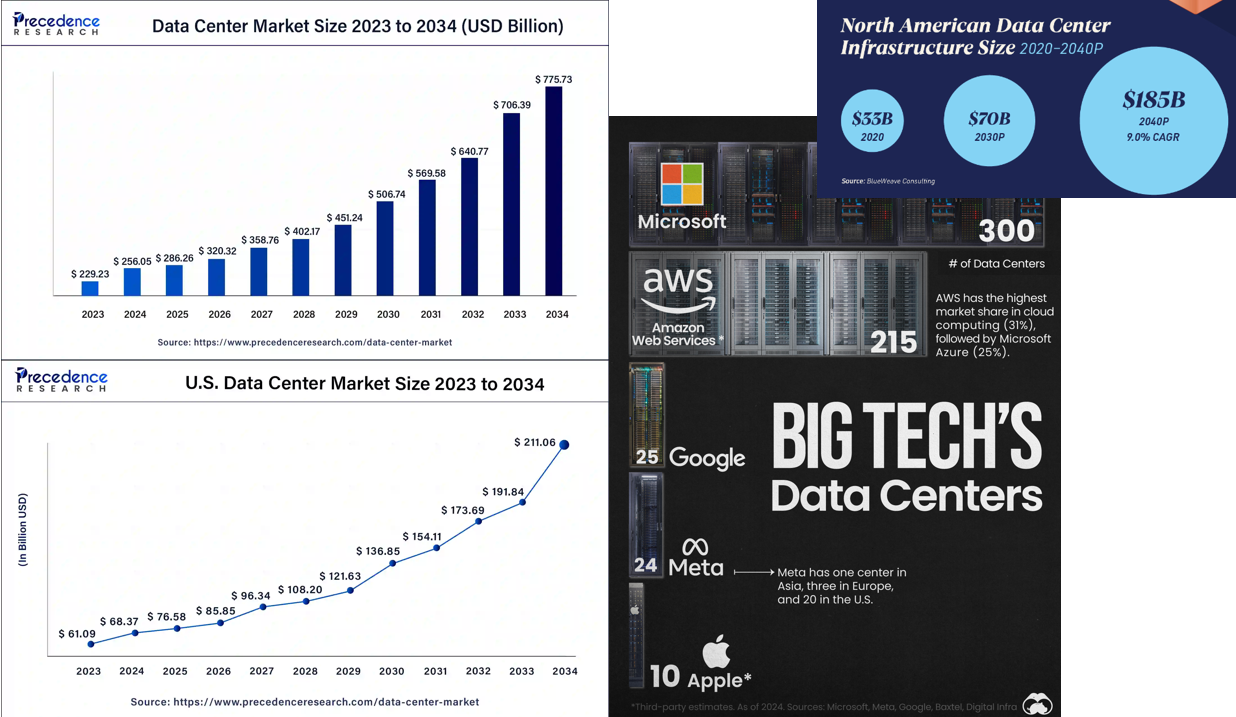
현재(2024년)를 기준으로 글로벌 데이터센터 시장 규모는 $256B으로 추정되고, 그 중 미국이 $65B로 추정된다고 합니다.
뿐 만아니라, 데이터센터시장규모는 2030년까지 500B달러를 넘을 것으로 보며, 미국에서의 규모만 약 137B 달러로 예상되고 있습니다
(위 자료들은 각각 24년도 7월 precedenceresearch 자료, 22년도 Blueweave consulting 자료 그리고 24년도 6월 voronoi자료를 참고했습니다.)
현재 빅테크들은 앞선 그림에서 보여주듯, 마이크로소프트는 300개, 아마존은 215개, 구글은 25개, 메타 24개, 애플 10개의 데이터센터를 현재 보유중이며, 아시다시피 이들은 대부분 더 CapEx를 투자하며 더 많은 데이터센터를 건설하고 있습니다. 또한 빅테크뿐만이 아니라 다양한 기업들, 다양한 국가들은 계속해서 건설 및 투자를 하고 있죠.

다음 사진은 일론머스크의 xAI의 데이터센터 위성 사진인데요. 보시다시피 그 규모 또한 매우 크고 다양한 유틸리티 산업들이 위치하고 있음을 알 수 있습니다. 좀 더 데이터센터에 친숙해지기 위해 구조도 좀 더 살펴보죠.
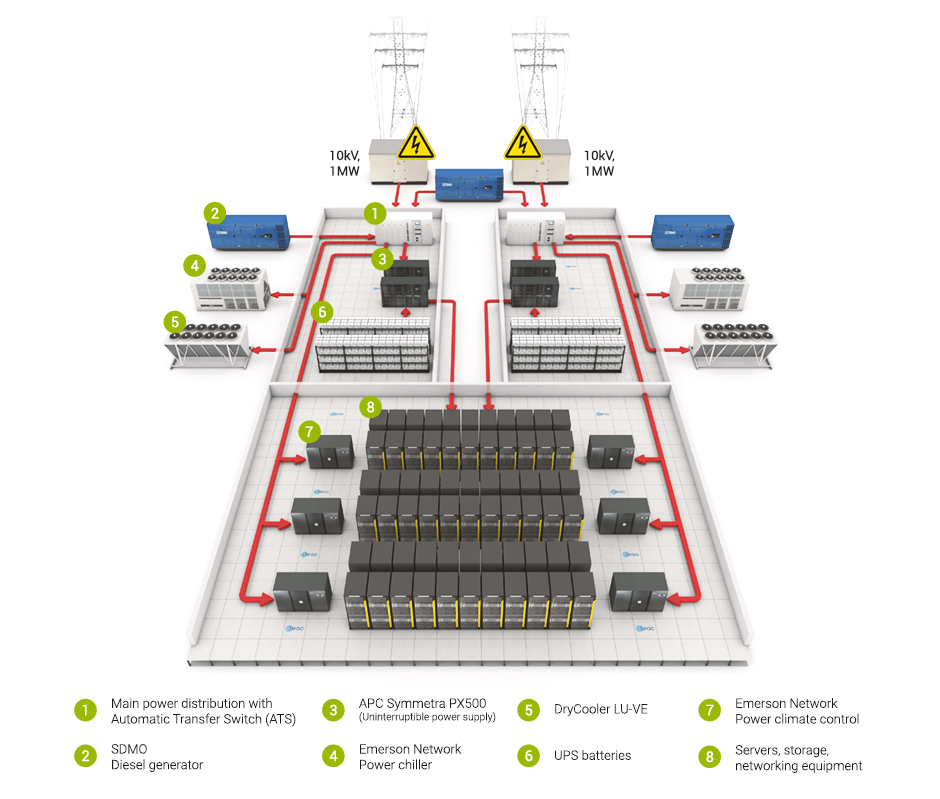
데이터 센터를 구축하는 데 필요한 인프라에는 토지, 건축, 변압기, 전력 관리 및 냉각 기술이 포함되면 이는 컴퓨팅 및 스토리지 전력을 수용하는 서버에 전력을 공급하기 위한 것이죠.

서버는 브로드컴의 설명과 같이, 다른 서버, 네트워킹 장비, 스토리지와 함께 랙에 저장됩니다. 그리고 이런 렉이 수백에서 수천 개 모아 있는 곳이 바로 데이터 센터입니다.
컴퓨팅(Coputing)
컴퓨팅 성능은 데이터 센터의 핵심입니다.
컴퓨팅 성능은 서버에서 애플리케이션을 실행하는 데 필요한 처리 능력과 메모리를 의미합니다. 서버는 워크로드 유형에 따라 다양한 유형의 칩(일반적으로 CPU 또는 GPU)을 사용합니다. CPU는 컴퓨터의 중앙 프로세서로 복잡한 작업을 처리하는 데 능숙하며 소프트웨어의 주요 인터페이스 역할을 합니다. GPU는 단순한 작업을 처리하는데 능숙하나, 병렬 처리에 탁월하여 많은 간단한 작업을 한 번에 완료합니다. 그렇기 때문에 그래픽 본연의 목적에 매우 적합하죠.
이는 다음 영상을 통해 잘 알수 있습니다: NVIDIA의 과학시간 - GPU와 CPU의 차이 (youtube.com)

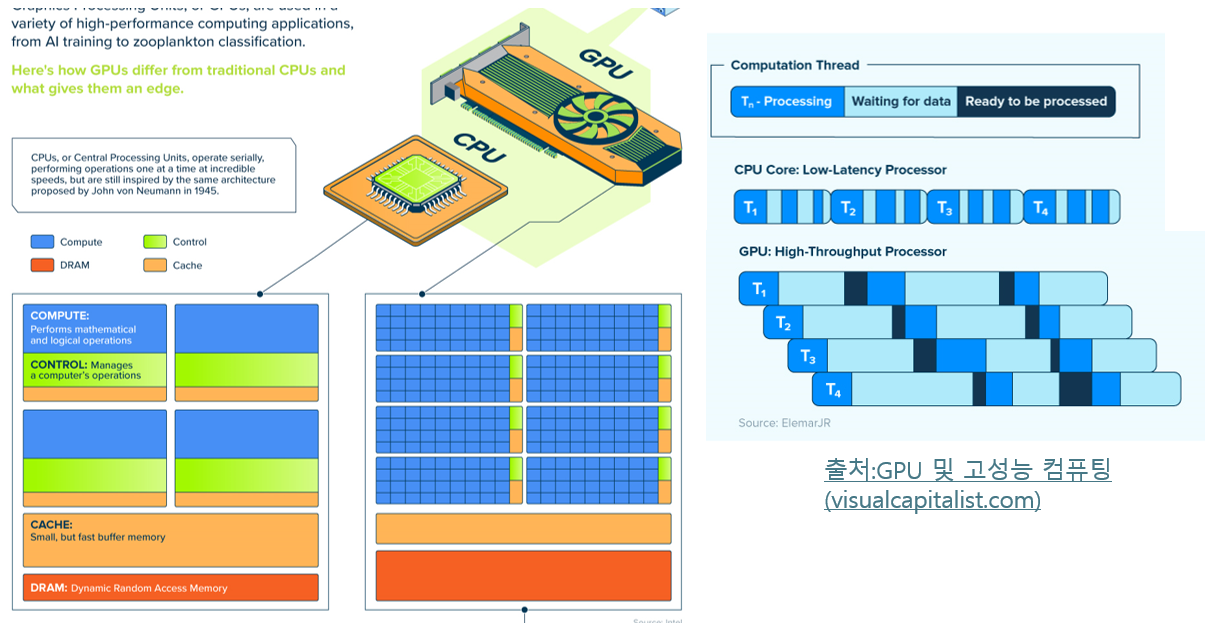
그리고 이러한 GPU들을 더 많이 병렬적으로 구성함으로서, 많은 작은 계산으로 구성된 AI 워크로드에 적합하게 설계되었습니다.

그러다보니, GPU의 강자 엔비디아가 현재 데이터 센터 컴퓨팅부문의 수입이 73%를 차지하고 있습니다. 반면 인텔의 경우 데이터센터의 수입이 커지지 못하고 있었죠. 이는 다시 바로 뒤에서 좀 더 자세히 알아봅시다. 또한 CPU와 GPU 외에도, 애플리케이션별 집적 회로 및 필드 프로그래머블 게이트 어레이와 같은 다른 유형의 칩도 사용됩니다만, 사용 빈도는 훨씬 적습니다.
ASIC은 Google의 AI 가속기 TPU와 같이 특정 워크로드를 위해 맞춤 제작된 AI 가속기입니다. 논리적으로 볼 때, 약간의 효율성 향상으로 하이퍼스케일러의 비용을 크게 절감할 수 있기 때문에 클라우드 데이터 센터에서 ASIC의 사용 빈도는 계속 높아질 것으로 예상되고 있습니다.
이 부분을 좀 더 자세히 이야기하자면, (아주 쉽고 단순하게) AI칩은 훈련용 AI칩, 추론형 AI칩으로 분류할 수 있습니다.
훈련이란 결국 AI 모델, 특히 딥러닝 모델을 학습 데이터로부터 패턴과 관계를 학습시켜 성능을 향상시키는 과정이기에, 대규모 데이터셋과 복잡한 연산을 필요로 하며, 높은 계산 능력과 메모리 용량이 요구됩니다. 따라서 훈련용 AI칩에는 고성능 GPU 또는 TPU와 같은 AI 가속기가 주로 사용되며 대규모 분산 컴퓨팅 환경이 필요할 수 있죠.
반면 추론용 AI칩은 (여기서 보통, 추론은 인간수준의 추론을 이야기하지 않죠) 훈련된 AI 모델을 실제 데이터에 적용하여 예측이나 분류 등의 작업을 수행하는 과정으로 실시간 또는 근실시간으로 빠른 응답을 요구하며, 상대적으로 훈련보다 낮은 계산 능력이 필요합니다. 그렇기때문에, 효율적인 응답을 위해 최적화된 CPU, GPU, 또는 ASIC 기반의 AI 가속기가 사용됩니다.
CPU 시장
데이터센터 CPU 시장은 역사적으로 인텔이 주도해 왔으며 AMD가 그 뒤를 바짝 쫓고 있습니다. 이제 AMD는 Amazon, Ampere, Nvidia 등의 Arm 기반 CPU와 함께 더 많은 경쟁을 벌이고 있습니다.
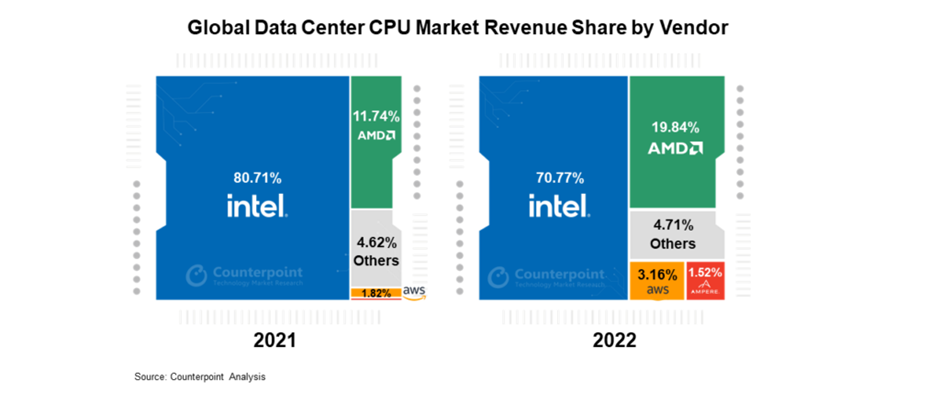
CPU 시장에서는 두 가지 주요 트렌드가 나타나고 있습니다.
1. AMD의 점유율 확대
첫째, AMD는 x86 프로세서에서 인텔의 점유율을 빼앗아가고 있습니다. 이는 대부분 Lisa Su의 리더십 덕분입니다. Lisa는 2014년에 취임했으며 지난 10년간의 성과는 믿을 수 없을 정도로 놀라웠습니다:
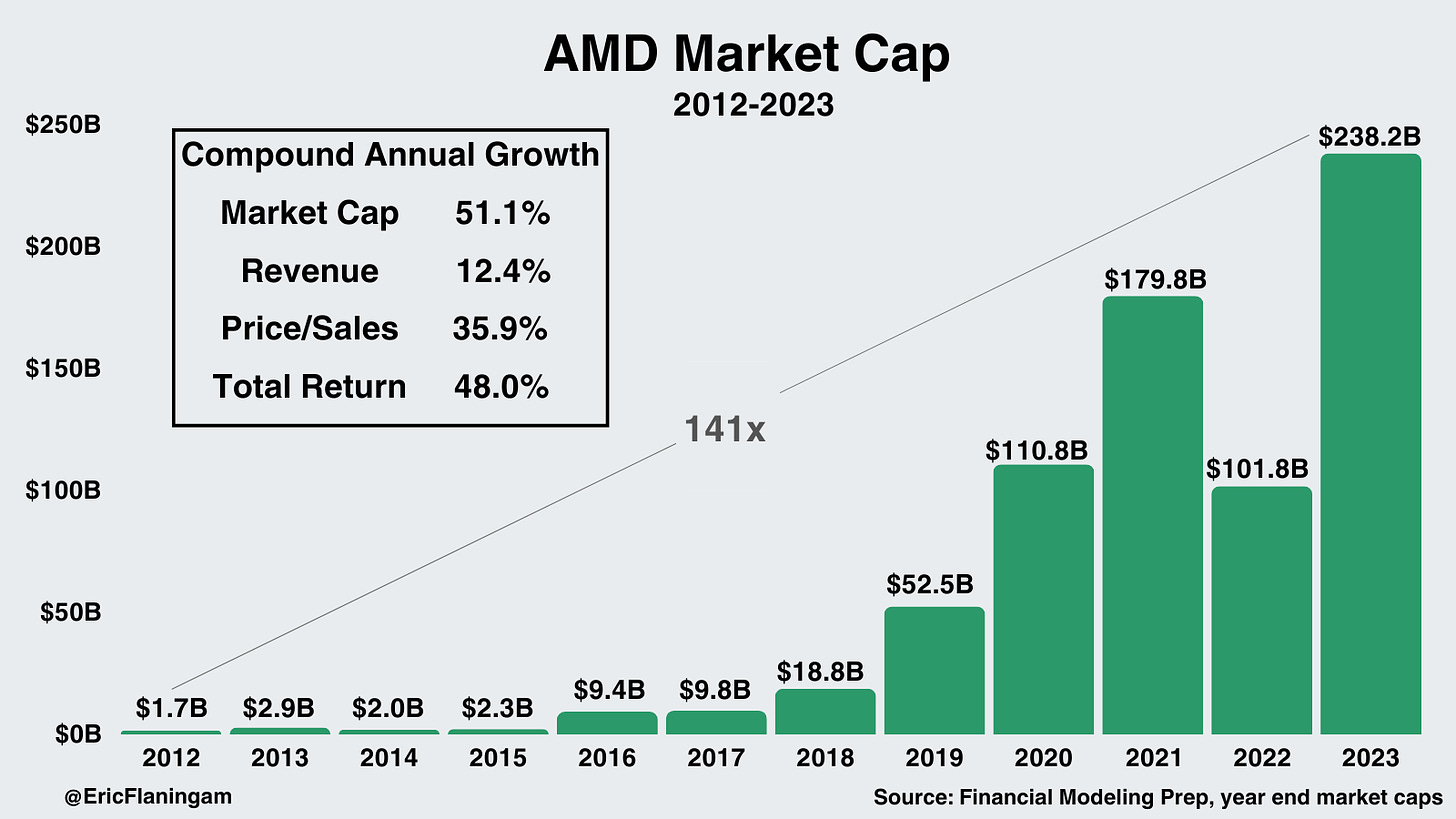
AMD의 EPYC 데이터센터 CPU 제품군은 계속해서 성공을 거두고 있으며, 최신 제품으로는 4세대 EPYC Genoa, Bergamo가 있습니다. 이러한 CPU들은 x84 아키텍처중 하나인 Zen 4 및 Zen 4c 아키텍처를 기반으로 합니다.
한편 인텔은 시장에서 여러 이야기가 나오지만, 비즈니스 혁신을 시도하고 있습니다. TSMC로부터 세계에서 가장 진보된 공정 노드 제조를 다시 탈환하고자 합니다(현재는 아직은 수율과 성능에 의심가는 3nm공정(i3)이지만, 1.8nm공정을 개발할 계획을 가지고 있습니다.) . 인텔 파운드리 서비스를 구축하기 위한 대대적인 노력이 진행 중입니다. 물론 최근 소식에 따르면, 인텔의 lunar lake 다음 제품인 Arrow lake를 100% TSMC에 맡기겠다하면서, 인텔 파운드리 분사 또는 매각이야기도 나오고 있는 중입니다.
(이부분의 자세한 이야기는 언젠가 파운드리 관련해서 글을 쓸 때, 역사를 정리하면서 써볼거 같네요.)
이러한 인텔은 CPU 시장 점유율을 방어하고, 인텔 파운드리 서비스를 구축하며, GPU 시장 점유율을 차지하기 위해 많은 노력이 요하고 있습니다.
반도체 컨설턴트인 제이 골드버그는 이렇게 말했다고 합니다. "AMD는 중요한 모든 지표에서 인텔을 앞서고 있으며, 인텔이 제조 방식을 고치고 새로운 제조 방법을 찾지 않는 한 계속 그렇게 할 것입니다."
다만 최근 다모다란 교수님은 "현재 보다 조금 더 정상적인 마진으로만 돌아간다면 즉 3% 성장과 25% 영업 마진만으로 돌아간다면 가치평가(DCF)를 해보면 인텔의 주당 가치는 이미 $23.70이기에 저평가되어 있다"라고 이야기했습니다.
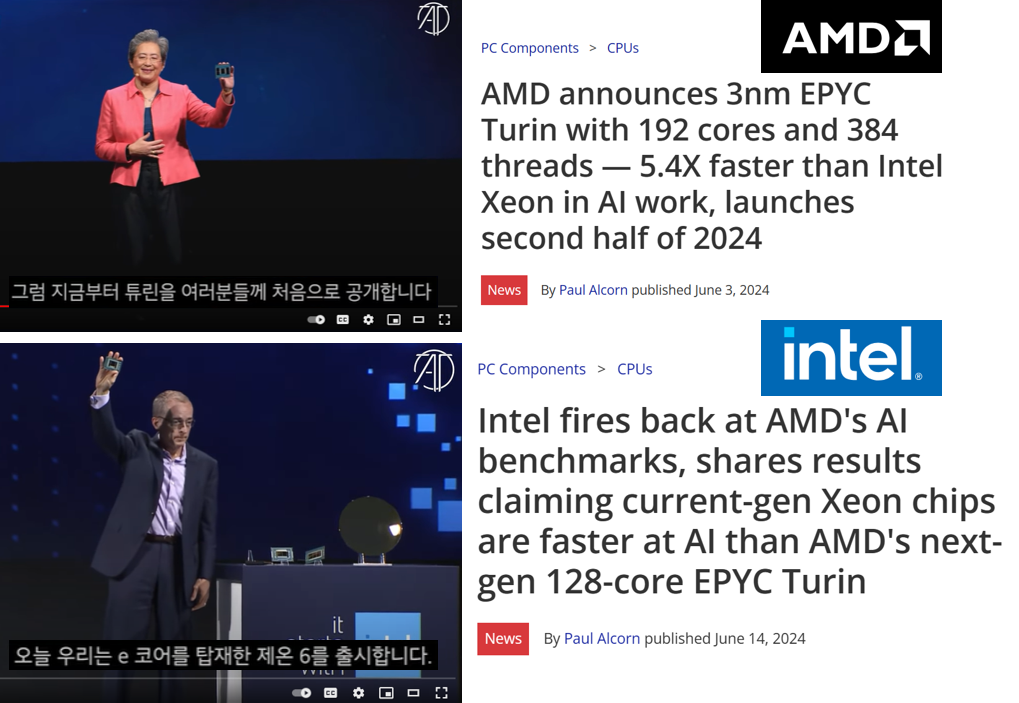
뿐만 아니라, 2024년도 computex에서 두 회사는 각각 EPYC Turin과 Xeon 6를 공개했습니다. 공개한 이후에 AI 벤치마크에서 AMD사의 CPU 성능이 인텔사보다 좋다라는 결과가 나왔었으나, 그 후 6월 14일에는 오히려 인텔사가 AMD사의 CPU성능보다 더 좋다라는 반박뉴스가 나올 정도로 이 CPU 시장은 GPU 못지않게 전쟁중입니다.
*TFLOPS (Tera Floating Point Operations Per Second)
TFLOPS는 테라플롭스라고 읽으며, 이는 1초에 수행할 수 있는 1조(=1 테라)의 부동소수점 연산(Floating Point Operations)을 의미합니다. TFLOPS는 컴퓨터나 가속기의 연산 능력을 측정하는 지표로, AI 모델의 학습이나 추론과 같은 수치 연산이 많은 작업에서 매우 중요한 성능 지표입니다. 숫자가 클수록 더 많은 연산을 빠르게 처리할 수 있다는 의미입니다.
CPU 및 GPU 성능 비교 사이트:
2. 점유율을 높여가는 Arm 기반 서버
또 다른 트렌드는 Arm 기반 프로세서입니다. 수년 동안 Arm은 효율성으로 인해 스마트폰에 선호되는 아키텍처였습니다. 최근에는 이러한 추세가 데이터 센터에도 이어지고 있습니다.
여기서 아키텍처(Architecture)는 컴퓨터 하드웨어 또는 소프트웨어 시스템의 구조를 설계하고 구현하는 방식입니다.(한마디로 레시피로 비유할수 있습니다.)
대표적인 예와 그들의 장단점은 다음과 같습니다:
x86 아키텍처
Intel과 AMD가 주로 사용하는 아키텍처로, 고성능 데스크톱과 서버 환경에서 널리 사용됩니다. CISC (Complex Instruction Set Computing) 명령어 집합을 기반으로 복잡한 명령을 단일 명령으로 처리할 수 있는 구조입니다.
장점: 높은 호환성을 가졌고 고성능 컴퓨팅에 적합.
단점: 설계가 복잡하고, 에너지 효율성이 떨어짐.
ARM 아키텍처
ARM Holdings가 개발한 RISC (Reduced Instruction Set Computing) 기반 아키텍처로, 주로 모바일 기기와 임베디드 시스템에서 사용됩니다. 낮은 전력 소모를 중시하여 설계되었습니다.
장점: 저전력 설계로 배터리 수명이 중요한 기기에서 유리하고 그래서 모바일에서부터 서버까지 다양한 제품에 적용 가능.
단점: x86에 비해 고성능 컴퓨팅에서의 한계가 있을 수 있고, x86 기반 소프트웨어와의 호환성이 제한적일 수 있음.
RISC-V 아키텍처
오픈 소스 기반의 RISC 아키텍처로, 누구나 자유롭게 사용할 수 있는 명령어 집합을 제공합니다. 점점 더 다양한 분야에서 사용되고 있으며, 임베디드 시스템부터 고성능 컴퓨팅까지 확장되고 있습니다.
장점: 커스터마이징 가능하며, 임베디드부터 서버까지 광범위하게 사용될 수 있음.
단점: ARM이나 x86에 비해 소프트웨어 및 하드웨어 생태계가 아직 성숙되지 않고 아직 성능에 한계가 있음.
MIPS 아키텍처
MIPS Technologies에서 개발한 RISC 기반 아키텍처로, 주로 임베디드 시스템과 네트워크 장비에서 사용됩니다.
장점: 단순성 & 저전력
단점: 시장 점유율 감소 & 호환성 문제
Power 아키텍처 (IBM)
IBM이 개발한 고성능 RISC 기반 아키텍처로, 주로 서버 및 슈퍼컴퓨터에서 사용됩니다.
장점: 병렬 처리 및 고성능 컴퓨팅에서 탁월한 성능을 발휘함; 고성능 서버와 슈퍼컴퓨터에 적합.
단점: 전력 소모량과 비용이 매우 높음
아마존이 이러한 움직임을 주도하고 있습니다. 아마존은 2018년에 처음으로 Graviton 프로세서를 출시했습니다. 그 이후로 데이터센터 CPU 출하량의 약 3~4%까지 성장했습니다. 신생 칩 업체 중 하나인 Ampere Computing도 상당한 시장 점유율을 확보하고 있습니다. 또한 Nvidia는 최근 최초의 데이터센터 CPU인 Grace 칩 라인을 출시했습니다. Microsoft와 같은 다른 회사들도 Arm 기반 CPU를 만들고 있습니다.
3. 맞춤형 실리콘(Custom Silicon)으로의 이동
이것은 CPU 뿐만이 아니라, GPU에서도 보이는 트렌드로 범용 CPU나 GPU와 달리, 특정 용도나 고객의 요구에 맞춰 설계된 반도체 칩으로 보다 더 높은 성능과 효율성을 얻을수 있습니다. 대표적인 예시로는 Apple의 M1 칩, Google의 TPU 그리고 방금 언급한 Amazon의 Graviton 프로세서 등이 있습니다.
이러한 트렌드는 대형 기술 기업들이 자체적으로 맞춤형 칩을 개발하거나 주문하기 시작하면서, 범용 칩들의 수요가 감소할 가능성이 있기 때문에 전통적인 제조사들에게는 불리할 수 있죠.
GPU시장
GPU 시장은 현재 엔비디아가 주도하고 있습니다. 그들은 이를 유지하기 위해 공격적으로 투자하고 있습니다.
(Nvidia에 대해서는 밸류포커스 코너에서 전편, 후편으로 구성되어 있기에 간단하게 이야기하겠습니다.
전편: 기업해부학 - (1) AI 메가트렌드의 핵심, Nvidia - 1(Studio Valley - 독점 콘텐츠 | Valley AI)
후편: 기업해부학-(1) AI 메가트렌드의 핵심, Nvidia 기업분석 - 2편(Studio Valley - 독점 콘텐츠 | Valley AI))
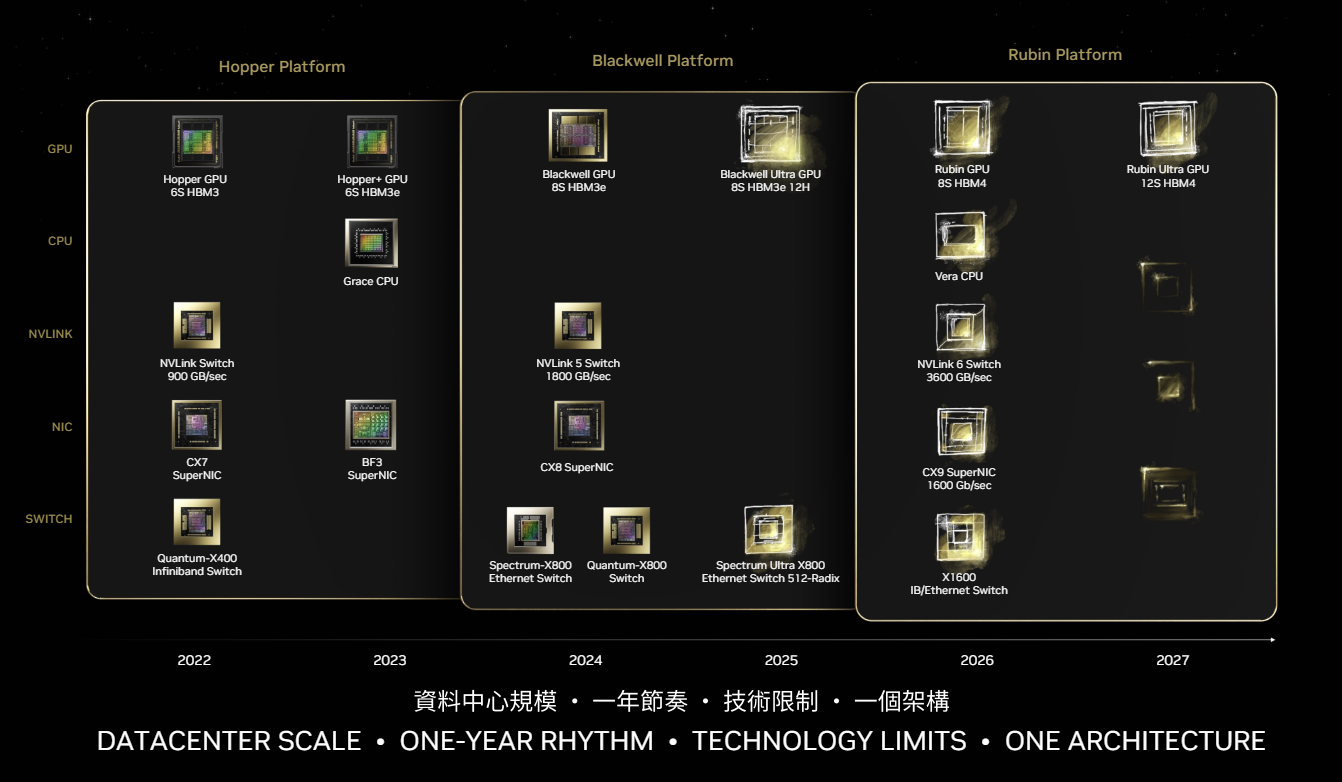
현재 데이터센터 GPU의 주요 경쟁자는 AMD의 Instinct MI300 시리즈입니다. 이 해당 GPU는 Nvidia의 H100과 경쟁하고 있습니다. Microsoft는 AMD 성능이 Nvidia보다 좋다는 이야기를 하였고, Oracle은 AMD의 강세가 보인다라는 이야기를 했습니다. AMD는 현재 데이터센터 GPU가 2024년에 3.5B 달러의 수익을 창출할 것으로 예상하고 있습니다. 인텔도 Habana Gaudi2 GPU를 통해 데이터센터 GPU를 제공하고 있으며, 분석가들은 내년에 850M 달러의 매출을 올릴 것으로 예상하고 있습니다. 다만 여전히 GPU 시장에서 Nvidia의 GPU 성능은 최고라는 것이 일반적인 평입니다. 이번에 나올 블랙웰의 성능 또한 엄청날 뿐 만 아니라, 올해 하반기 blackwell을 시작으로 매년 다음 단계의 GPU를 개발하여, 경쟁사들을 압도하겠다는 로드맵을 2024 computex에서 보여주었습니다. 또 그들 GPU의 아키텍쳐인 CUDA가 시장점유율을 유지하게 하는 주요한 원인 중 하나로 꼽히고 있죠;
CUDA는 하드웨어 아키텍처이자, 소프트웨어 아키텍처이다
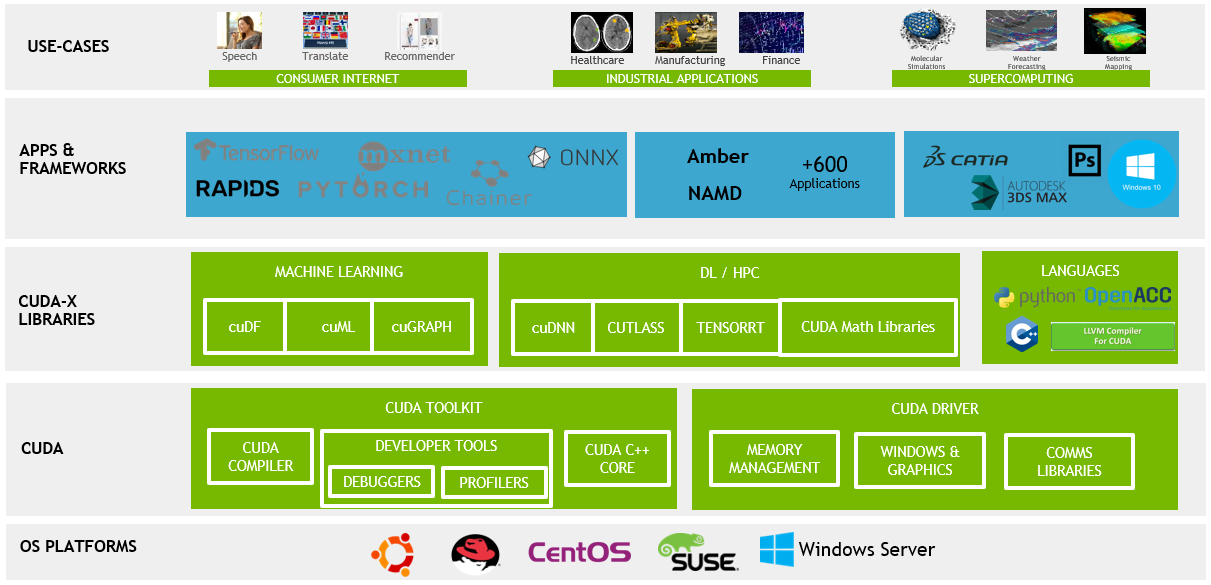
CUDA(Compute Unified Device Architecture)는 단순한 병렬 컴퓨팅 플랫폼이 아닙니다. 이는 NVIDIA가 개발한 혁신적인 하드웨어와 소프트웨어 아키텍처의 결합으로, GPU의 성능을 극대화하면서 컴퓨팅 작업을 효율적으로 처리할 수 있게 합니다.
CUDA는 하드웨어 아키텍쳐이기에, NVIDIA의 GPU를 기반으로 설계되었습니다. GPU는 앞선 설명과 같이 수천 개의 코어를 갖추고 있으며, 이는 대규모 데이터를 동시에 병렬적으로 처리하는 것을 목적으로 한 processing unit입니다. CUDA 하드웨어 아키텍처는 이러한 대량의 GPU 코어들을 병렬 연산을 처리할 수 있게 설계된 아키텍쳐입니다.
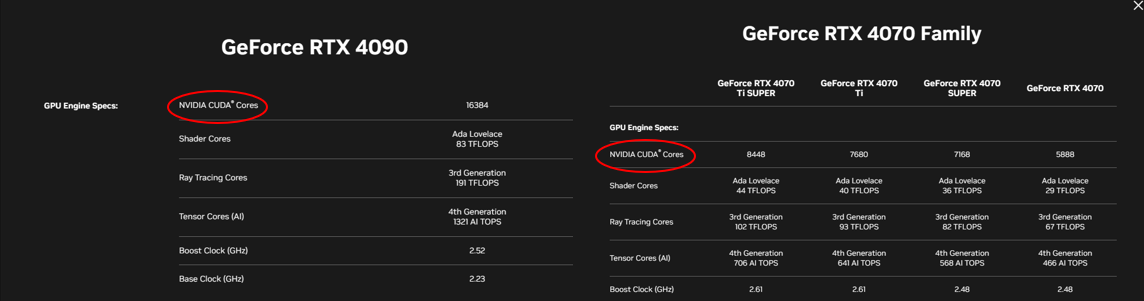
AI용 말고 개인 PC에 들어가는 그래픽카드를 구매하기위해, 스펙을 따져보면 다음과 같이 CUDA cores가 있음을 알 수 있습니다.
(이런 코어들이 많을수록 병렬연산 처리할수 있는 일손이 많아져 성능이 좋다는 걸 이야기한다고 하죠.;)
이런 CUDA가 AI로 넘어가지면서 CUDA 생태계라는 중요한 특성이 생겼는데, 이는 CUDA가 바로 소프트웨어 아키텍쳐이기도 한다는 점이죠. 하드웨어 아키텍처가 GPU의 병렬 처리 능력을 제공하는 데 집중한다면, CUDA의 소프트웨어 아키텍처는 그 성능을 프로그래머가 쉽게 활용할 수 있도록 만들어 줍니다. CUDA는 고급 병렬 처리를 요구하는 작업에서도 프로그래밍의 유연성을 제공합니다.
CUDA 소프트웨어 아키텍처는 GPU와 CPU 간의 상호작용을 효율적으로 관리합니다. 프로그래머는 CPU에서 실행되는 코드를 작성한 후, 특정 연산을 GPU로 오프로드할 수 있으며, CUDA는 이러한 프로세스를 자동으로 최적화합니다. 즉, 병렬 처리를 위한 복잡한 하드웨어 제어는 CUDA가 담당하며, 개발자는 CPU에서 사용하는 C, C++ 또는 Python 같은 익숙한 언어로 코드를 작성할 수 있습니다.
CUDA 소프트웨어는 GPU의 연산 능력을 쉽게 활용할 수 있도록 다양한 라이브러리와 프레임워크를 제공합니다. 예를 들어, cuBLAS와 cuDNN 같은 라이브러리는 고성능 연산을 위한 함수들을 미리 최적화해 제공하며, 이를 통해 개발자는 복잡한 알고리즘을 효율적으로 처리할 수 있습니다. 이러한 소프트웨어 아키텍처는 하드웨어의 복잡성을 숨기고, 개발자가 병렬 처리 작업에 집중할 수 있도록 돕습니다.
이런 CUDA는 2006년 부터 개발되어, 현재 CUDA의 가장 큰 강점은 하드웨어와 소프트웨어가 긴밀하게 통합되어 있기에 타사 GPU나 범용 컴퓨팅 장치에서는 찾아볼 수 없는 고유한 성능 우위를 제공합니다.
그들의 라이브러리에 있는 다양한 프레임워크를 통해 AI 훈련이나 딥러닝 같은 복잡한 작업에서 빠른 속도와 높은 효율을 제공합니다. 뿐 만 아니라, 이런 아키텍쳐는 확장성 면에서도 매우 강력하고, 지속적으로 미래컴퓨팅 환경의 요구에 맞춰서 진화하고 있으며, 그렇기 때문에 CUDA가 현재 AI 분야의 사실상 표준으로 자리잡아,...