
적랑
구독자 341명구독중 42명
논리 기반 사고
AppLovin Corporation은 마케팅 플랫폼
기업이 전 세계 잠재고객에게 도달하고 수익을 창출하며 성장할 수 있도록 엔드투엔드 소프트웨어 및 인공지능(AI) 솔루션을 제공
업스타트 홀딩스는 인공지능(AI) 대출 마켓플레이스
플랫폼에는 개인 대출, 자동차 소매 및 재융자 대출, 주택 담보 신용 한도(HELOC), 소액 대출이 포함
소비자 신용 인수 프로세스에 인공 지능 모델과 클라우드 애플리케이션을 적용
LLM/Agent의 범용성이 확대되는 시점에서, 기업의 "특화 모델(Specialized Model)"이 생존하려면 단순 성능 우위를 넘어 구조적 해자(Data, Ops, Regulatory)를 증명해야 함
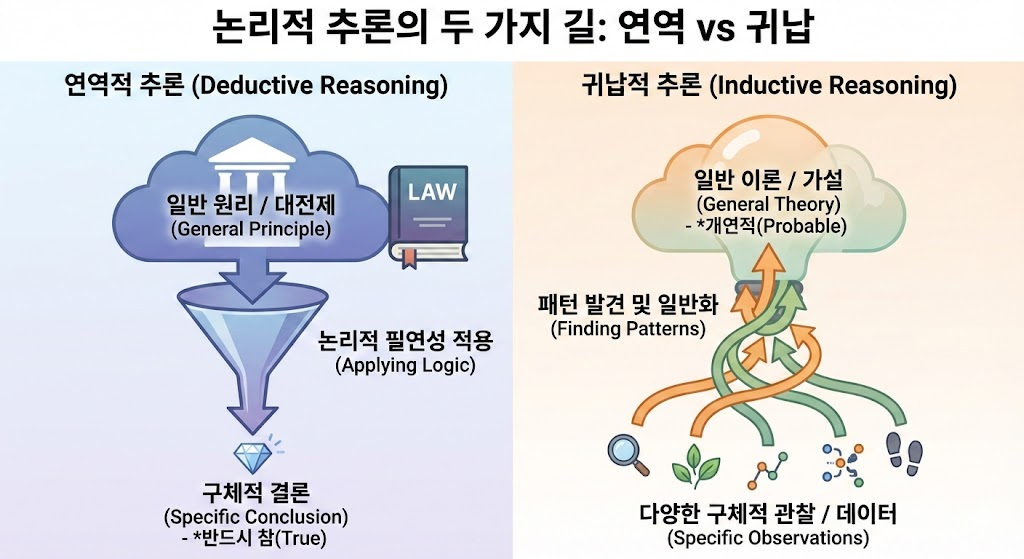
AI가 잘 하는 분야는 빅데이터에서 패턴을 찾아내는 귀납적 추론 분야임
Transformer 아키텍쳐를 기반으로 하는 LLM 역시 다음에 나올 단어를 예측해 생성하는 귀납적 추론에 가깝지만 자연어를 학습한다는 특성 덕분에 연역적 추론을 어느 정도 모방
좋은 AI 모델이 나오기 위해서는 많은 요소가 필요하지만 단순화 한다면 3개 정도 꼽을 수 있음
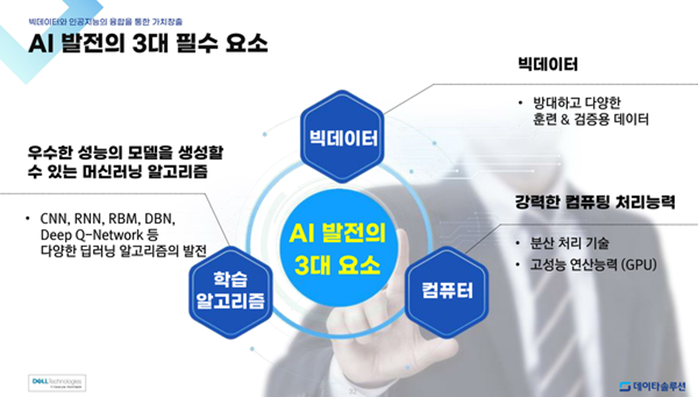
빅데이터, 학습 알고리즘, 컴퓨팅 파워 이렇게 3개가 필요함.
요새 많은 회사에서 AI를 적용한다고 하고 있음
자체 AI를 통해 효용을 내려면 필자는 3가지 정도에서 yes라는 답이 나와야 한다고 생각함
귀납(Induction)의 우위성: 데이터 누적이 압도적인 성능 차이로 직결되는가?
문제의 구조적 난이도: LLM/Agent가 침투해도 해결하기 어려운 시스템적 복잡성이 있는가?
플라이휠(Flywheel)의 강도: [예측 성공 → 유저 반응 → 데이터 축적 → 성능 향상]의 루프가 끊김 없이 돌아가는가?
LLM은 어느 분야에 특화됐다기 보다는 범용 AI에 가까움
물론 Finetuning 등을 통해 어떤 분야에 특화되게 만들 수 있겠지만 기본적으로 특정 분야를 더 잘 이해하도록 학습 하는 거지 특정 데이터만으로만 훈련하지는 않음
그럼에도 LLM은 우리 생활에 전방위적으로 쓰이고 있음
왜냐? LLM이 모방하는 연역적 추론 능력 만으로도 많은 효용을 가져다 주기 때문
이 LLM or Agent가 ...
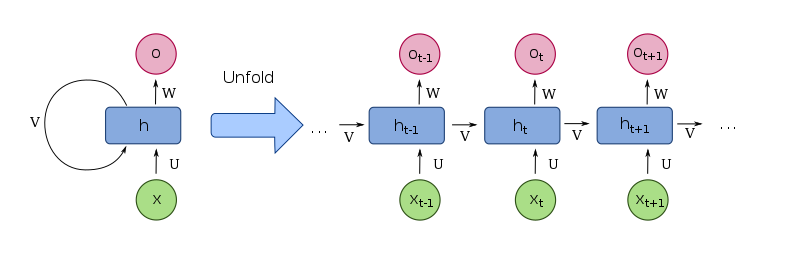

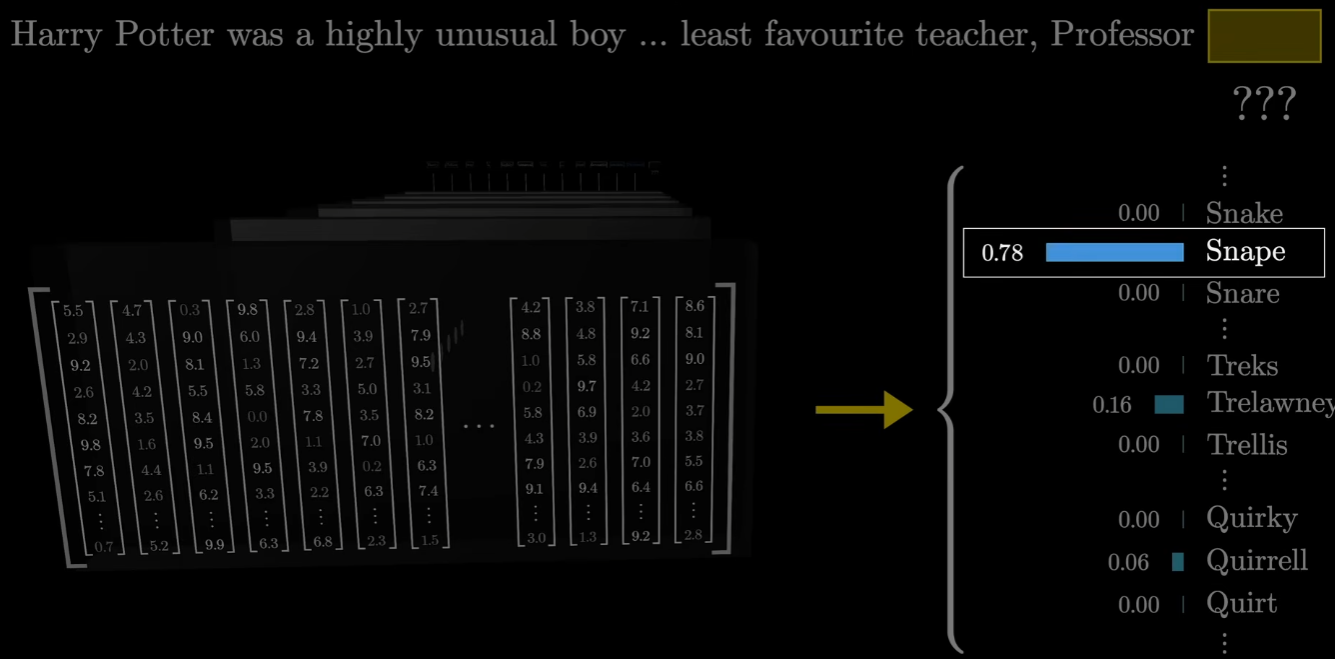
크, 인사이트 감사합니다