아모르파티
구독자 20명구독중 28명
신한투자증권 - 데이터컴 한식 뷔페 정리
최종 수요자인 빅테크 입장에서는 모델 학습기간이 제한되어 있다는 점도 문제. Epoch AI에 따르면 모델 학습에 6개월 이상이 소모되는 경우 경쟁사 대비 시장 선점 효과가 줄어들고, 하드웨어와 소프트웨어가 모두 쓸모 없어지게 될 위험이 존재
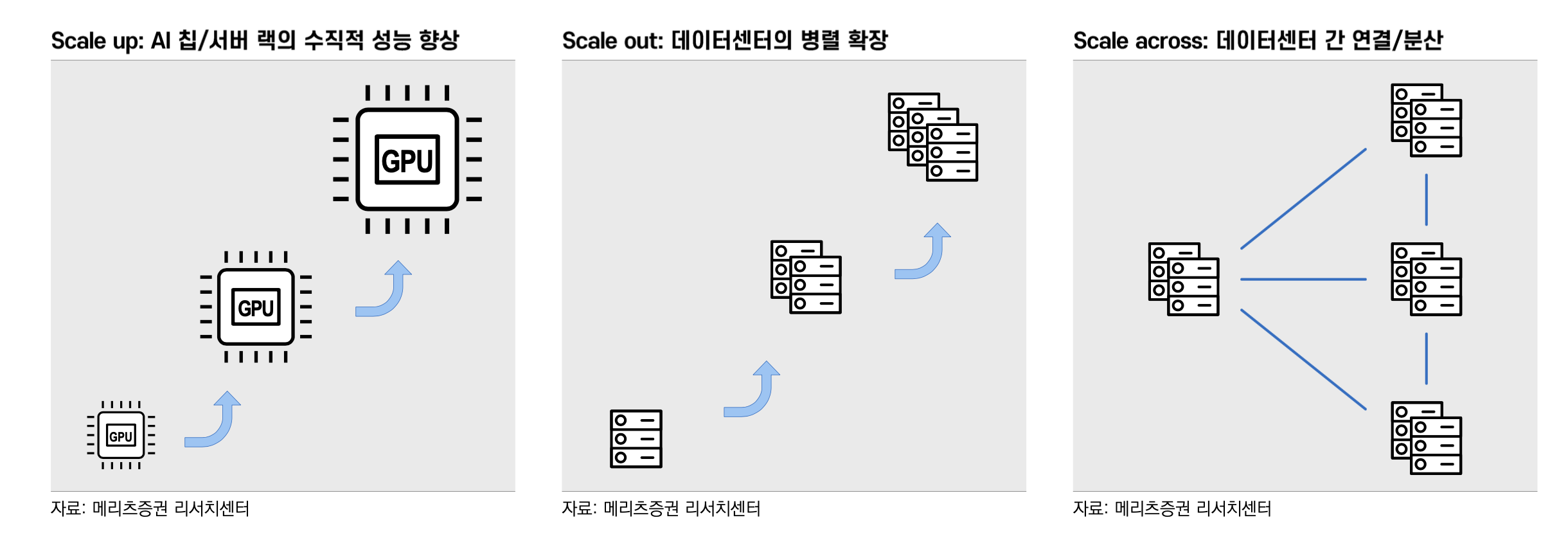
단일 노드에서 더 많은 연산량을 처리하면 된다! Scale-up은 개별 칩 성능을 개선하거나 여러 칩을 엮어 하나의 큰 서버처럼 쓰는 것을 의미
AI 모델 학습은 수 만개의 GPU 클러스터가 서로 다른 데이터를 학습하고 이에 대한 결과를 공유하는 방식으로 이뤄진다. 즉 더 많은 GPU 클러스터(=랙)를 투입할수록 전체 연산 속도가 높아진다.
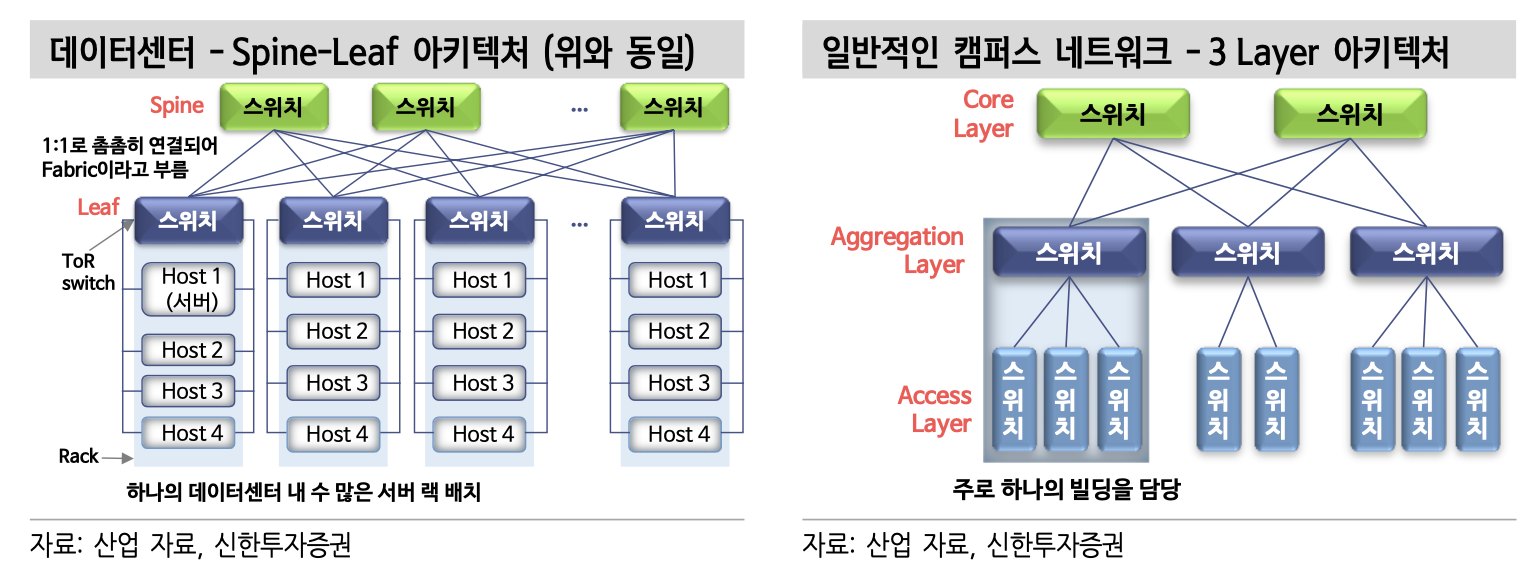
랙을 가장 효율적으로 연결하는 방법은 Spine-Leaf 아키텍처를 활용하는 것이다. Spine-Leaf 아키텍처는 랙 확장이 용이하고 모든 신호를 2 hop*만에 전달할 수 있다. Leaf 스위치는 각 랙 상단에 설치돼 해당 랙으로 오고 가는 신호를 처리하고, Spine 스위치는 Leaf 스위치 간 통신을 담당
모델이 너무 거대하면 이를 단일 데이터센터에 구현하기 어려울 수 있다. 전력 수급 이슈도 있다. 해당 지역에서 전력을 충분히 수급해올 수 없다면 지리적으로 떨어진 지역 간 데이터센터라도 연결해야 한다.
초거대 모델(>1T 파라미터)이 등장하면서 데이터센터 여러 개에 걸쳐 학습을 해야하는 경우가 생기고 있다. 이들 데이터센터 간에도 gradient를 빠르게 주고 받아야한다. 한편 이들 모델은 파라미터만 수백 GB~TB에 달해 추론 서비스를 제공하려해도 하나의 데이터센터에 모델 전체를 복사해놓기 어려울 수 있다.
전 세계 수 백만 사용자 요청에 빠르게 응답하기 위해서는 서버를 물리적으로 사용자 가까이에 두어야한다. 즉 모델을 여러 지역과 서버에 복제해 놓고 트래픽을 분산 배치해야한다. 문제는 AI 모델은 파일 크기가 크고 업데이트 주기가 짧다는 것이다. 원활한 배포(=동기화)를 위해서는 Scale-across 인프라를 구현해놓는 것이 효율적
일반적으로 AI 데이터센터는 Scale-up에 NVlink를, Scale-out에 인피니밴드(InfiniBand)를 채택.
인피니밴드의 상대 개념이 이더넷이다. 이더넷은 범용적이지만 통신 과정에서 CPU가 패킷을 여러 번 복사해 AI 학습에는 적합하지 않다. 예를 들어 유튜브 시청을 하는 동안 카카오톡 채팅을 한다고 상상해보자. 이더넷 NIC(네트워크 칩)가 유튜브 동영상 ...