
슈크림빵
구독자 218명구독중 17명
AI Engineer로 일하고 있습니다.
안녕하세요, 슈크림빵입니다.🧁
미국이 중국에 AI 칩을 안 팔면, 중국은 어떻게 할까요? 답은 의외로 단순했습니다.
칩을 못 늘리니까, 비트를 쪼갠 거예요.(비트주세요! 드랍 더 비트~)
화웨이가 최근 발표한 HiFloat4라는 4비트 데이터 포맷 이야기인데요, 같은 칩에서 이론상 4배 더 많은 연산을 뽑아내겠다는 전략이에요.
논문 두 편을 중심으로, AI 전문가가 아니어도 따라올 수 있게 정리해보았습니다!
AI 모델을 돌리려면 GPU 같은 고성능 칩이 필요합니다.
그런데 미국이 2022년부터 중국에 이 칩을 안 팔고 있어요.
Nvidia H100은 수출 금지, 중국 시장용으로 성능을 낮춘 H20마저 2025년 4월부터 수출 허가가 필요해졌어요.
자체 제조도 쉽지 않아요. 중국 최대 파운드리 SMIC은 7nm 공정에 묶여 있고, Nvidia가 쓰는 4nm TSMC 공정과는 세대 차이가 나요.
화웨이의 2025년 AI 칩 생산량은 약 20만 개로 추정되는데, 이는 미국 생산량의 1~4% 수준이에요.
칩을 더 못 만드니까, 남은 선택지는 하나입니다. 가진 칩에서 더 많이 뽑아내는 것. 그 핵심 기술이 HiFloat4예요.
AI 모델 안에서는 수많은 숫자(가중치)가 돌아다녀요. 이 숫자 하나를 표현하는 데 몇 비트를 쓰느냐가 정밀도예요.
BF16 (16비트): 현재 표준. 숫자 하나에 16비트.
FP8 (8비트): 절반으로 줄임. 이미 상용화됨.
FP4 (4비트): 또 절반. 같은 칩에서 이론상 4배 연산, 4배 메모리 절약.
당연히 비트가 줄면 숫자를 덜 정확하게 표현하니까 모델 성능이 떨어져요. 핵심은 "얼마나 적은 손실로 4비트를 쓸 수 있느냐"예요.
HiFloat4 이전에도 4비트 포맷 시도가 있었어요. 논문에서 세 가지를 비교하고 있어요.
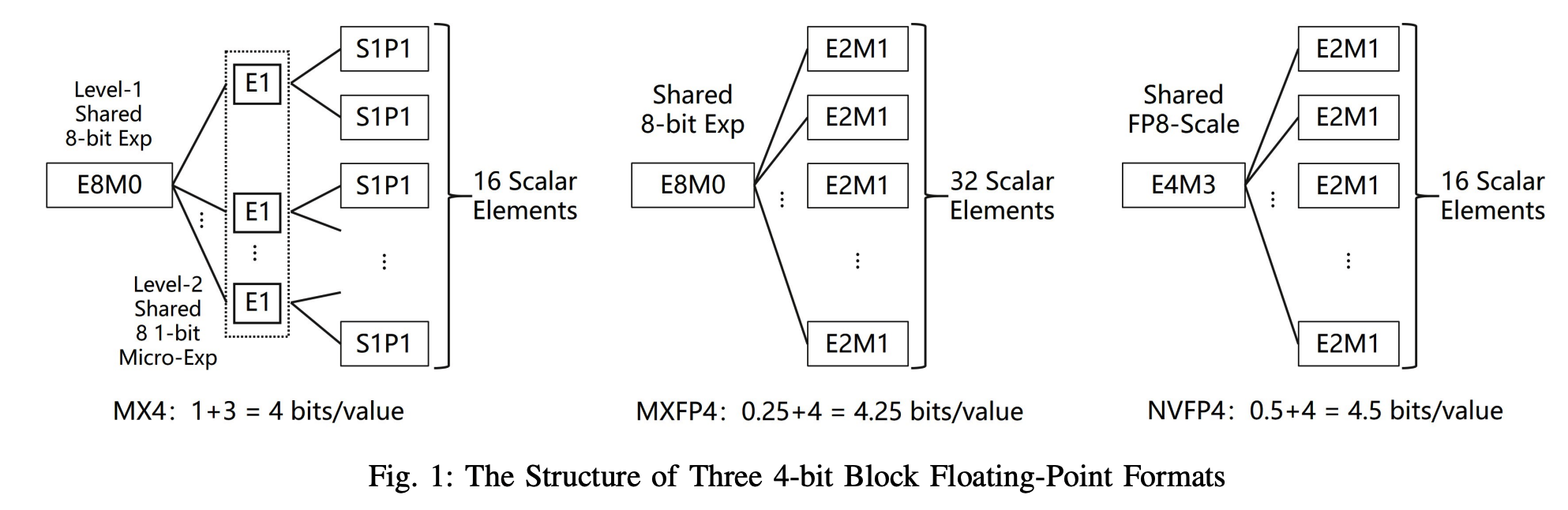
세 가지 4비트 BFP 포맷(MX4, MXFP4, NVFP4)의 구조를 나란히 비교한 그림. 각 포맷이 숫자를 어떤 식으로 쪼개서 저장하는지 보여줍니다.
MX4 (Microsoft/Meta)
그룹 크기가 16개로 작고, 메타데이터 오버헤드가 커서 실제 데이터를 3비트로 줄여야 했어요. 결과적으로 정밀도가 너무 낮아서 AMD도 채택을 포기.
MXFP4 (Open Compute Project)
Nvidia, AMD, 화웨이까지 채택한 업계 표준. 그룹 크기를 32로 늘리고 개선했지만, 가중치(weight)에만 쓸 수 있고 활성화(activation)에는 정밀도가 부족해요. 즉 4비트 연산력의 절반만 활용 가능.
NVFP4 (Nvidia Blackwell)
활성화에도 쓸 수 있게 만든 Nvidia의 독자 포맷. 하지만 두 가지 대가가 있어요. 첫째, 다이나믹 레인지가 좁아서 소프트웨어로 추가 스케일링(PTS)을 해야 하고, 둘째, 그룹 크기가 16으로 작아서 행렬 연산 시 하드웨어 오버헤드가 큼.
정리하면, 기존 포맷들은 정밀도, 다이나믹 레인지, 하드웨어 효율 세 마리 ...





5%도 이해못한 것 같지만 두고두고 읽어봐야겠네요. 감사합니다!
미국이 중국에 AI 칩을 안 팔자, 화웨이는 칩을 더 만들 수 없으니 비트를 쪼개 4비트로 연산 효율을 높이는 HiFloat4를 만들었어요.
3단계 계층 스케일링 덕분에 정밀도를 거의 잃지 않고, 같은 칩에서 더 많은 연산과 메모리를 절약할 수 있어요.
실제로 추론과 학습 모두 4비트로 안정적으로 동작하고, 하드웨어 면적과 전력도 줄어 효율적이에요. 결국 요약하면, “가진 칩으로 최대한 뽑아내겠다”는 전략이 실제 칩 설계와 로드맵에 구현된 혁신 사례입니다!

비트를 활용하는방법이 굉장히 인상적이네요, 거의 컴싸의 내핵이 이닌가.. 버츄얼메모리와 비슷한 원리인가요?
완전히 똑같진 않지만, “제한된 자원으로 더 넓은 범위를 다루는” 아이디어는 비슷해요.
예로 버추얼 메모리를 생각해보면, 물리 RAM이 부족할 때 디스크를 끌어다 쓰면서 페이지 테이블로 매핑해서 마치 메모리가 더 많은 것처럼 보여주잖아요. 핵심은 다단계 페이지 테이블처럼 계층적으로 간접 참조를 걸어서 넓은 주소 공간을 효율적으로 관리한다는 거예요.
HiFloat4도 이와 비슷해요. 4비트만 있으면 표현할 수 있는 숫자 범위가 되게 좁지만, 3단계 계층 스케일링(E6M2 → E1_8 → E1_16)을 쓰면 결국 69개의 binades라는 꽤 넓은 숫자 범위를 다룰 수 있어요.
그러니까, 다단계 페이지 테이블이 적은 메타데이터로 큰 주소 공간을 매핑하듯, HiFloat4는 0.5비트 정도의 아주 작은 메타데이터로 넓은 숫자 범위를 매핑하는 거라고 보면 돼요.
차이라면, 버추얼 메모리는 “공간이 부족할 때” 해결하는 거고, HiFloat4는 “표현력이 부족할 때” 해결하는 거예요.
좀 더 쉽게 비유하면 허프만 코딩이나 부동소수점 설계랑 비슷해요. 제한된 비트 안에서 자주 쓰이는 범위에 정밀도를 집중하는 방식이죠.
결국 큰 그림으로 보면, “한정된 자원으로 어떻게 더 넓은 범위를 다룰까?”라는 문제는 컴퓨터 과학 거의 모든 곳에서 등장하는 질문이고, HiFloat4도 그 전통 위에서 나온 기술이에요!
정보를 적은비트에 넣고 빼고하는 과정에서 인코딩/디코딩이 매번 발생할텐데 그럼에도 4비트로 압축하는게 유리한건 그만큼 메모리에 병목이 심하다는 뜻일까요?
맞습니다!
메모리 병목이 그만큼 심하다는 뜻이에요. 업계에서는 이걸 "메모리 월(Memory Wall)"이라고 부르는데요.
AI 칩의 연산 속도는 세대마다 빨라지는데 메모리에서 데이터를 가져오는 속도가 못 따라가는 문제예요.
LLM 추론은 토큰 하나 생성할 때마다 수백 GB의 가중치를 메모리에서 읽어야 해서 특히 심하고요.
16비트를 4비트로 줄이면 읽어야 할 데이터가 1/4이 되니까, 같은 대역폭으로 4배 빨리 가져올 수 있어요.
인코딩/디코딩 비용은 당연히 있지만, HiFloat4의 마이크로 지수가 0 아니면 1이라 하드웨어에서 비트 시프트 한 번이면 끝나요. 거의 공짜에 가까운 디코딩 비용이죠.
결국 "변환 비용 ≪ 메모리 병목 해소 이득"이 압도적으로 성립하기 때문에 4비트가 유리한 거예요 😊