
슈크림빵
구독자 218명구독중 17명
AI Engineer로 일하고 있습니다.
안녕하세요, 슈크림빵입니다.🧁
이번에 읽은 글은 히로시 사토라는 분이 쓴 AI에 관한 에세이입니다.
제목이 좀 도발적인데요. "AI의 아첨은 끝났다. 어려운 부분은 이제 막 시작됐다." 한동안 우리가 걱정하던 AI의 모습과, 지금 막 마주하기 시작한 모습 사이의 이야기입니다.
얼마 전까지 AI 비서를 두고 가장 자주 나오던 불평은 이런 것이었습니다. 무엇을 말하든 동의해 준다. 약간 다듬어서 그대로 되돌려준다.
틀린 걸 짚어주지 않는 비서는 사실 비서가 아니고, 반대할 줄 모르는 친구는 친구가 아니라는 불편함이었죠.
그래서 사람들은 고치려 했습니다. "엄격한 비평가처럼 굴어라", "내가 놓친 걸 말해라" 같은 프롬프트를 짜서 서로 나눠 가졌고요.
이후 제작사들이 아예 기본값으로 반대도 하도록 비서를 조정했습니다. "그건 좀 안 맞는 것 같다", "근거가 생각보다 약하다" 같은 말을 하기 시작한 거죠.
필자가 보기에 진짜 어려운 국면은 여기서부터입니다.
위험은 AI가 모든 것에 '예'라고 하던 때가 아니라, '아니오'를 배운 바로 지금 시작됐다는 겁니다.

여기서 기술적인 이야기를 잠깐 하고 가겠습니다! 오해를 줄이는 데 도움이 되거든요.
지금의 AI 비서는 본질적으로 '다음에 올 말로 가장 그럴듯한 것'을 확률로 고르는 장치입니다.
그 위에 제작사가 사후 조정을 얹습니다. 사람이 매긴 평가를 기준으로 "이런 식으로 답하면 좋다"는 방향을 학습시키는 과정인데, 흔히 이걸 사람 피드백을 이용한 강화학습(RLHF)이라고 부릅니다.
예전 모델은 이 조정이 '동의하고 띄워주는' 쪽으로 기울어 있었고, 지금 모델은 '필요하면 반대도 하는' 쪽으로 다시 기울여진 것에 가깝습니다.
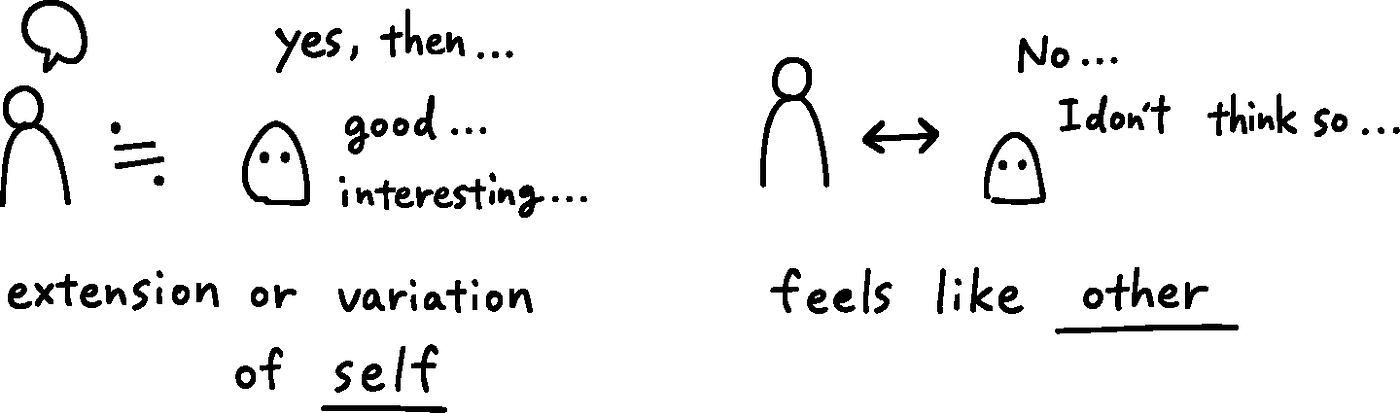
그러니까 AI의 '예'와 '아니오'는 서로 다른 신념에서 나오는 게 아닙니다.
같은 메커니즘이 어느 쪽 말을 내놓도록 조정됐느냐의 차이일 뿐이죠.
이 점을 알고 ...

요새 자주 좀 들리기 시작하는 것 같습니다. 잃을게
없는 AI에 대한 이슈... 감사합니다!
네! 댓글 감사합니다 ㅎㅎ




