
퀄리티기업연구소
구독자 1,439명구독중 113명
"투자의 질을 중시하며, 장기적 안목으로 시장을 바라봅니다. 비단 재테크뿐만 아니라 인생 전반에 걸쳐 복리의 힘을 믿고, 그 원칙을 실천에 옮기는 곳입니다. 여기서는 깊이 있는 분석과 지속 가능한 성장 전략을 공유하며, 함께 성장하는 지혜를 나눕니다."
데이터 레이크하우스는 2010년대 후반에 데이터 웨어하우스에 대한 보다 저렴하고, 오픈 소스이며, 유연한 대안으로 등장했습니다. 데이터 웨어하우스가 컴퓨팅/스토리지/서비스를 통합하는 반면, 레이크하우스 아키텍처는 이러한 서비스를 일반적으로 오픈 소스 소프트웨어를 기반으로 하는 개별 구성 요소로 나눕니다.
이 글은 다음과 같이 구성할 것입니다:
1. 데이터 레이크하우스 소개 및 모멘텀을 얻게 된 이유
2. 데이터 레이크하우스의 역사
3. 레이크하우스 기술 개요
4. 레이크하우스 시장 개요
5. 투자 환경에 대한 제 생각
항상 그렇듯이 저는 한 산업에 대한 전문가가 아니라 이 분야를 연구하는 투자자임을 밝히고 싶습니다. 제 목표는 산업을 이해하고 잠재적인 투자처를 찾는 것이며, 그 과정에서 배운 것들을 공유하고자 합니다.
1. 데이터 레이크하우스 소개
데이터 레이크하우스의 핵심은 데이터 웨어하우스를 스토리지, 컴퓨팅, 서비스라는 기본 구성 요소로 세분화하는 것입니다. 이를 통해 기업은 자신이 선택한 도구(일반적으로 오픈 소스 소프트웨어)로 원하는 데이터 스택을 구축할 수 있습니다.
데이터 레이크하우스는 특정 기술이 아니라 아키텍처입니다. 데이터 레이크하우스는 데이터 관리 자체가 아니라 데이터 관리를 구조화하는 방법입니다.
데이터 가치 사슬에서 데이터 레이크하우스의 역할을 여기서 시각화할 수 있습니다:
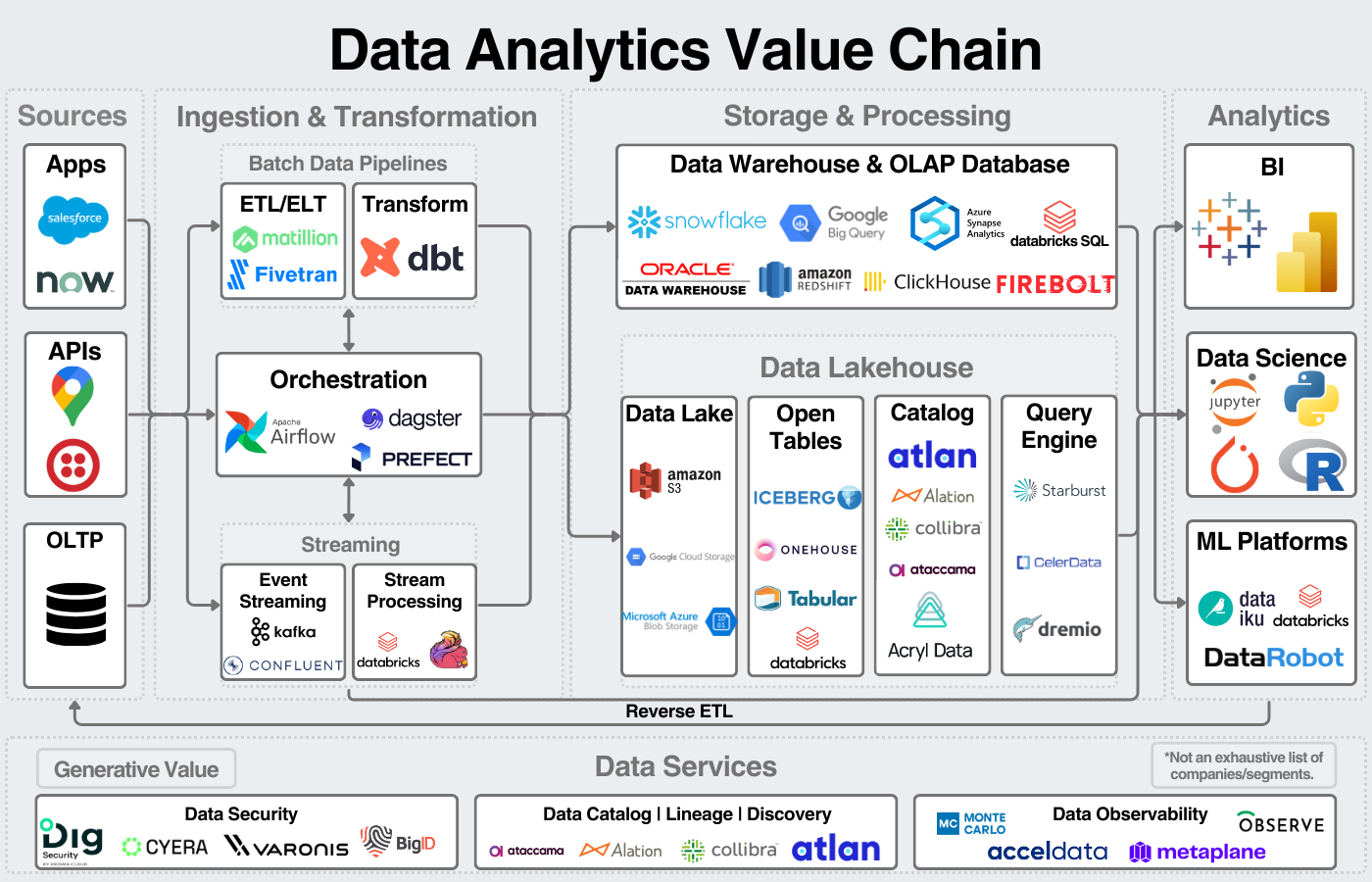
표면적으로 데이터 레이크하우스는 몇 가지 이유로 등장했습니다:
1. 데이터 웨어하우스는 비용이 많이 들고, 폐쇄적이며, 비정형 데이터를 잘 처리하지 못했습니다.
2. 데이터 레이크는 관리가 어려워서 데이터가 무질서해졌습니다.
레이크하우스는 데이터 레이크와 데이터 웨어하우스를 통합하여 데이터 관리를 하나의 플랫폼으로 중앙 집중화하고, 데이터 플랫폼을 오픈 소스 도구에 개방하며, 이론적으로 더 저렴한 가격으로 제공한다는 세 가지 주요 이점을 가져다주었습니다.
이론적인 우회를 허용하신다면, 레이크하우스의 출현은 클레이 크리스텐슨의 산업 진화에 대한 보다 근본적인 이론에서 비롯된 것이라고 생각합니다.
한 산업이 탄생하면 일반적으로 원천 기술을 개발한 수직적으로 통합된 단일 기업이 시장에 출시합니다. 이 기업이 수직적으로 통합되어야 하는 이유는 시장이 작은 기업이 시장의 일부를 차지하는 것을 정당화할 만큼 충분히 크지 않기 때문입니다. 시간이 지남에 따라 시장이 커지면 경쟁이 시장에 진입하여 수직적으로 통합된 회사의 방어력이 가장 약한 부분을 공격하는 것이 정당화됩니다.
일반적으로 이러한 현상은 시간이 지남에 따라 발생합니다. 수직적으로 통합된 기업은 핵심 IP와 가장 가치 있는 제품을 중심으로 후퇴할 때까지 수익성이 가장 낮고 방어력이 가장 낮은 사업 부문을 계속 분리할 것입니다. 저는 이것이 바로 기업의 진정한 가치 또는 '비장의 무기'라고 생각합니다. (기업을 연구할 때 제가 이해하려고 하는 핵심 질문이기도 합니다.)
제 생각에 레이크하우스의 진화는 산업의 진화를 보여주는 완벽한 예라고 생각합니다. 클라우드 기반 데이터 웨어하우스는 통합 데이터 서비스를 제공했지만, 레이크하우스는 이러한 패러다임을 깨고 데이터 웨어하우징 시장의 각 부문에 경쟁업체가 한꺼번에 진입할 수 있도록 했습니다.
2. 데이터 레이크하우스의 역사
데이터 분석 산업의 초창기에 대한 더 자세한 역사는 데이터 웨어하우스에 관한 저의 글을 읽어보실 수 있습니다. 여기서는 클라우드와 데이터 레이크의 등장부터 시작하겠습니다.
Hadoop, 클라우드, 그리고 빅 데이터의 부상
인터넷, 클라우드, 데이터 처리 프레임워크라는 세 가지 변수가 빅데이터 플랫폼의 부상으로 이어졌습니다.
인터넷의 부상으로 데이터는 그 어느 때보다 더 많이, 더 복잡해졌습니다. 기업들은 다양한 온프레미스 데이터베이스와 데이터 웨어하우스로 이 데이터를 관리하려고 했지만, 이러한 도구는 이러한 규모의 비정형 데이터에 적합하게 구축되지 않았습니다. '빅 데이터'가 부상하면서 기업들은 점점 더 많은 양의 데이터에 대한 분석이 필요하다는 것을 알게 되었습니다.
2006년에 오픈 소스 분산 데이터 처리 기술인 Hadoop이 출시되었습니다(여러 대의 컴퓨터에서 대량의 데이터를 처리할 수 있고 누구나 무료로 사용할 수 있음). Hadoop은 빅데이터 처리를 위한 소프트웨어 모음으로, MapReduce(처리 알고리즘), Hadoop 분산 파일 시스템(빅데이터 저장 시스템), YARN(작업 스케줄링)을 포함합니다.
비슷한 시기에 AWS는 첫 번째 제품인 심플 스토리지 서비스, 즉 Amazon S3를 출시했습니다. S3는 인터넷을 통해 액세스할 수 있는 비정형 데이터를 위한 저렴한 오브젝트 스토리지를 제공했습니다. 기본적으로 "무제한" 데이터 스토리지를 제공했습니다.
이 세 가지를 통해 기업들은 저장할 데이터, 저장할 방법, 처리할 방법을 모두 갖추게 되었습니다. 이로 인해 기업 데이터의 중앙 저장소인 데이터 레이크가 등장하게 되었습니다.
Apache Spark와 클라우드 데이터 웨어하우스
2000년대 후반, Spark는 UC 버클리의 한 팀에 의해 만들어졌습니다(이 팀은 나중에 데이터브릭스를 설립하게 됩니다). Spark는 Hadoop을 대체하는 데이터 처리 프레임워크를 제공했으며, 머신 러닝 모델 학습, 빅 데이터 쿼리, Spark Streaming을 통한 실시간 데이터 처리를 위해 데이터 과학 커뮤니티에서 빠르게 주목을 받기 시작했습니다. 데이터브릭스는 Spark의 최초 개발자들이 2013년에 설립한 회사입니다(델타 레이크와 MLflow도 개발했습니다).
2012년, Amazon은 초기 클라우드 데이터 웨어하우스인 Redshift를 출시했습니다. 이 제품은 온프레미스 데이터 웨어하우스의 대안을 제시하며 초기 시장의 선두 주자가 되었습니다. 2년 후, Snowflake가 출시되었습니다. Snowflake는 컴퓨팅과 스토리지를 분리하여 컴퓨팅(쿼리 실행/처리 날짜)과 데이터 저장을 독립적으로 확장할 수 있게 했습니다. 이를 ...
![[IT] 데이터 웨어하우스 입문서 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F1012a29f-a4be-4d97-983e-6a2e988afb3c_1400x900.png)
![[IT] 클라우드 입문서 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa5dd9214-bd20-4ca4-902e-9acfecc83e67_1400x900.png)
![[IT] 데이터 센터 입문서 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F485fe217-a70d-4b7b-856d-55feda4941a0_1400x900.png)
![[IT] 사이버 보안 입문서 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F2ab35b19-b6ad-4c4d-9771-ede36a15a215_800x520.jpeg)
![[IT] 반도체 산업 입문서 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F87175303-b5c4-41e9-a98e-79f3b3a770de_1600x900.png)