
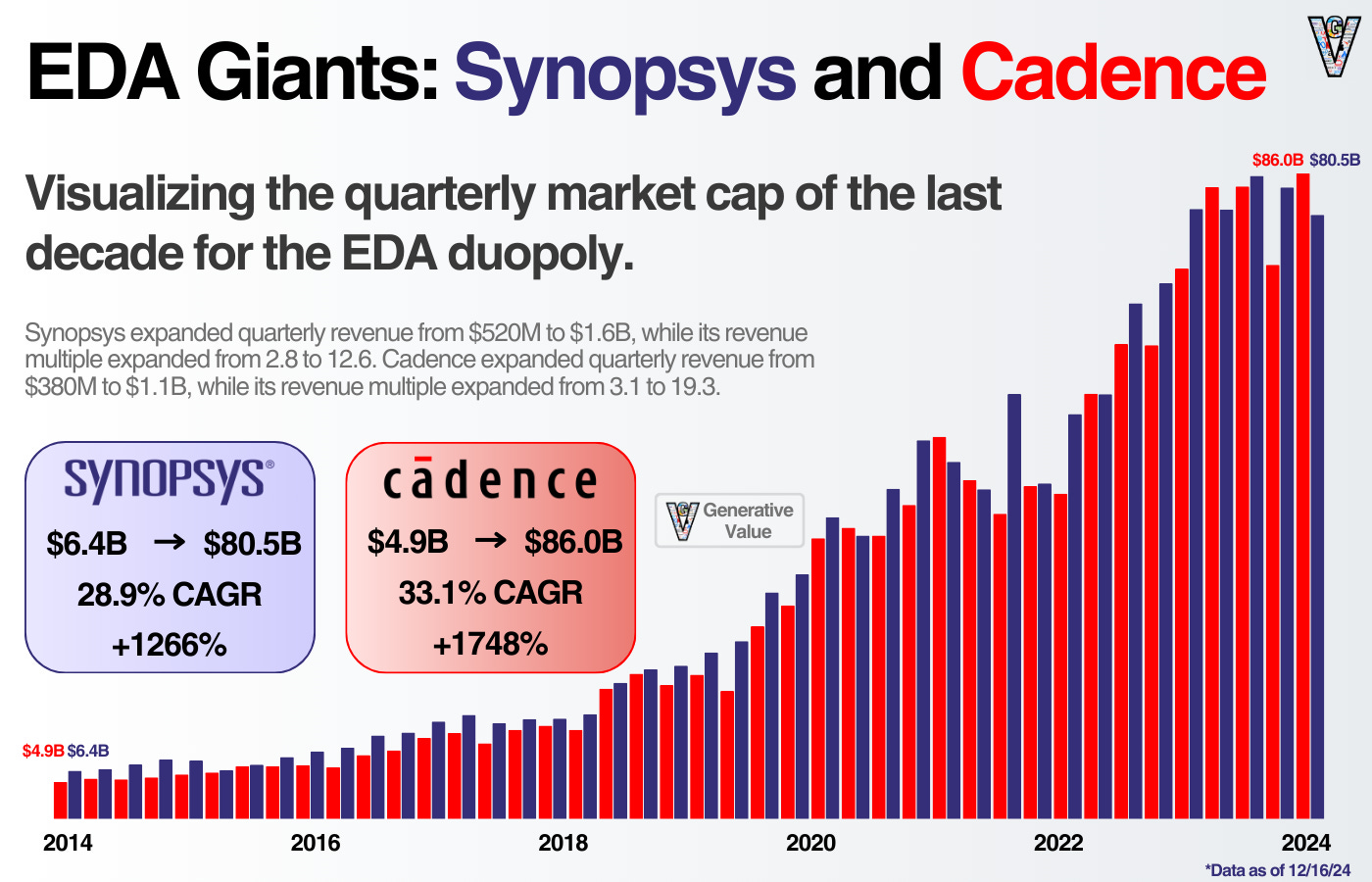
제네레이티브 밸류를 처음부터 꾸준히 읽어주신 분들께는 (첫째, 초기 기사를 읽게 해서 죄송합니다) 둘째, 초기 기사의 대부분이 데이터 산업에 관한 것이었습니다!
데이터는 투자자와 창업자 모두에게 훌륭한 분야였습니다. 빅 테크부터 리틀 테크(초기 단계의 스타트업), Snowflake & Databricks와 같은 데이터 플랫폼(중견 테크?)에 이르기까지, 기업들은 수백억 달러 상당의 데이터 제품을 판매하여 소프트웨어의 부상을 촉진했습니다.
제 데이터 기사 포트폴리오(데이터 산업, 데이터 웨어하우스, 데이터베이스, 데이터 레이크하우스)에서 한 가지 눈에 띄는 격차는 비정형 데이터 환경입니다. 오늘 이 문제를 해결하려고 합니다.
이보다 더 좋은 타이밍이 있을까요! 지난주 Jensen은 “일반 로보틱스를 위한 ChatGPT의 순간이 얼마 남지 않았습니다.”라고 말했습니다. Nvidia는 실제 세계 모델인 Cosmos를 출시했습니다. SpaceX는 점점 더 많은 지리 공간 데이터를 생성하며 빠른 상승세를 이어가고 있습니다. 자율주행차와 차량은 계속해서 자율 주행에 가까워지고 있습니다.
그것만으로는 충분하지 않다면, 새로운 AI 애플리케이션의 물결은 비정형 데이터를 기반으로 구축됩니다! 또한 텍스트 데이터는 마지막 개척지라고 할 수 있습니다. 일리야는 “우리는 데이터의 정점에 도달했고 더 이상은 없을 것”이라고 말했습니다.
제 생각을 요약하면 다음과 같습니다:
1. 대량의 비정형 데이터를 효율적으로 처리할 수 있도록 비정형 데이터와 관련된 혁신이 점점 더 많아질 것입니다.
2. 데이터 플랫폼의 유통 네트워크에 가치가 창출될 것입니다(오픈소스의 캐치-22에 대해서는 나중에 자세히 설명하겠습니다!).
3. 대규모 비정형 데이터의 처리 및 저장과 관련된 매우 구체적인 문제를 해결하는 스타트업에게 가치가 창출될 것입니다.
더 자세한 내용이 궁금하신 분들을 위해 비정형 데이터 생태계와 현재 AI의 물결로 인해 가치가 창출될 수 있는 분야에 대해 심층적으로 살펴볼 예정입니다.
1. 비정형 데이터에 대한 간략한 소개
비정형 데이터는 SQL 데이터베이스에 표 형식으로 저장되지 않은 모든 데이터를 광범위하게 포괄합니다. 예를 들면 텍스트, 이미지, 오디오, 비디오, 센서, 지리공간 데이터 등이 있습니다.
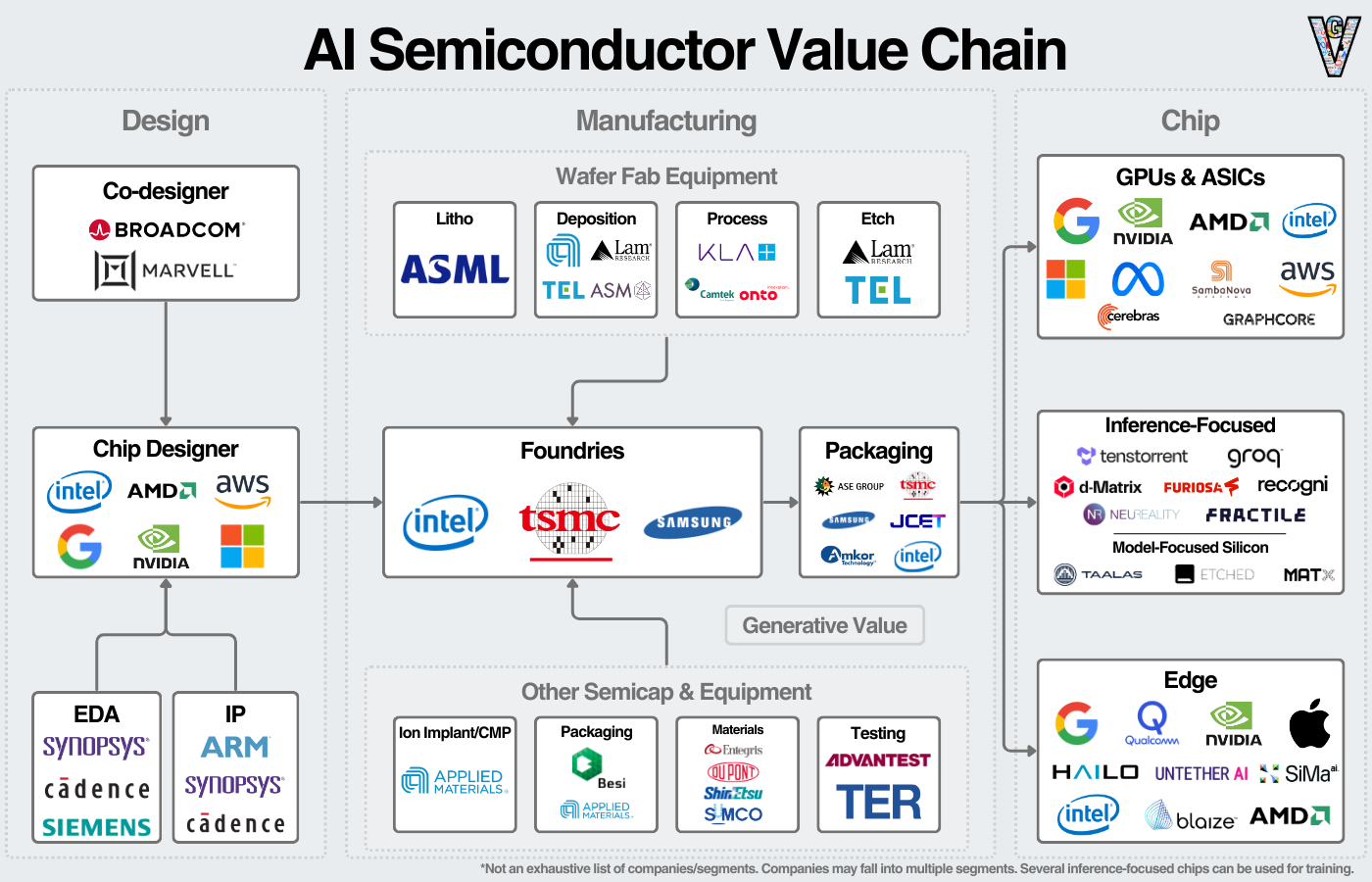
여기서 에코시스템을 시각화할 수 있습니다:

시장을 크게 다음과 같은 카테고리로 분류할 수 있습니다:
1. 소스: PDF, Word 문서, 이메일, 오디오 및 비디오와 같은 형식의 원시 데이터.
2. 수집: 소스에서 스토리지로 데이터를 옮기는 작업. 여기에는 소스에서 데이터 추출, 구문 분석(비정형 소스에서 정형 데이터 추출), 해당 데이터를 스토리지에 로드하는 작업이 포함됩니다.
3. 처리 및 변환: 원시 데이터를 분석할 수 있는 상태로 변환하는 작업입니다. 여기에는 정리, 중복 제거, 필터링, 임베딩이 포함될 수 있습니다. 복잡하거나 규모가 큰 데이터 세트의 경우, Spark, Flink, Ray 또는 Daft와 같은 컴퓨팅 엔진이 사용됩니다. 이러한 프레임워크는 데이터 작업을 보다 효율적으로 실행할 수 있는 수단을 제공합니다.
4. 스토리지: 비정형 데이터를 사용할 수 있도록 저장합니다. 대부분의 비정형 데이터는 클라우드 오브젝트 스토리지에 저장됩니다. 데이터는 객체를 가리키는 고유 ID와 함께 객체에 원시 데이터로 저장됩니다. 애플리케이션의 경우, 비정형 데이터는 NoSQL 또는 벡터 데이터베이스에 저장됩니다.
5. 최종 용도: 일반적인 사용 사례는 비정형 데이터의 일부 분석, 일부 애플리케이션 또는 모델 학습이나 추론을 위한 검색입니다.
더 깊이 들어가기 전에, 오늘날의 선두 주자인 MongoDB와 데이터브릭스의 발전을 포함하여 이 분야의 역사에 대해 논의해야 합니다.
2. 비정형 데이터의 요약된 역사
이 정보의 대부분은 여기에서 확인할 수 있는 데이터에 관한 일련의 게시물에서 나온 것입니다. 비정형 데이터의 증가는 크게 세 가지 추세로 이루어져 있습니다:
1. 비정형 데이터의 지속적인 기하급수적 증가.
2. 이러한 데이터를 저장하는 도구, 즉 NoSQL 데이터베이스.
3. 대량의 데이터를 처리하기 위한 도구, 즉 Apache Spark.
이러한 부상은 사실 인터넷에서 시작되었으므로 여기서부터 시작하겠습니다.
인터넷, NoSQL의 탄생, 그리고 “빅 데이터”의 부상
인터넷은 비정형 데이터의 확산으로 이어졌습니다. 점점 더 많은 웹사이트와 사용자가 주로 텍스트 형태의 데이터를 생성했고, 시간이 지나면서 비디오와 오디오로까지 그 범위가 확대되었습니다. 2000년대 들어 이러한 유형의 데이터를 처리하기 위해 MongoDB 및 Redis와 같은 NoSQL 데이터베이스가 등장했습니다.
데이터의 양이 증가함에 따라 기업들은 이 모든 데이터를 처리할 수 있는 방법이 ...

![[IT] AI 데이터 센터에 대한 입문서, 2부: 에너지 from EricFlaningam](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F64f40bf1-71b2-4c53-b141-589e1ae727bd_1272x821.png)

