
퀄리티기업연구소
구독자 1,408명구독중 112명
"투자의 질을 중시하며, 장기적 안목으로 시장을 바라봅니다. 비단 재테크뿐만 아니라 인생 전반에 걸쳐 복리의 힘을 믿고, 그 원칙을 실천에 옮기는 곳입니다. 여기서는 깊이 있는 분석과 지속 가능한 성장 전략을 공유하며, 함께 성장하는 지혜를 나눕니다."
존 폰 노이만 사후 80년이 지난 지금도 버스는 여전히 버스일 뿐이며, 현대의 트랜스포머 추론은 엔지니어링 기술로 우회할 수 있는 한계를 넘어 이 버스를 쥐어짜고 있다.
1945년, 존 폰 노이만은 프로세서와 메모리가 분리된 물리적 단위로 존재하며 버스로 연결되는 컴퓨터 아키텍처를 기술한 보고서 초안을 발표했다. 프로세서는 명령어나 데이터 조각을 가져오고, 연산을 수행한 뒤, 그 결과를 다시 메모리에 기록한다. 계산의 모든 단계는 버스를 가로지르는 왕복 여정을 요구한다.
그 버스가 바로 '폰 노이만 병목현상'이다. 이는 프로세서가 연산할 수 있는 속도와 메모리가 데이터를 공급할 수 있는 속도 사이의 간극을 의미한다. 1950년대 이후 제작된 모든 범용 컴퓨터는 이 아키텍처 내부에서 살아왔다. 현재 출하되는 모든 GPU, 모든 TPU, 모든 주문형 AI 가속기 역시 마찬가지다.
원제작 논문이 나온 지 80년이 지난 지금 이 문제가 다시 중요해진 이유는, AI 워크로드가 전통적인 엔지니어링으로 숨길 수 있는 수준을 넘어 이 병목현상을 극단까지 늘려놓았기 때문이다. 인공지능의 가격은 더 이상 칩이 초당 수행할 수 있는 부동소수점 연산 횟수(FLOPs)에 의해 결정되지 않는다. 메모리를 칩의 연산 장치 내부로 얼마나 빨리 이동시킬 수 있느냐에 의해 결정된다.
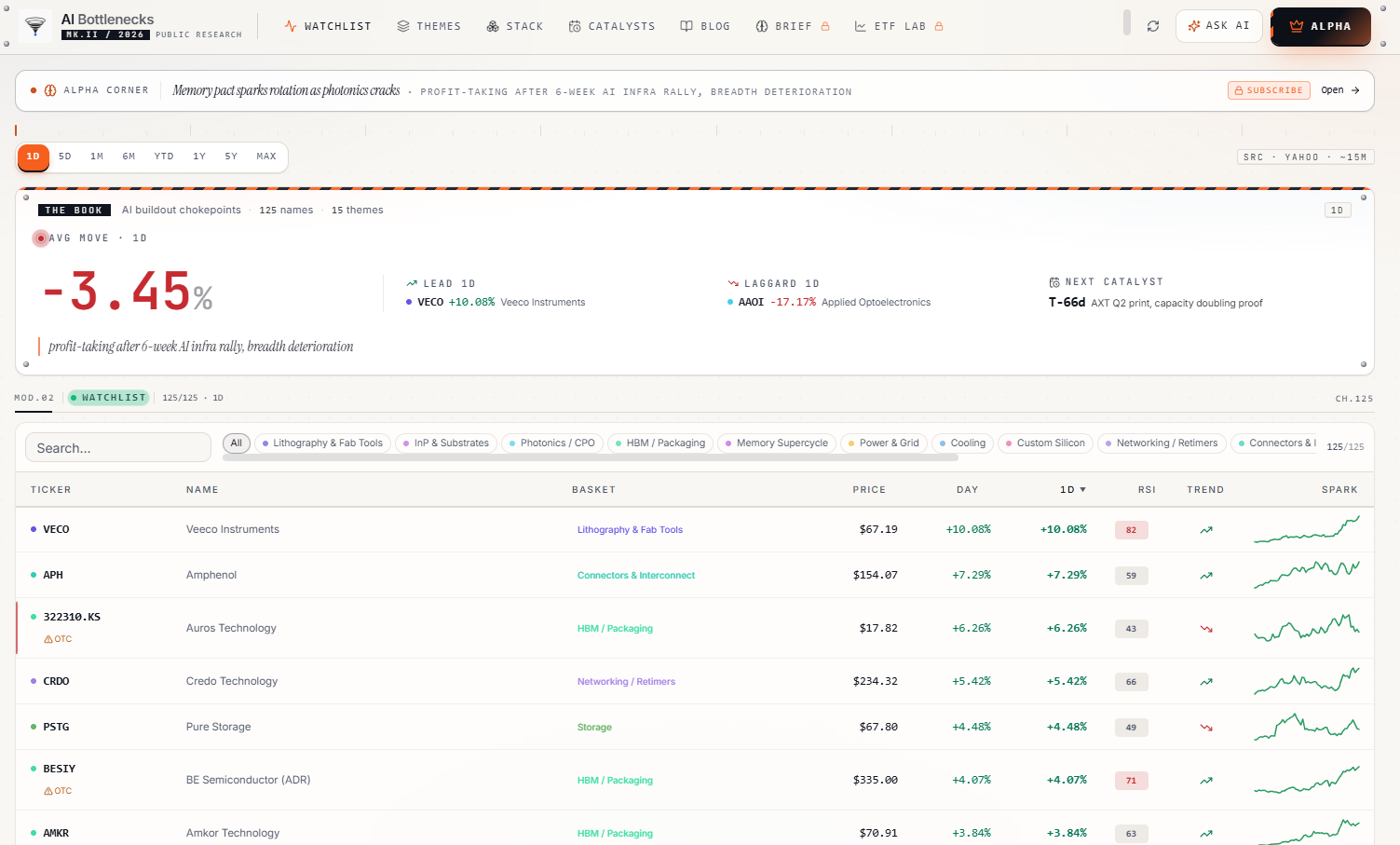
나는 대규모 추론을 실행하는 현업에 있다. 아래의 수치들은 내가 비용 청구서에서 직접 확인하는 것들이다. 그 어떤 것도 투자 권유가 아니다. 이 모든 내용은 현업 엔지니어가 토큰 하나의 가격을 매길 때 살펴보는 지표들이다.
현대의 AI 가속기를 예로 들어보자. 엔비디아 H100은 이론적으로 초당 약 1,979조 번의 부동소수점 연산(FP16 처리량)을 수행할 수 있다. 반면, HBM3 스택과의 메모리 대역폭은 초당 3.35테라바이트(TB/s)다.
이 두 수치는 서로 균형이 맞지 않는다. 가공되지 않은 순수 연산 측면에서 보면 연산단이 메모리단보다 대략 600배 빠르다. 연산 장치를 쉬지 않고 돌리려면, 메모리에서 가져온 모든 바이트가 다음 바이트가 도착하기 전까지 평균적으로 수백 번 이상 재사용되어야 한다.
이를 '산술 연산 밀도'라고 부른다. 이는 메모리 액세스 횟수 대비 연산 횟수의 비율을 뜻한다. 만약 워크로드의 산술 연산 밀도가 칩의 연산 처리량 대 메모리 대역폭의 비율보다 낮아지면, 칩은 멈춰 서게 된다. 연산 장치들이 데이터를 기다리며 노는 것이다. 당신이 3만 달러를 지불한 칩은 이론상 성능의 5~15% 수준으로만 작동하게 된다.
현대의 트랜스포머 추론, 특히 긴 문장을 자기회귀 방식으로 생성하는 작업은 산술 연산 밀도가 최악이다. 모델은 토큰을 하나 생성할 때마다 메모리로부터 모든 파라미터를 새로 로드해야 하며, 계속 늘어나는 KV 캐시 전체를 읽어내야 한다. 파라미터당 연산량은 작다. 반면 요구되는 대역폭은 엄청나다.
이것이 바로 GPU를 통해 발현되는 폰 노이만 병목현상이다. 아키텍처는 1945년 이후로 바뀌지 않았다. 바뀐 것은 워크로드다.
수십 년 동안 폰 노이만 병목현상은 실제 엔지니어들이 우회 기법을 통해 해결하던 교과서적인 문제에 불과했다. CPU의 캐시 용량은 커졌고, 컴파일러는 프리페치 능력이 향상되었다. 메모리 계층 구조는 더 촘촘해졌고(L1, L2, L3, DRAM), 버스는 빨라졌다.
그러나 AI 워크로드는 다음과 같은 여러 이유로 인해 이 모든 우회 기법들을 한꺼번에 무력화했다.
첫 번째 이유는 모델의 크기다. FP16 포맷의 700억 개 파라미터(70B) 모델은 크기가 140기가바이트(GB)에 달한다. 이는 기존의 어떤 캐시 계층 구조에도 들어가지 않는다. 무조건 HBM(고대역폭 메모리)에 상주해야 하며, 순방향 연산이 일어날 때마다 이 거대한 데이터의 상당 부분이 연산 장치를 통과해야 한다.
두 번째 이유는 KV 캐시다. 모든 트랜스포머는 자신이 거쳐온 모든 토큰의 키와 값에 대한 실행 기록을 보존한다. 콘텍스트 창이 길어지면 이 상태 값은 세션당 수십 기가바이트로 불어날 수 있다. 10만 토큰의 콘텍스트를 대상으로 30분 동안 실행되는 현대적인 AI 에이전트 루프는 파라미터를 읽는 것보다 캐시를 읽는 데 더 많은 메모리 대역폭을 소모한다.
세 번째 이유는 배치 크기다. 학습 단계에서는 하나의 배치 안에서 수천 개의 샘플에 걸쳐 파라미터 로드 비용을 분할 상쇄하기 때문에 산술 연산 밀도가 높게 유지된다. 반면 추론, 특히 낮은 지연 시간을 요구하는 실제 서비스 환경에서는 대개 배치 크기 1 또는 32 수준에서 실행되므로 산술 연산 밀도가 무너진다. 결국 칩이 멈춰 서게 된다.
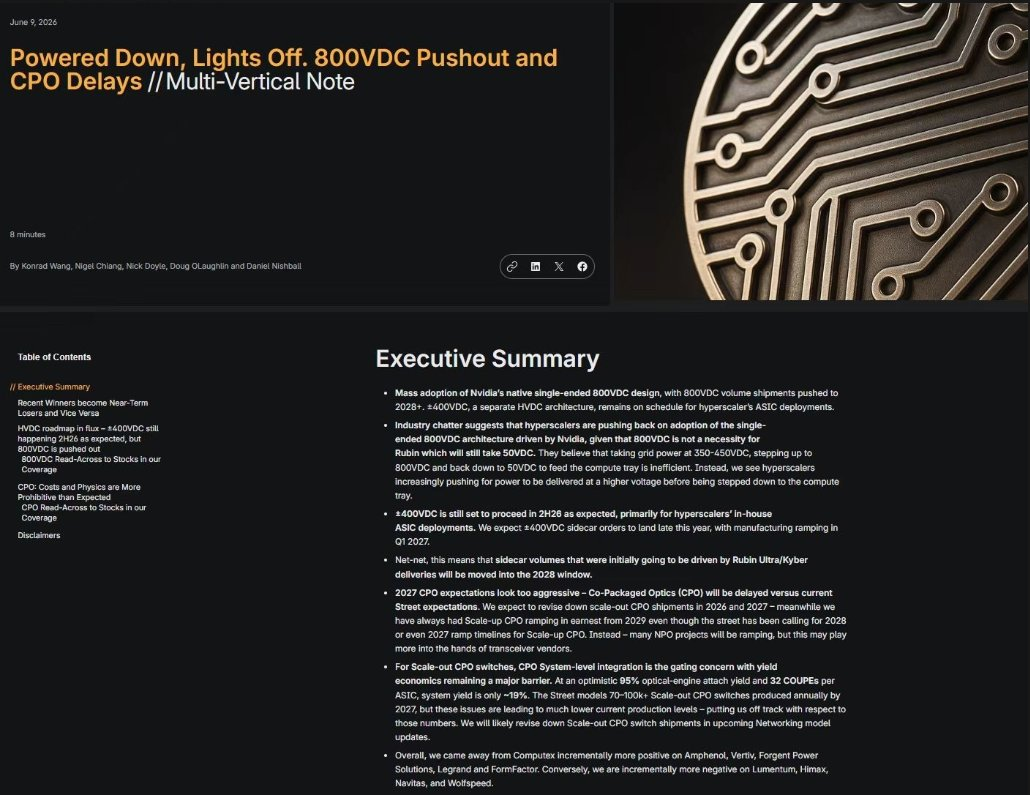
네 번째 이유는 추론형 모델이다. 추론형 모델은...

감탄하며 읽었습니다 책갈피에 넣어두고 나중에 다시 읽어봐야겠네요. 좋은 글 소개해주셔서 감사합니다

분석력과 배경지식의 깊이도 놀랍지만 문체의 유려함에도 감탄하면서 읽었습니다. 👍👍👍👍👍

너무 좋네요. 감사합니다!
폰 노이만 구조를 뛰어넘을 새로운 구조가 나오지 않는 이상 메모리의 수요는 계속 높은 상태를 유지하겠네요...