AI의 포토닉스 병목현상: 데이터 이동이 칩 제조보다 어려워진 이유
AI 클러스터들이 구리선 위에서 한계에 직면하고 있다. 백엔드 패브릭이 800G에서 1.6T, 그리고 3.2T로 치솟음에서 따라, 제약 조건은 더 이상 얼마나 많은 GPU를 살 수 있느냐가 아니라 그 GPU들 사이에서 얼마나 저렴하게 데이터를 이동시킬 수 있느냐가 되었다. 이것이 다음 초크포인트로서 광학 기술이 주목받는 이유이며, 이 문제가 어디서 가장 먼저 타격을 입히는지에 대한 지도다.
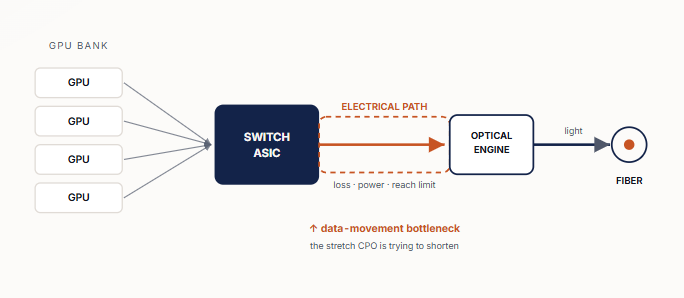
그림 1. AI 백엔드 네트워크의 랙 규모 조감도. GPU들은 스위치 칩을 통해 동기화된다. 비용이 많이 들고 고장이 나기 쉬운 구간은 스위치 칩과 광학 소자 사이의 고속 전기 경로다. 포토닉스 기술은 이 광전환 위치를 실리콘 칩에 더 가깝게 이동시켜 해당 경로를 축소한다.
차세대 AI 팩토리는 누군가 GPU가 부족해서 멈춰 서는 일은 없을 것이다. GPU들이 서로 충분히 저렴하고, 조밀하며, 안정적으로 통신할 수 없어서 멈추게 될 것이다. 이번 사이클의 대부분 동안 시장은 컴퓨트)만 응시했다. GPU가 눈에 보이는 첫 번째 대상이었고, 고대역폭 메모리(HBM)가 두 번째, 전력이 세 번째였다. 그러나 클러스터 규모에서 보면 이 머신은 가속기 더미가 아니다. 컴퓨터의 탈을 쓴 '통신 시스템'이다.
모든 학습 실행, 모든 가중치 전문가 혼합(MoE) 라우터, 모든 장기 콘텍스트 추론 작업, 그리고 모든 에이전트 루프는 칩과 랙, 열 사이, 때로는 사이트(데이터센터) 간에 트래픽을 발생시킨다. 시스템이 커질 수록 비트를 이동시키는 순수한 물리적 행위 자체가 시스템의 확장을 가로막는 제약 요인이 된다. 구리선은 초기에 구축을 주도할 수 있었는데, 저렴하고 정비하기 쉬우며 짧은 거리에서는 탁월하기 때문이다. 그러나 네트워크가 400G에서 800G, 1.6T 그리고 그 이상으로 치솟으면서, 구리는 인프라라기보다는 발목을 잡는 '항력'처럼 보이기 시작한다.
고속 전기 신호는 손실, 반사, 누화, 열, 커넥터, 거리를 버텨내야 한다. 해결책은 언제나 무언가를 '더' 투입하는 것이다. 더 많은 이퀄라이징, 더 많은 리타이머, 더 많은 DSP, 더 많은 전력, 더 많은 냉각, 더 거대한 케이블 부피가 그것이다. 어느 시점에 이르면 네트워크는 전기 신호가 전면 패널에 도달할 때까지 살아남을 수 있도록 유지하는 데에만 대부분의 에너지를 쓰게 된다. 포토닉스는 문제의 단위를 바꾼다. 신호는 빛이 되고, 광섬유는 고속도로가 되며, 비용은 상류 레이어인 레이저, 광학 집적 회로(PIC), 인듐 인화물(InP), 실리콘 포토닉스 웨이퍼, 광섬유 접합, 테스트 및 랙 유지보수성으로 이동한다.
이것이 전체의 변화를 한 문장으로 요약한 것이다. AI 스택은 "우리가 얼마나 많은 칩을 살 수 있는가"에서 "우리가 이미 가지고 있는 칩들 사이에서 데이터를 어떻게 충분히 이동시킬 것인가"로 이동하고 있다.
포토닉스 병목현상의 실체
포토닉스 병목현상이란 AI 클러스터가 전기적 상호연결이 제공할 수 있는 것보다 더 많은 대역폭, 도달 거리, 밀도, 에너지 효율성을 필요로 할 때 나타나는 물리적 제약이다. 작은 규모에서는 전기적 링크가 승리한다. 랙 내부에서는 구리선이 여전히 제 역할을 한다. 짧은 기판 패턴을 가로지를 때는 구리가 종종 정답이다. 하지만 AI 팩토리는 이제 더 이상 단일 랙이 아니다. 이들은 하나의 머신처럼 작동하도록 엔지니어링된 랙 그룹, 열, 포드, 그리고 멀티 사이트 시스템이다.
그 머신은 막대한 '동서향 트래픽(East-west traffic, 가속기 간 통신)'을 생성한다. GPU는 단순히 스토리지에서 데이터를 끌어와 사용자에게 답변을 돌려주기만 하는 것이 아니다. 이들은 그래디언트를 동기화하고, 액티베이션을 교환하며, 전문가들 사이로 토큰을 라우팅하고, KV 캐시 상태를 셔틀 버스처럼 나른다. 이들은 실리콘으로 가득 찬 건물이 마치 단 하나의 가속기인 것처럼 일사불란하게 협력한다. 그 결과는 단순하면서도 다소 직관에 반한다. 바로 네트워크 자체가 컴퓨터의 일부가 된다는 점이다.
엔비디아는 2025년 3월, 에너지와 운영 비용을 절감하면서 수백만 개의 GPU를 사이트 간에 연결하도록 설계된 실리콘 포토닉스 네트워킹 스위치인 스펙트럼-X 포토닉스와 퀀텀-X 포토닉스(Quantum-X Photonics)를 발표하며 이를 명확히 했다. 엔비디아는 구체적인 수치를 제시했다. 기존 방식 대비 레이저 사용량 4배 감소, 전력 효율성 3.5배 향상, 신호 무결성 63배 향상, 네트워크 회복 탄력성 10배 향상, 그리고 배포 속도 1.3배 증가를 달성했다는 것이며, 이 생태계 파트너로 TSMC, 코히어런트, 코닝, 폭스콘, 루멘텀, 센코, 스미토모 전기를 지목했다.
벤더들의 수치는 목표치로 읽어야 한다
이 글에 등장하는 벤더(엔비디아, 브로드컴, 글로벌파운드리스 등) 출처의 모든 성능 배수는 제조업체의 주장일 뿐, 독립적인 현장 데이터가 아니다. 이를 제조사가 제시한 '설계 목표치'로 취급하라. 정확한 배수가 마케팅의 영역일지라도, 전략적 방향성은 모호함 없이 명확하다. AI 분야에서 가장 중요한 인프라 기업이 광학 네트워킹을 AI 팩토리 자체에 빌트인 형태로 내장하고 있다는 사실이다.
왜 구리는 점진적으로, 그러다 갑자기 패배하는가
낮은 속도와 짧은 거리에서 구리는 경이로울 정도로 훌륭하다. 저렴하고, 익숙하며, 현장 정비가 가능하다. 조달 팀도 이를 잘 이해하고 있으며, 테크니션들이 쉽게 교체할 수 있다. 하지만 고속 전기 신호 전달은 추상이 아니다. 이는 금속 패턴, 커넥터, 기판, 케이블을 통과하는 '파동'이며, 레인 속도가 올라갈수록 이 파동은 감쇠하고 왜곡된다. 에너지를 잃고, 반사되며, 이웃한 채널로 번져나가 결국 송신된 신호와 도착한 노이즈를 구별하기가 점점 더 어려워진다.
광인터커넥트포럼의 CEI-224G 표준화 작업은 업계가 이 문제와 어떻게 사투를 벌이고 있는지 잘 보여주는 지표다. 이 프레임워크는 차세대 핵심 과제로 전력, 밀도, 성능, 도달 거리, 비용을 꼽았으며, 짧은 칩-투-옵틱스 홉부터 플러거블 광학, 백레인, 패시브 구리선, 리니어 광학 모듈에 이르기까지 224G 전기 인터페이스의 구체적인 도달 거리 범주를 매핑하고 있다. 모든 범주는 타협의 산물이다. 도달 거리가 짧으면 이퀄라이징이 단순해지고 전력을 아낄 수 있다. 도달 거리가 길어지면 더 많은 보정 기술이 필요하다. 그리고 모듈의 유지보수성을 유지해 주는 전면 패널 플러거블 방식은 신호가 스위치 칩을 전기로 떠나 기판 패턴과 커넥터를 가로지른 뒤에야 '비로소 빛으로 변환'되도록 강제한다. 이 숨겨진 경로가 바로 레인당 200G에 도달했을 때 고통스러운 병목으로 돌변하는 구간이다.
그림 3. 도달 거리 패널티. 레인 속도가 두 배로 증가할 때마다, 고속 전기 신호가 왜곡 없이 깨끗하게 도달할 수 있는 거리는 급격히 붕괴한다. 속도의 단계가 한 계단씩 올라갈 때마다 광전환 위치는 실리콘 칩에 더 가깝게 전진할 수밖에 없다. 막대의 길이는 예시일 뿐이며 실제 축적을 반영하지 않는다.
업계에는 구리선의 수명을 연장할 수 있는 실질적인 방법들이 존재한다. 더 뛰어난 SerDes, 액티브 전기 케이블(AEC), 리타이머, 리니어 플러거블 광학(LPO), 니어패키지 광학(NPO), 개선된 기판 소재 및 커넥터 등이 그것이다. 이 중 그 어떤 것도 무의미하지 않으며, 기술이 나아가는 방향 자체를 바꾸지도 못한다. 이 기술들은 시간을 벌어줄 뿐이다. 그리고 AI 규모의 인프라 시장에서 시간은 매우 비싼 대가를 요구한다.
포토닉스가 실제로 해결하는 것
포토닉스가 데이터 이동 비용을 공짜로 만들어주는 것은 아니다. 비용이 발생하는 위치를 옮겨줄 뿐이다. 전기적 상호연결은 데이터를 금속선 전반에 걸쳐 전기 신호로 밀어낸다. 반면 광학적 상호연결은 데이터를 빛에 인코딩하여 광섬유나 도파로를 통해 이동시킨다. 광섬유와 도파로는 데이터센터 내부 수준의 거리에서 손실률이 훨씬 낮고, 가닥당 집적도가 훨씬 높으며, 고속 구리선을 파괴하는 거리 패널티에 대한 민감도가 훨씬 낮다. 이로 인해 발생하는 이득과 타협점은 각 레이어마다 다르게 나타난다.
그 마지막 행(CPO)이 바로 공동 패키징 광학(Co-packaged optics) 기술이 논쟁의 중심이 된 이유다. CPO는 광학 엔진을 스위치 칩이나 가속기 패키지 바로 옆으로 이동시킨다. 고장 나기 쉽고 취약한 고속 전기 신호를 전면 패널까지 긴 기판 경로를 따라 밀어내는 대신, 실리콘 칩 근처에서 곧바로 빛으로 전환하는 것이다. 이로 인해 전기적 이동 거리는 센티미터(cm) 단위에서 밀리미터(mm) 단위로 축소되며, 광학 경로가 훨씬 더 이른 단계에서 바톤을 이어받는다. 이는 단순히 네트워킹의 변화만을 뜻하지 않는다. 패키징의 이야기이자, 테스트의 이야기이며, 현장 유지보수성의 이야기다. 그리고 바로 이 지점들이 진짜 병목현상이 시작되는 ...