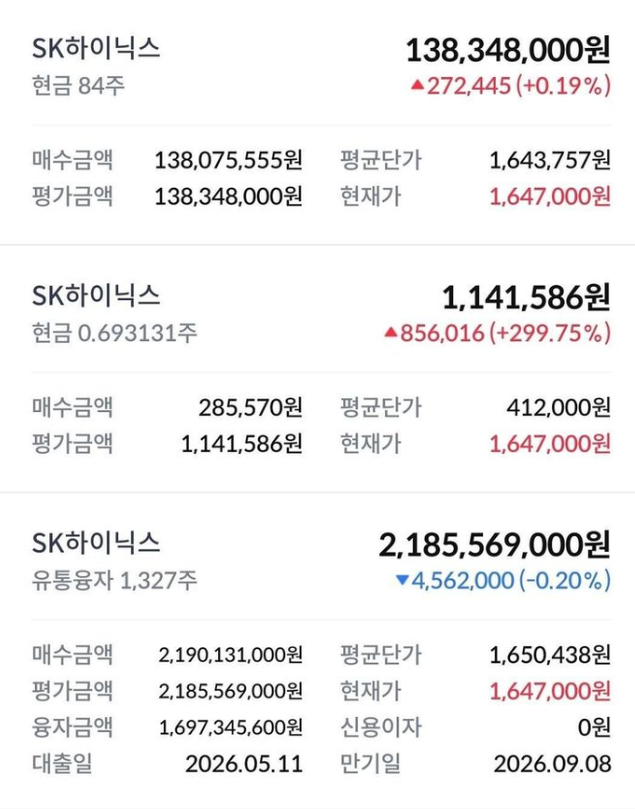
시간통장
구독자 154명구독중 63명
시간을 추억과 휴식, 건강, 부의 계좌에 차곡차곡 쌓기.
Garbage계좌에 쌓이는 것을 경계하기.
지난 2년간 반도체 시장의 중심은 HBM과 GPU였습니다. 그런데 2026년 현재, 시장의 질문은 조금 바뀌고 있습니다. “누가 더 많이 확보했나”에서 “같은 자원으로 누가 더 싸고 빠르게 추론하나”로 옮겨가는 중입니다. 이 변화는 하드웨어 증설만이 아니라 소프트웨어 최적화, 그리고 메모리-로직 통합 설계의 중요도를 동시에 끌어올리고 있습니다.
이 글에서는 그 흐름을 터보퀀트, MTP, SRAM-CIM 세 축으로 정리하고, 각 기술의 ‘현재 위치’와 ‘상용화 시계열’을 어디까지 합리적으로 추론할 수 있는지도 함께 적어보겠습니다.
터보퀀트는 KV 캐시 메모리 오버헤드를 줄이기 위한 압축 알고리즘으로, ICLR(International Conference on Learning Representations : 머신러닝/딥러닝 분야의 세계 3대 학회로 매년 4~5월에 개최) 2026 발표 기술로 소개됐습니다. 장점은 모델을 처음부터 다시 학습시키는 방식이 아니라, “추론 과정의 병목”을 겨냥했다는 점입니다.
현재 위치(2026년 5월): "논문 단계 → 실험실 코드 단계 → 누구나 가져다 쓰는 오픈소스 단계" 중에서 이미 세 번째 단계에 진입
상용화 시계열(추론): 2026년 하반기~2027년에 걸쳐 “일부 엔진/일부 모델에서 옵션 형태”로 도입되고, 검증이 누적되면 확산 속도가 빨라질 가능성이 있다고 보고 있습니다.
왜 이렇게 보나: (1) 추론 단계 최적화는 하드웨어 교체보다 도입이 빠를 수 있고, (2) 장기 문맥/추론 비용 절감 인센티브가 크지만, (3) 멀티테넌트 환경 안정성·정확도 검증이 충분히 쌓여야 ‘기본값’이 되기 때문입니다.
멀티테넌트 환경이란 하나의 물리적 인프라(서버, GPU, 소프트웨어 인스턴스 등)를 여러 고객(테넌트)이 동시에 공유하면서도, 각자의 데이터와 작업이 논리적으로 완벽히 격리된 채 운영되는 클라우드 컴퓨팅 구조를 의미합니다. 영어로 'tenant'는 '세입자'를 뜻하는데, 마치 하나의 거대한 아파트 건물(인프라)에 여러 세대(고객)가 입주해 살면서 각자의 공간은 독립적으로 보장받는 구조와 같습니다.
멀티테넌트 핵심 개념
공유 인프라: 단일 하드웨어/소프트웨어 자원을 다수 사용자가 함께 사용 (예: AWS, Google Cloud, Azure 같은 퍼블릭 클라우드).
논리적 격리: 같은 GPU나 서버 위에서 동작하지만, A기업의 데이터와 B기업의 데이터는 서로 보이지 않고 침범할 수 없음.
자원 동적 할당: 트래픽과 수요에 따라 컴퓨팅·메모리 자원을 테넌트별로 유연하게 배분.
멀티테넌트 환경은 AI 추론 시장의 수익 구조를 결정짓는 핵심 무대. CSP 입장에서는 한 대의 GPU에서 더 많은 테넌트를 수용할수록 수익성이 올라감
MTP(다중 토큰 예측)는 LLM에게 "다음 한 단어"가 아니라 "앞으로 올 몇 단어를 한꺼번에" 맞히도록 가르치는 학습 방식입니다. 마치 학생에게 받아쓰기를 시킬 때 한 글자씩 부르는 대신, 두세 글자를 미리 떠올려보게 훈련시키는 것과 비슷합니다. 이렇게 하면 같은 데이터로도 모델이 더 많은 것을 배우고(데이터 효율↑), 문장의 흐름을 더 멀리 내다보는 능력도 좋아집니다(성능↑).
대표 사례가 DeepSeek-V3입니다. 이 모델은 학습 목적함수에 MTP를 정식으로 채택했다고 공개했고, 그 결과 학습 효율과 추론 속도 양쪽에서 이점을 얻었습니다.
이 효과는 추론(서빙) 단계에서 더 직접적으로 체감됩니다. 오픈소스 추론 엔진 vLLM은 MTP 모델이 미리 뽑아둔 여러 토큰을 한 번에 검증해 채택하는 "speculative decoding(투기적 디코딩)" 기능을 공식 문서로 지원합니다. 쉽게 말해, 모델이 답변을 "한 글자씩 천천히 쓰는 대신 몇 글자를 한꺼번에 써놓고 검토"하는 방식이라, 같은 GPU로도 응답이 더 빨라지고 처리량이 늘어납니다.
현재 위치: “일부 선도 모델/서빙 스택(서빙스택 : 학습된 AI 모델을 실제 서비스로 운영하기 위한 소프트웨어 계층 — 비유하자면 GPU(요리사)와 모델(레시피)을 받아 주문을 묶고, 재료를 관리하고, 결과를 손님에게 전달하는 "식당의 주방 운영 시스템". vLLM, TensorRT-LLM 같은 엔진이 대표적이며, 이들의 효율이 곧 GPU 한 장당 처리량과 추론 단가를 결정해 클라우드 사업자의 마진을 좌우)에서 확산” 정도
상용화 시계열(추론): 2026년 하반기~2027년에 신규 모델 세대 교체와 함께 채택이 늘 가능성이 높고, 온디바이스는 SoC/NPU 세대 교체 속도에 맞춰 더 느리게 들어올 가능성이 큽니다.
MTP·터보퀀트 같은 기술이 클라우드(서버 GPU)에서는 빨리 확산되지만, 온디바이스(스마트폰·노트북·자동차)에서는 SoC가 새로 설계·양산되어야 적용
SoC(System on Chip): CPU·GPU·NPU·메모리 컨트롤러·통신 모뎀 등 시스템 구성 요소를 단일 칩에 통합한 반도체. 스마트폰의 Apple A시리즈, Qualcomm Snapdragon이 대표적이며, 새 알고리즘의 온디바이스 적용 속도는 이 SoC의 세대 교체 주기에 좌우
왜 이렇게 보나: MTP는 ‘추론 엔진 패치’라기보다 ‘학습 목표/모델 설계’에 가깝기 때문에, 보급 속도는 모델 출시 주기와 맞물립니다.
SRAM 기반 CIM은 메모리 내부(또는 매우 근접한 곳)에서 연산을 수행해 데이터 이동 비용을 줄이려는 접근이며, 최근에도 SRAM-CIM 가속기의 데이터플로우/한계 등을 다룬 연구가 계속 나오고 있습니다.
현재 위치: 연구/PoC(Proof of Concept, 개념 증명 : 양산성·수율·패키징·소프트웨어 스택은 아직 검증되지 않은, "기술적 가능성" 확인 단계)/IP(Intellectual Property, 설계자산 : 재사용 가능한 회로 설계 블록)확산 단계.
상용화 시계열(추론): 엣지/저전력 특화 영역에서 부분 적용이 ...