“언어가 지능은 아닙니다”: 트랜스포머 혁명을 놓친 천재의 대가
2017년 6월 12일, 구글 브레인 연구자 8명이 논문 하나를 올렸습니다. 제목은 “Attention Is All You Need”였습니다. GPT 모먼트 이전에 'Attention Is All You Need'가 있었습니다. 이게 모든것의 시작이었습니다.
*2017년 구글 브레인 팀이 발표한 논문으로, '트랜스포머'라는 새로운 AI 아키텍처를 처음 세상에 내놓은 문서입니다. 기존 AI가 단어를 순서대로 처리하던 방식을 버리고 문장 전체를 동시에 파악하는 '어텐션 메커니즘'을 핵심 구조로 삼았으며, 이후 등장한 GPT·BERT·제미나이·클로드 등 모든 대형 언어모델이 이 구조를 뼈대로 삼습니다. 이 논문 한편이 AI 전체의 새로운 시작을 가능하게 했습니다.
오픈AI의 수츠케버는 그날 논문을 읽고 의자에서 벌떡 일어났습니다. 동료 래드포드를 찾아가 말했습니다. “지금 하던 거 다 던져. 트랜스포머에 집중 해야 해. 이거 엄청날 거야.” 래드포드가 처음엔 영문을 몰라 했는데, 수츠케버가 워낙 밀어붙여 결국 작업에 들어갔습니다.
하사비스는 논문을 읽었고, 중요하다고 생각했지만, 의자에서 자빠질 정도는 아니었습니다. 그의 머릿속은 프로젝트 마리오 협상 실패와 구글과의 법률 공방으로 가득 차 있었습니다. 거기다 강화학습으로 위대한 걸 만들 수 있다는 믿음도 여전했습니다.
이 차이가 나중에 엄청난 값을 치르게 됩니다.
딥마인드의 초창기 사업계획서에는 이런 문장이 있었습니다. “언어가 지능이라는, 잘못됐지만 지대한 영향력을 가진 개념.” 창업 첫날부터 언어 AI에 회의적이었던 거고, 이건 그냥 기술 판단이 아니라 하사비스라는 사람의 오래된 세계관이었습니다.
데미스가 맬러비에게 설명한 방식을 통해 이해해보겠습니다. 술집 테이블 위의 유리잔을 들어 올리면서. “이 컵을 떨어뜨리면 깨지겠죠. 위키피디아를 다 읽어도 이게 이해됩니까? 무게를 실제로 느껴본 적 없으면 무게가 뭔지 어떻게 압니까?” 신경과학에서 말하는 논리였습니다. 세상을 제대로 이해하려면 그 안에서 직접 행동해야 한다. 언어는 현실을 가리키는 기호일 뿐이고, 기호가 물리 세계와 연결되지 않으면 지능이 아니라는 것. 이것이 딥마인드가 창업 때부터 '그라운딩 문제(grounding problem)'라고 불러온 핵심 명제였습니다.
두 번째 오판은 더 근본적이었습니다. 그는 인간 경험의 총량을 잘못 계산했습니다. "예전에 저한테 '인간 문명은 얼마나 복잡한가'라고 물었다면, 저는 10의 50승 비트쯤 된다고 했을 겁니다. 인간이 취할 수 있는 행동과 사고의 가능성이 거의 무한하다고 봤거든요. 그런데 인터넷에 14조 단어가 있고, 이는 충분한 테이터였어요. 10의 13승 정도. 나는 그게 가능하리라고 생각 못 했습니다." 처음 나온 GPT들은 그의 예상을 확인해주는 것처럼 보였습니다. 조악한 암기 기계였거든요.
First day of OpenAI (출처: 샘 알트먼 X)
그 사이 수츠케버는 트랜스포머를 들고 달렸습니다. 원래 구글이 번역용으로 만든 걸 래드포드가 대화형으로 뜯어고쳤습니다. 인간이 붙인 라벨 없이 원시 텍스트만 먹여 다음 단어를 예측하게 하는 방식이었습니다. 2018년 6월 나온 결과물 이름이 GPT, Generative Pre-trained Transformer (생성형 사전 훈련 트랜스포머)였습니다. 소비자 제품 이름으로는 최악이었지만, 안에 든 건 달랐습니다.
그때 딥마인드는 가이아(Gaia) 프로젝트를 밀고 있었습니다. 인간 데이터 없이 환경과 직접 상호작용해서 스스로 경험을 만들어낸다는 패러다임은 그들이 생각하는 AGI의 청사진이었습니다. 기계가 세상을 직접 경험하며 배워야 한다. 텍스트를 읽는 것으론 부족하다. 가이아는 자연 생태계를 시뮬레이션한 가상 환경에서 AI 에이전트가 스스로 개념을 발견하며 지능을 키우는 실험이었습니다. 하사비스는 킹스크로스 신사옥의 벽 한 면을 통째로 가이아 화면으로 채우는 계획까지 세웠습니다. "정말 멋졌을 텐데." 나중에 가이아의 실패를 회상하며 한 말입니다.
가이아는 실패했습니다. 에이전트가 단순한 환경은 처리했지만 진짜 불규칙한 자연 앞에서 무너졌습니다. 복잡한 데이터를 많이 먹을수록 강해지는 건 언어 모델이었고, 강화학습 에이전트는 그렇지 않았습니다.
2020년 5월, GPT-3가 나왔습니다. 파라미터 1,750억 개. 딥마인드가 쫓던 640억의 세 배 가까이였습니다. 수츠케버는 “처음 써보면 거의 영적인 경험”이라고 했습니다. 하사비스도 이번에는 달랐습니다. “GPT와 GPT-2는 내가 예상하던 것이었어요. 그런데 GPT-3는 분명히 달랐습니다.”
딥마인드는 부랴부랴 목표를 2,800억 파라미터로 올렸습니다. 코드명 고퍼(Gopher). “셰인 레그가 초기 AGI는 쥐 수준일 거라고 했거든요. 그래서 설치류(Gopher) 이름 붙였죠.” 2021년 초 완성된 고퍼 앞에서 하사비스가 물었습니다. “프랑스 수도가 어디야?” 고퍼가 답했습니다. “영국 수도는 어디야? 이탈리아 수도는?” 아는 건 많은데 대화를 어떻게 하는지 몰랐습니다. 몇 가지 사후 훈련으로 이 문제를 해결한 고퍼챗이 내부에서 꽤 잘 돌아갔습니다. 그런데 공개를 안 했습니다. NHS 데이터 스캔들 이후 자리잡은 분위기였습니다. 공개를 밀어붙이던 잭 레이는 2022년 초 오픈AI로 떠났고, 다른 엔지니어들도 뒤따랐습니다.
* NHS 데이터 스캔들: 2016년 5월, 딥마인드 헬스가 런던 왕립 자유 병원과 맺은 데이터 협약에서 160만 명의 환자 기록이 본인 동의 없이 넘겨졌다는 데일리 메일 보도로 불거진 사건으로, 딥마인드는 계약서가 NHS 표준 템플릿을 따랐고 구글의 데이터 접근도 차단했다고 반박했지만, 빅테크 불신 정서와 맞물려 딥마인드 의료 AI 사업 전반에 오랜 오명을 남겼습니다.
하사비스가 연구 방향을 “세 개의 동등한 패러다임”으로 나눈 것도 발목을 잡았습니다. 강화학습, 신경과학 기반, 데이터 기반 신경망. 이 개방성이 알파폴드를 낳았지만, 언어 모델이 폭주하는 상황에서 전력을 집중하지 못하게 했습니다. 수츠케버의 오픈AI는 달랐습니다. 언어 모델 하나만 봤습니다. 다른 건 없었습니다. 젊고 작은 조직이 크고 명성 높은 연구소를 앞서나간 이유 중 하나입니다.
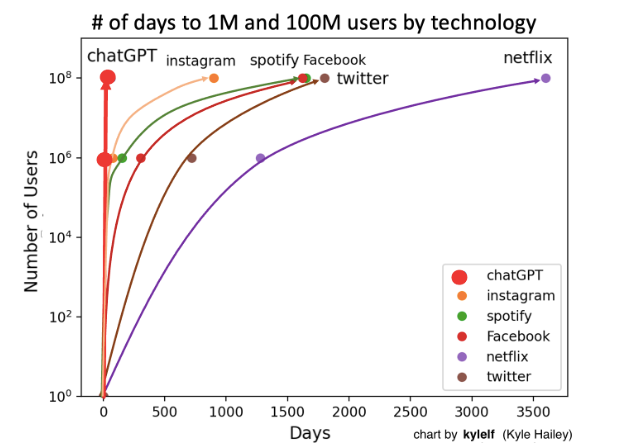
2022년 11월, 챗GPT가 세상에 나왔습니다. 5일 만에 100만 명, 두 달 만에 1억 명. 딥마인드는 세계 최고 AI 연구소라는 자리를 잃었습니다.
너무 자주 들어 진부하지만, 괴거와 비교할 수 없을 정도 속도의 ChatGPT 성장 속도
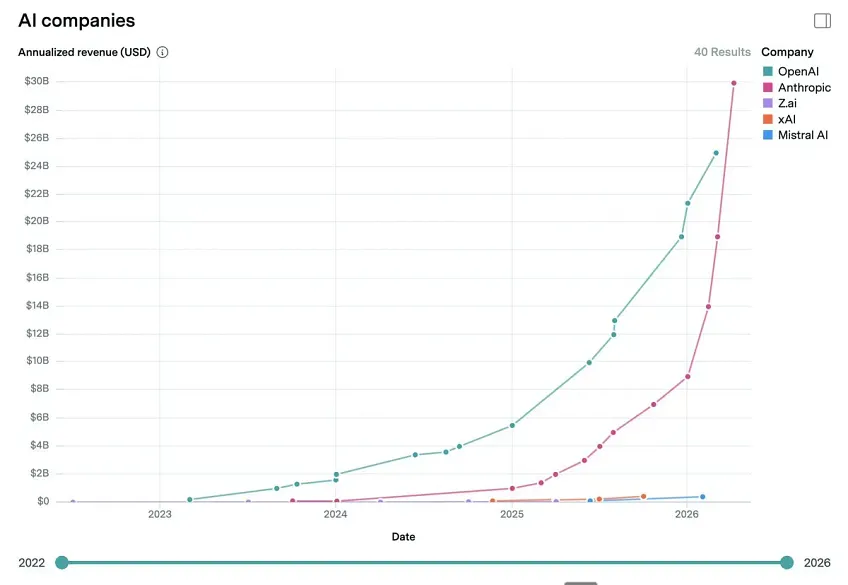
그 대단한 OpenAI를 매출성장속도로 역전해버린 Anthropic
하사비스가 나중에 한 말이 남습니다. “이건 저를 포함해 거의 모든 사람을 놀라게 했어요. 어쩌면 일랴와 그 주변 몇 사람을 빼고는요. 항상 노스트라다무스가 될 수는 없죠.”
그 말이 맞습니다. 그리고 그것으로 충분합니다. 실수를 인정했고, 방향을 틀었습니다.
제미나이의 반격 — 실패한 데뷔에서 업계 최고까지
2022년 11월 챗GPT가 터졌을 때, 구글 내부에는 두 개의 세계 최고 AI 연구소가 공존하고 있었습니다. 구글 브레인과 딥마인드. 두 조직은 10년 가까이 각자의 방식으로 AI를 연구해왔고, 논문 수에서는 세계 최고였지만 제품으로는 아무것도 내놓지 못한 상태였습니다. 챗GPT에 맞서 서둘러 공개한 바드(Bard)가 첫 데모에서 사실 오류를 냈고, 투자자들이 패닉 매도에 나서며 구글 시총이 하루 만에 9% 증발했습니다. 딥마인드도 챗GPT에 견줄 만한 스패로우(Sparrow) 모델을 준비하고 있었지만, 피차이가 바드에 전력 집중을 결정하면서 출시가 취소됐습니다. 이유를 들을 수 없었던 딥마인드 연구자들 ...