
슈크림빵
구독자 218명구독중 17명
AI Engineer로 일하고 있습니다.
안녕하세요, 슈크림빵입니다,.
벚꽃이 지면서 완연한 봄이 온 것 같아요. 바람도 그렇게 차갑지 않고, 낮 기온은 올라가고 벌써 옷차림이 가벼워진 사람들이 많이 보입니다.
저는 추위를 많이 타서 아직도 경량 패딩을 입고 있어요🤣
오늘은 AI에 관련된 글을 읽고 정리해서 가져와보았답니다!

요즘 AI 업계에서 가장 핫한 키워드 중 하나가 Recursive Self-Improvement(재귀적 자기 개선, RSI)입니다.
AI가 스스로를 개선하고, 그 개선된 AI가 다시 자신을 개선하고… 이걸 반복하면 어느 순간 폭발적으로 똑똑해지는 거 아니냐는 이야기죠. 소위 "하드 테이크오프"라 불리는 시나리오입니다.
최근 읽은 글 하나가 이 주제를 꽤 현실적인 시각으로 정리하고 있어서, AI 엔지니어 입장에서 리뷰해보려 합니다.
일단 팩트부터 짚겠습니다.
AI로 AI를 만드는 건 이미 일어나고 있습니다. 데이터 필터링, 코드 작성, 실험 세팅까지 모델 개발 파이프라인의 상당 부분에 AI가 들어가 있죠.
덕분에 모델 성능 향상 속도가 빨라지는 건 맞습니다.
그런데 저자는 여기서 몇 가지 중요한 제약을 짚습니다.
첫째, 돈 문제. 프론티어 모델 한 번 학습시키는 데 들어가는 비용이 어마어마합니다. Anthropic의 Dario Amodei 말을 인용하면, 컴퓨트 수요가 매년 10배씩 늘어난다고 해도 2027년에 1조 달러어치 컴퓨트를 살 수는 없다는 거죠. 자동화를 아무리 해도 결국 이 비용은 어딘가에서 정당화돼야 합니다.
둘째, 나머지 5%의 함정. 엔지니어라면 공감할 텐데요. 프로세스의 95%를 자동화해도 나머지 5%가 전체 속도를 결정하는 경우가 정말 많습니다. 그 5%가 뭐냐면, 의사결정, 방향성 판단, 조직 내 합의 같은 "인간 시간"이 필요한 영역입니다. 코드는 AI가 짜줘도 "이걸 왜 만드는가"는 사람이 정해야 하니까요.
셋째, 수확 체감. 현재 패러다임 안에서 RL이나 합성 데이터로 성능을 쥐어짜는 건 잘 되고 있지만, 완전히 새로운 패러다임을 만들어내는 건 다른 차원의 문제입니다. 저자 표현을 빌리면, 지금 ...


![SpaceX 하나 망하면 미국 국방이 흔들립니다 - SETR 2026 리뷰 ➅ [Space]](https://img.seoul.co.kr/img/upload/2024/09/09/SSC_20240909102642_O2.jpg)
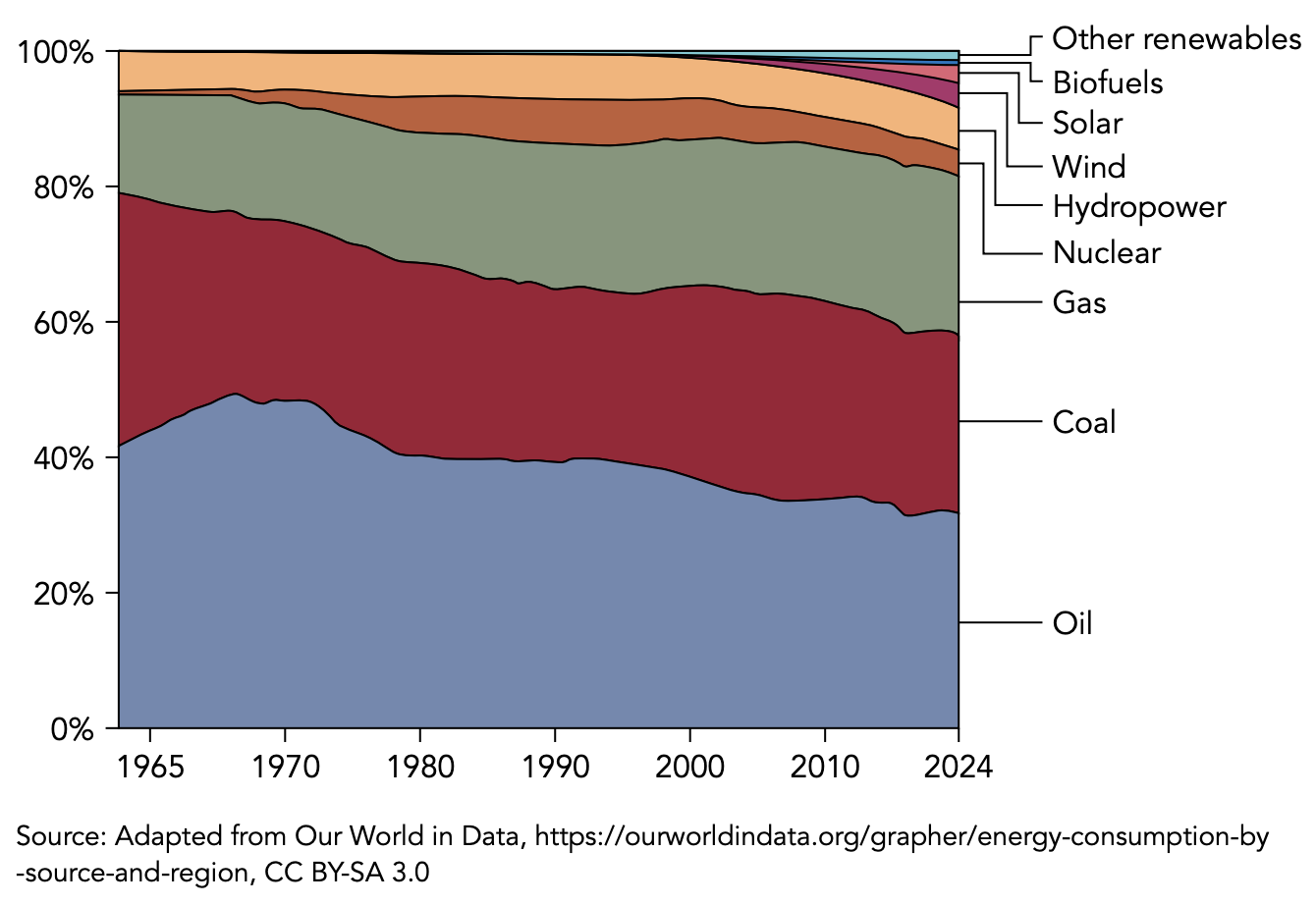

잘봤습니다.
전 프로그래밍이랑 전혀 무관한 분야이지만 결국 마지막은 인간이라는 것에 쟁점을 맞춰서 글을 읽으니 이해가 되네요.
아무리 좋은 도구도 그것을 받아들일 의지와 환경이 되지 않으면 쉽게 변하지 않는게 사람이라는걸 그동안 살아온 경험 그리고 역사를 통해서도 충분히 알 수 있는 사실입니다.
반대로 이야기하면 병목현상이 해결되는 입구에서 유연한 마음으로 받아들이고 투자 한다면 의외로 뻔하면서도 쉬운 투자 기회를 찾을수도 있을 것 같습니다.
좋은글 좋은 해석 잘봤습니다.
관찰님, 제 글봐주셔서 정말 감사드립니다!
말씀하신 것처럼, 아무리 뛰어난 지능을 가진 AI라 할지라도 결국 그것을 세상에 배치하고, 규제에 맞추고, 우리 삶의 일부로 받아들이는 것은 온전히 '사람'의 영역이더라고요.
엔지니어로서 매일 코드와 씨름하지만, 정작 세상이 바뀌는 속도를 결정하는 건 알고리즘의 효율성보다 "우리가 이 기술을 얼마나 신뢰하고 유연하게 받아들일 준비가 되었는가"라는 점을 매번 실감합니다.
따뜻한 공감과 좋은 해석 남겨주셔서 정말 감사합니다. 오늘도 기분 좋은 하루 보내세요! ^^