이 글의 목표는 매우 간단합니다. OpenAI를 설명하는 것입니다. 기술. 비즈니스 모델. 현재 상태.
이 글은 세 개의 섹션으로 구성되어 있습니다:
1. OpenAI의 기술에 대한 입문(딥러닝, LLM, 추론, 에이전트)
2. OpenAI의 비즈니스 분석(비즈니스 모델, 수익, 경쟁사)
3. 시장 통계 및 경쟁 환경
첫 번째 글이 OpenAI의 역사라면 이번 글은 현재이며, 마지막 글은 미래(또는 적어도 미래를 위해 제가 생각하는 질문)가 될 것입니다.
OpenAI의 역사를 다시 한 번 살펴보기 위해 여기까지 오게 된 과정을 살펴보겠습니다:
1. OpenAI의 기술
먼저 고백할 것이 있습니다: 저는 원래 OpenAI의 기술에 대해 수천 자에 달하는 글을 썼습니다. 하지만 기술에 대한 이해가 부족하다고 느꼈습니다. 제가 내린 결론은 이것이었습니다. 어떻게 여기까지 왔는지에 대한 이야기 없이 LLM을 설명하기는 정말 어렵다는 것이었습니다.
LLM에 대해 자세히 알아보려면 제가 추천하는 세 가지 자료가 있습니다:
1. Stephen Wolfram의 “ChatGPT는 무엇을 하며 왜 작동하는가?”
2. 3Blue1Brown의 딥러닝 및 LLM에 관한 시리즈
3. Andrej Karpathy의 ChatGPT와 같은 LLM에 대한 심층 분석
4. 보너스: 저녁 식사 자리에서 “잠깐만요, 다시 설명해 주시겠어요?”라고 반복해서 묻는 Devansh와 몇 시간 동안 대화를 나눴습니다.
AI의 개념화 → 수십 년간의 연구 → 딥러닝의 획기적인 발전 → 주의력 및 변환기 → 초기 LLM → ChatGPT → 추론 → 에이전트 등으로 압축된 AI의 진화 과정을 살펴볼 수 있습니다.
이러한 각 단계는 LLM을 위한 빌딩 블록을 제공했으며, 저는 아래의 핵심 아이디어를 추출하기 위해 최선을 다할 것입니다(그리고 제 기사를 즐기려면 틈새 시장과 호기심 많은 동료가 필요하다는 것을 잘 알고 있습니다. 지금 고개를 숙여도 괜찮습니다!)
AI의 뿌리
AI의 핵심 아이디어는 일상적인 인간 작업의 자동화와 인간 유사성 추구입니다.
계산기는 인공 지능의 한 형태였고, 그다음에는 메인프레임, 그다음에는 소프트웨어, 그리고 지금은 LLM으로 발전했습니다. 컴퓨팅의 진화를 통해 우리는 앨런 튜링이 인공지능에 대해 처음 설명한 것에 점점 더 가까워지고 있습니다:
“우리가 원하는 것은 경험을 통해 학습할 수 있는 기계입니다...[기계가 스스로 명령을 변경할 수 있는] 가능성이 이를 위한 메커니즘을 제공합니다.”
1940년대에 오늘날 AI 시스템의 기초가 되는 신경망이 이론화되었습니다. 신경망은 튜닝할 수 있는 다이얼처럼 '노드'의 레이어로 구성된 모델입니다. 신경망은 여러 노드 간의 관계를 “가중치”를 부여함으로써 복잡한 시스템을 모델링할 수 있습니다. 일반적으로 '노드'가 많을수록 더 복잡한 시스템을 모델링할 수 있습니다.
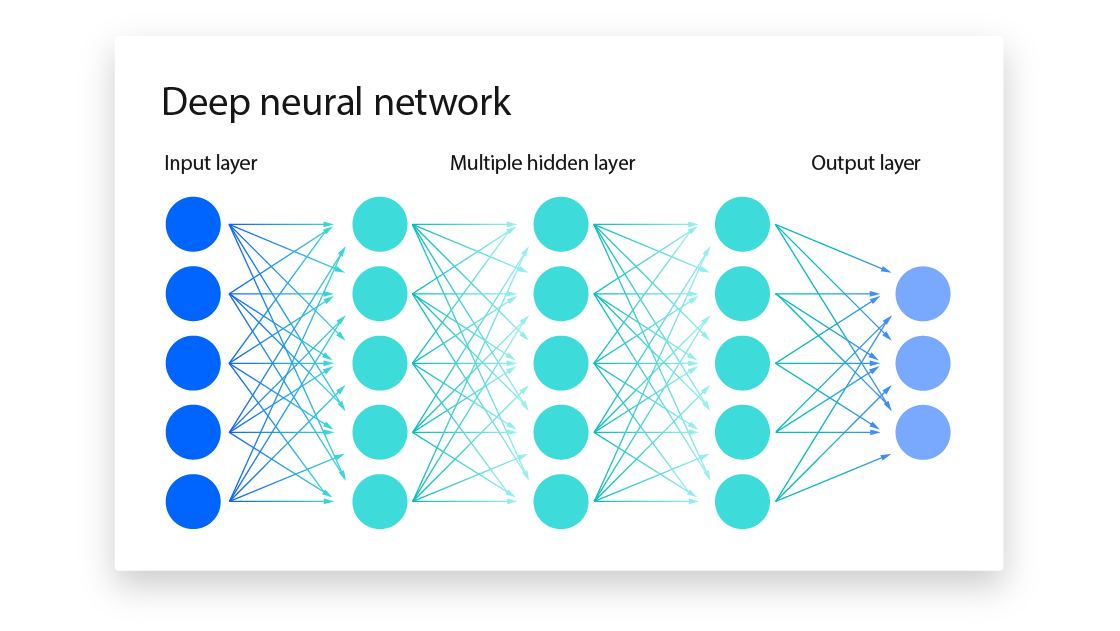
이러한 모델은 복잡한 시스템의 데이터로 학습됩니다. 목표는 실제 데이터와 예측 데이터 사이의 '손실 최소화'입니다. 일반적으로 더 많은 데이터가 제공될수록 더 나은 모델을 만들 수 있습니다.
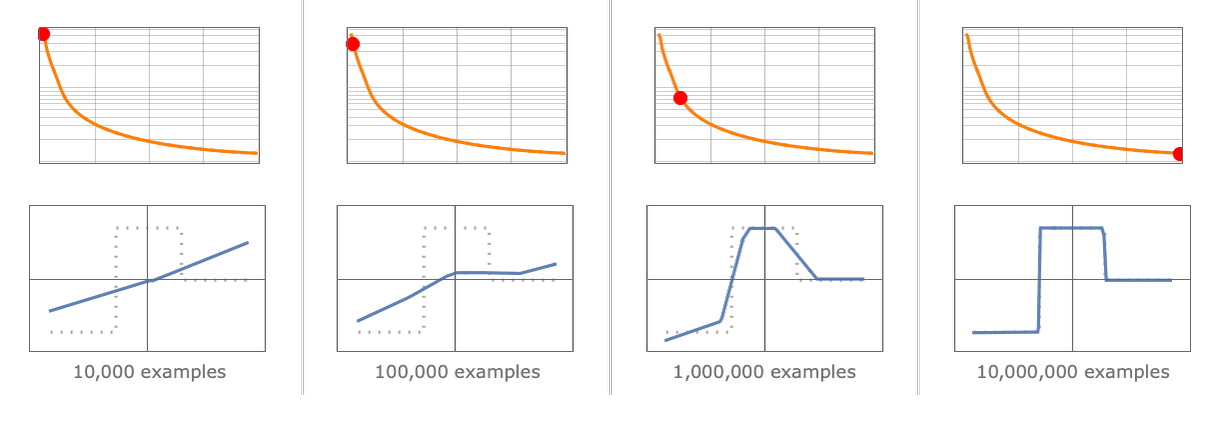
신경망이 실용적으로 발전하는 데는 수십 년이 걸렸습니다. 현대 딥 러닝은 빅 데이터의 부상과 Nvidia GPU의 병렬 컴퓨팅 능력이라는 두 가지 잠금 해제에 의해 탄생했습니다.
2012년에 인공 신경망의 성능을 크게 향상시킨 AlexNet의 돌파구가 열렸습니다. 한 가지 중요한 혁신은 GPU로 워크로드를 병렬화하는 것입니다.
최신 AI 시스템 - LLM의 블랙박스
AI의 다음 구성 요소는 지금은 유명한 “주의만 있으면 된다”라는 2017년 Google의 논문에서 발표된 트랜스포머였습니다.
여기서 핵심 아이디어는 '주의'를 통해 단어의 의미에 문맥을 통합할 수 있다는 것입니다. 예를 들어, '떠다니다'는 물 위에 떠다니다, 루트비어 수레, 퍼레이드 수레, 심지어 구름 위를 떠다니는 것을 의미할 수 있습니다. 트랜스포머는 이러한 의미를 단어에 통합하는 메커니즘을 제공합니다.
LLM은 먼저 주어진 데이터 세트(프롬프트)를 토큰(단어 조각과 같은 작은 데이터 비트)으로 나누고, 해당 단어의 의미(임베딩)를 벡터(데이터 열)에 매핑합니다:
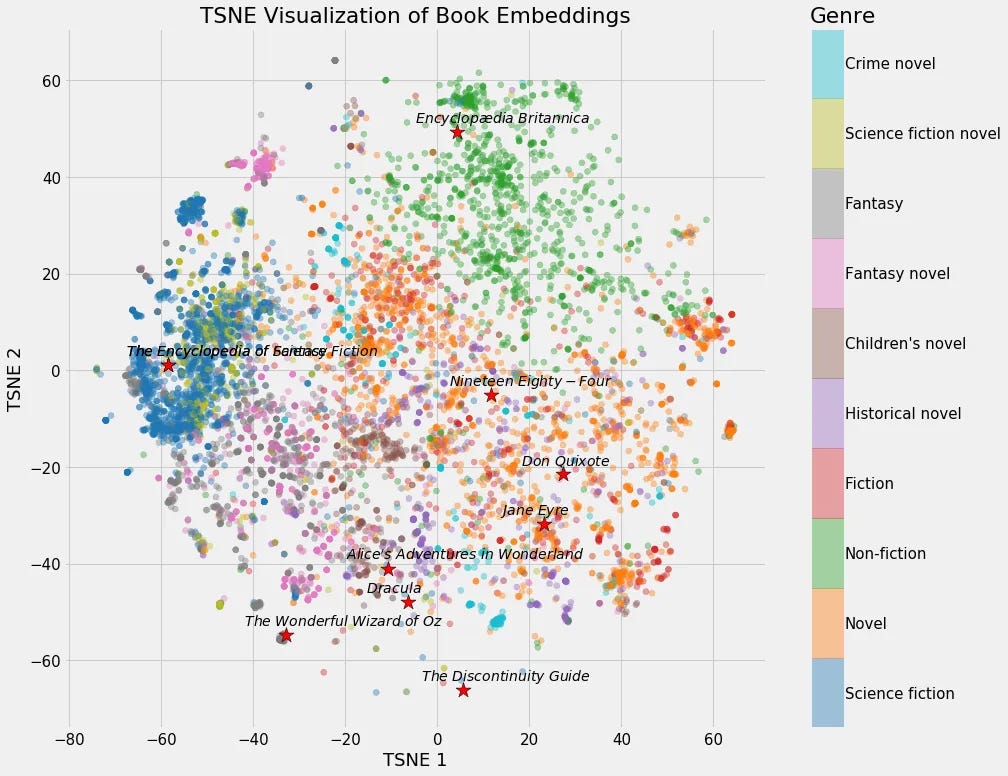
이 시점에서 모델은 주어진 데이터 세트(입력)를 나타내는 일련의 벡터 임베딩을 갖게 됩니다.
그런 다음 '트랜스포머'가 ...