OpenAI 심층 분석 1부에서는 OpenAI가 얼마나 중요한지 말씀드렸습니다. 2부에서는 중요한 만큼 복잡할 수 있다고 말씀드렸습니다. 3부에서는 그 복잡성만큼이나 흥미로울 수 있다는 점을 덧붙이겠습니다.
투자를 흥미롭게 만드는 것은 바로 이 모든 것의 사고 실험입니다. 우리는 미래에 대해 생각하고, 그에 따라 베팅하고, (희망적으로) 돈을 벌 수 있습니다.
OpenAI와 같은 회사에게 이러한 사고 실험은 매우 흥미로운 일입니다.
제가 OpenAI에 대해 확실한 예측을 해줄 수 있기를 바란다면 잘못 찾아오셨습니다. 확률론적 사고에 대한 찰리 삼촌의 명언을 떠올려보세요:
“이 기초적이지만 약간은 부자연스러운 확률의 수학을 레퍼토리로 삼지 않으면 엉덩이 차기 시합에 출전한 외다리 남자처럼 평생을 살게 됩니다. 다른 모든 사람에게 큰 이점을 주는 것이죠. 제가 오랫동안 함께 일해 온 [워렌] 버핏 같은 사람의 장점 중 하나는 의사 결정 트리와 순열과 조합이라는 기초 수학의 관점에서 자동적으로 사고한다는 점입니다.”
그래서 저는 “OpenAI의 미래”라는 글을 쓰는 대신. 저는 “OpenAI의 확률론적 미래”라는 글을 쓰겠습니다. 그러기 위해서는 OpenAI의 미래가 가장 많이 의존하는 변수를 정리해야 합니다(제가 놓친 부분이 많을 수도 있습니다. 결국 제 생각일 뿐이죠).
이러한 질문(스펙트럼으로 생각해야 합니다)은 다음과 같습니다:
1. 비용 구조: OpenAI가 추구하는 수직 통합과 비용 구조 개선이 얼마나 성공할 수 있을까요?
2. 비즈니스 모델: OpenAI는 모델을 통해 어떻게 수익을 창출하며, 이러한 모델이 얼마나 상품화될 수 있을까요?
3. 시장: AI 애플리케이션 시장의 최종 상태(규모, 시장 점유율, 수익성)는 어떤가요?
4. 제품: 모델의 지능을 어떻게 활용하고 에이전트의 행동을 현실화할 수 있나요?
5. 가치 평가: OpenAI의 가치를 어떻게 평가하나요?
이러한 변수 중 첫 번째는 수직 통합입니다:
1. 비용 구조: 모든 것을 소유하거나 시도하다 죽거나!
(물론 시도하다 죽지는 않을 것입니다. 수백억 달러를 모금했으니 어차피 다 소유하는 게 낫겠죠!)
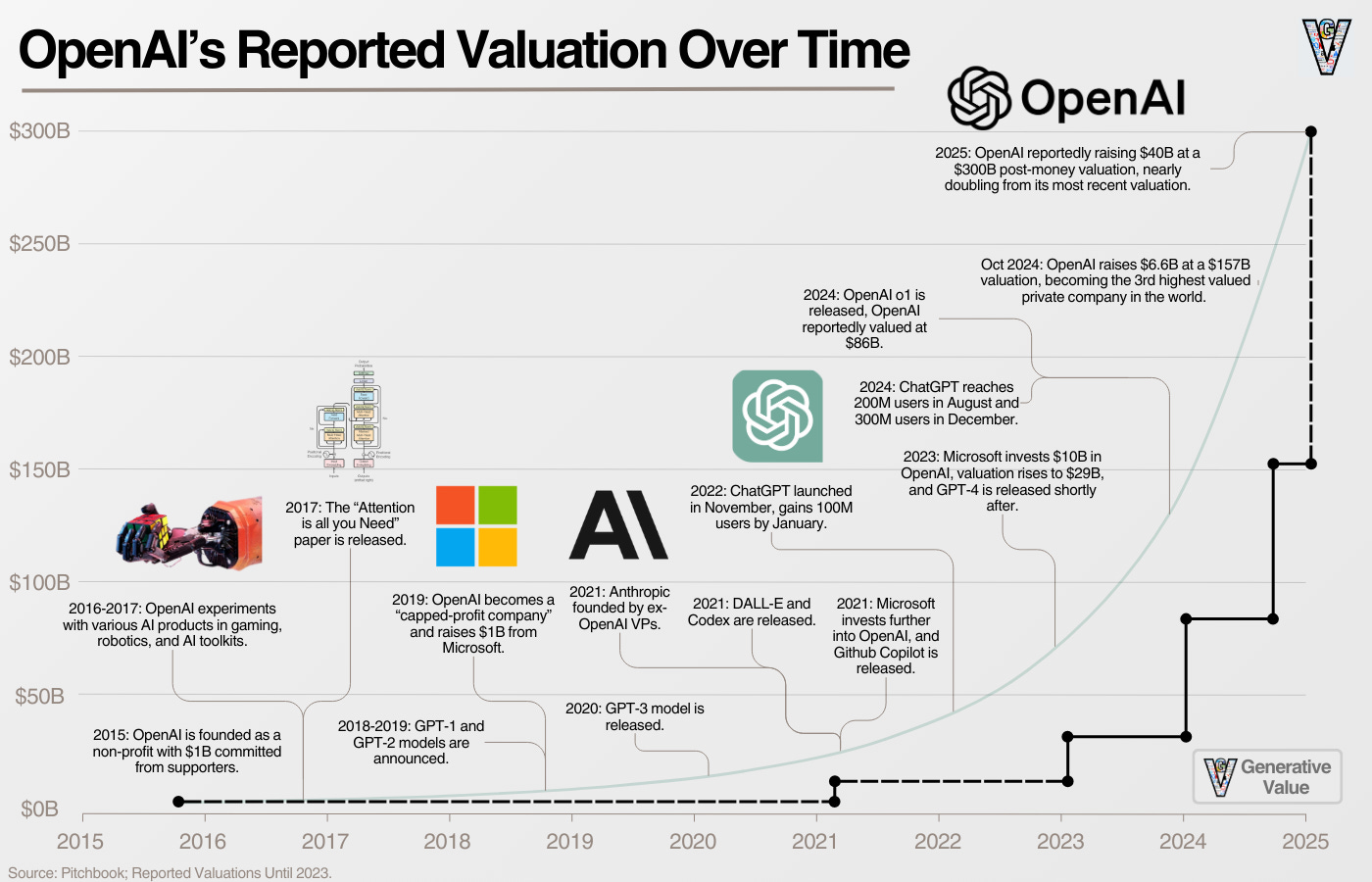
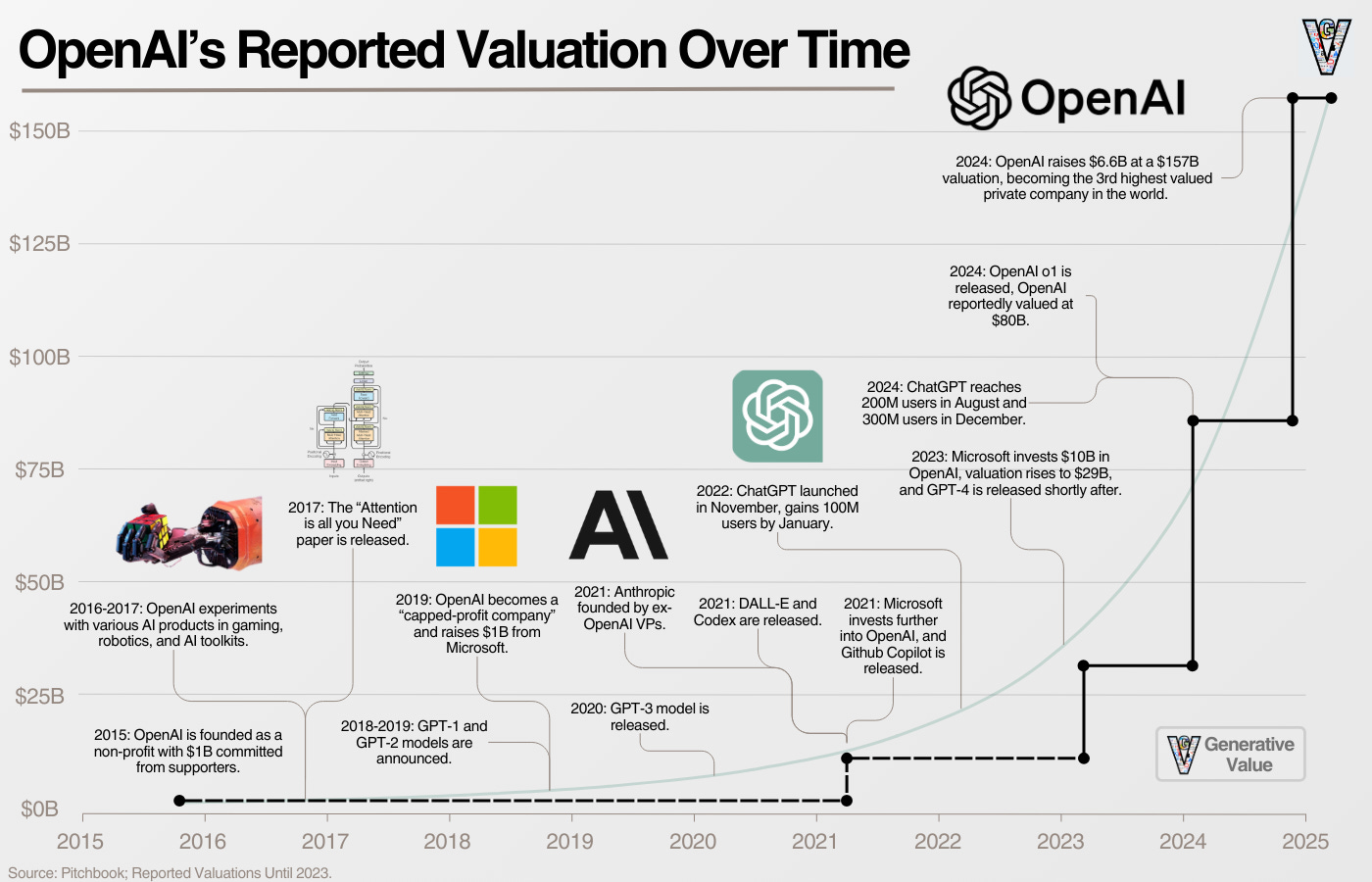
역사상 그 어떤 산업보다 초기 단계에 있는 AI에 더 많은 자금이 유입되고 있습니다(지난 4년간 VC 자금은 4,500억 달러로 추정되며, 닷컴 버블 당시의 2,560억 달러와 비교했을 때).
즉, 역사상 그 어느 산업보다 많은 자본이 경쟁하고 있습니다.
이러한 환경에서 경쟁 우위를 구축하는 것은 어려운 일이며, 이를 위해 OpenAI는 AI 스택의 위아래로 수직 통합을 추구하고 있습니다.
스타게이트와 OpenAI의 칩 노력에서 보았듯이, 스택 아래로 내려갈수록 비용 우위와 하드웨어 수준에서 경쟁하는 데 필요한 통제력을 확보할 수 있습니다.
대부분의 경쟁업체는 맞춤형 하드웨어(Google, Amazon, Meta) 또는 데이터 센터(xAI 및 하이퍼스케일러)에서 우위를 점하고 있습니다. OpenAI는 하드웨어를 충분히 제어할 수 없기 때문에 경쟁에서 밀릴 수밖에 없습니다.
그러나 OpenAI는 자체 데이터 센터나 하드웨어 없이도 생존할 수 있습니다. 애플리케이션을 선도할 수 있을까요? 이는 필수적이며 지속 가능한 경제를 위한 길입니다.
2. 비즈니스 모델: 지속 가능한 경제를 어떻게 만들 수 있을까요?
가까운 미래에는 수십억 달러가...