CPO에 관하여 Pt.2 | CPO의 경제·아키텍처적 case

s4ndwalker
2026.05.09조회수 70회
s4ndwalker
구독자 64명구독중 13명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.

Scale-out에서 cluster-level TCO 효과가 희석되는 이유, scale-up에서 Nvidia가 NVLink moat 방어를 위해 CPO 도입을 할 수 밖에 없는 이유, 그리고 병목이 packaging으로 이동하는 메커니즘.
AI cluster networking은 대체로 세 가지 fabric으로 나뉜다.

CPO 관점에서 가장 중요한 영역은 back-end network다.
기술적으로 가장 트래픽 요구가 높은 fabric이기 때문이다.
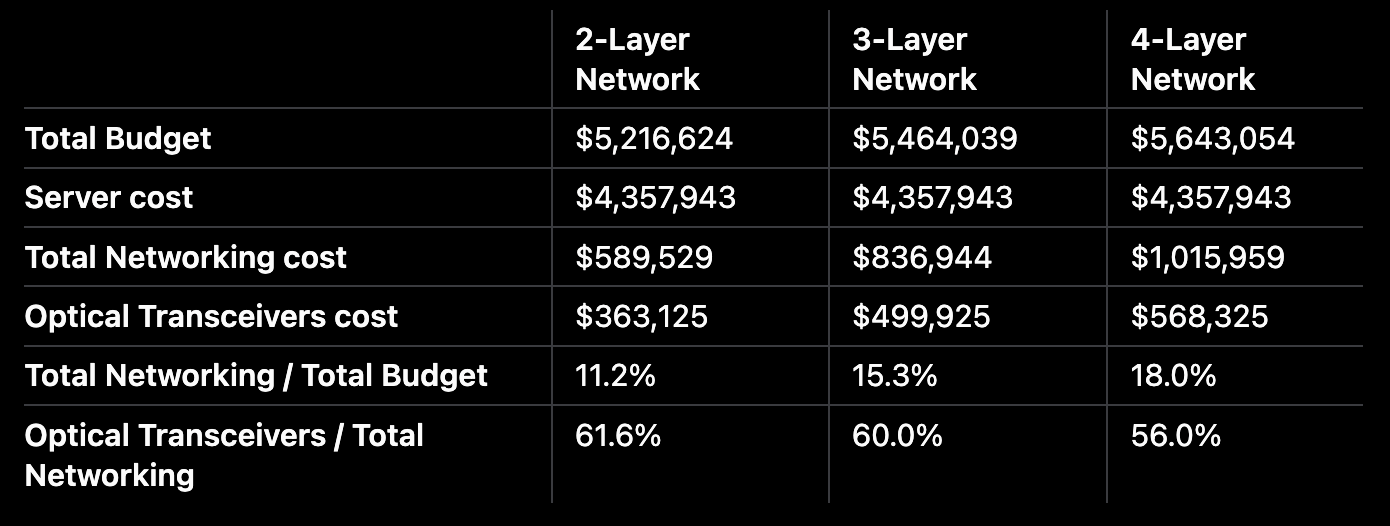
Source model에서 back-end network는 3-layer GB300 NVL72 cluster 기준 networking cost의 85%, networking power의 86%를 차지한다.
그 중에서도 절반 이상은 Pluggable Transceiver 모듈 비용이 차지한다.
AI 클러스터 내 GPU 수가 많아질수록 더 많은 네트워킹 레이어가 필요해진다. 2-layer 네트워크에서 3-layer 이상으로 확장될수록 (scale-out 수요가 증가할수록) 비용과 전력 예산은 함께 증가한다.
GB300 NVL72 한 랙의 compute system 비용 기준:
GB300 NVL72 한 랙의 compute power 수요 기준:
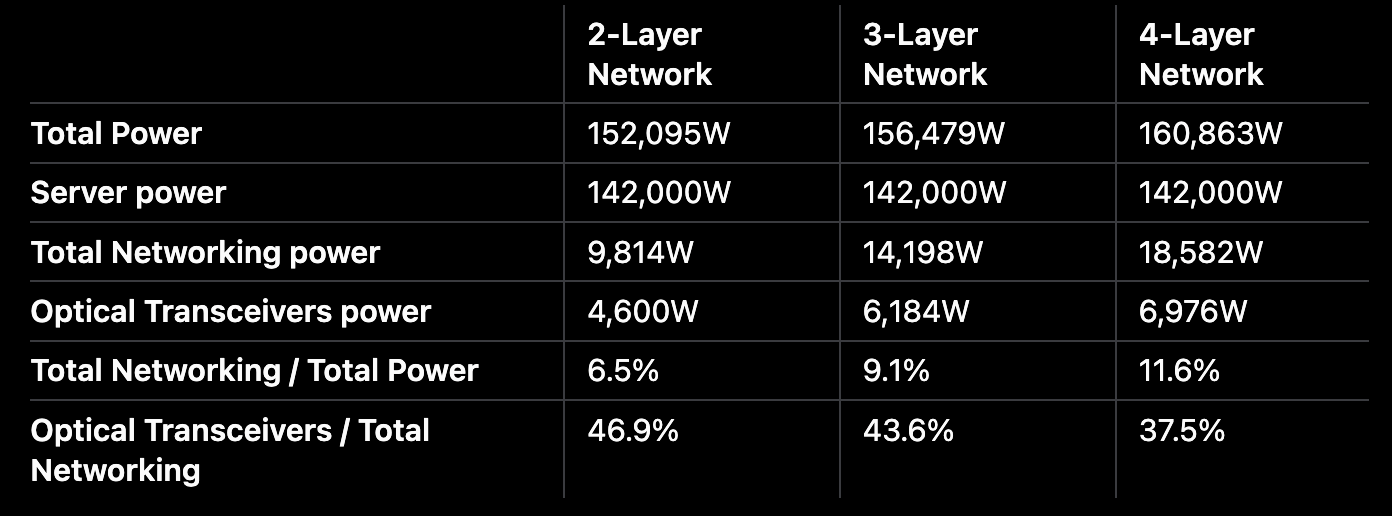
Component-level에서 power savings는 상당히 효과적이다.
800G DR4 optical transceiver는 약 16–17W를 소비하는 반면,
Nvidia Q3450 CPO switch에서 optical engine + external laser source는 800G bandwidth당 약 4–5W로 추정된다.
power consumption이 16–17W → 4–5W으로 줄어들어, 약 73% power reduction을 이루어낸다.
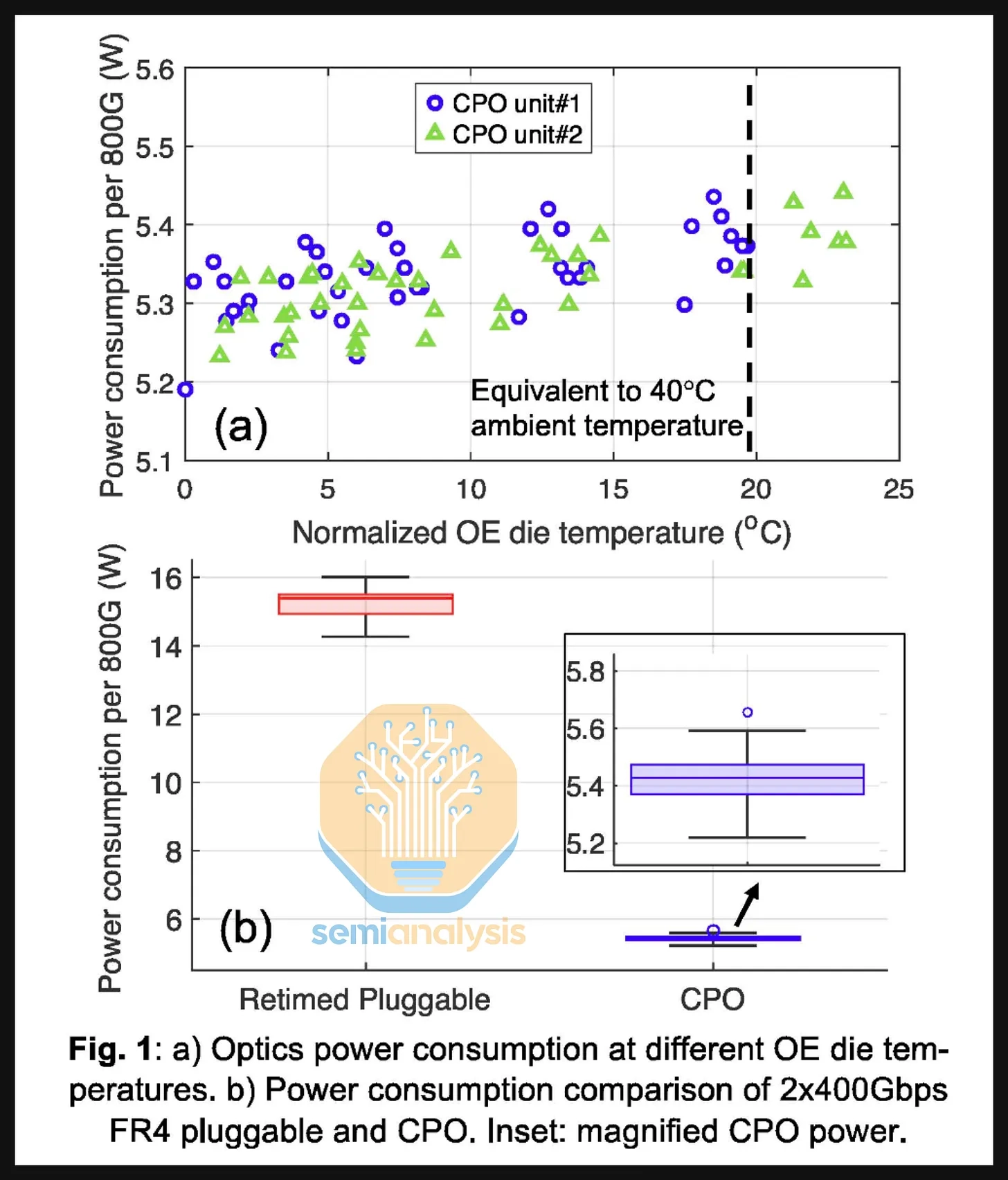
ECOC 2025에서 공개된 Meta–Broadcom의 Bailly 연구 결과에서도 800G 2xFR4 Pluggable Transceiver 약 15W vs OE + laser source 5.4W per 800G가 제시되며, 약 65% power saving으로 해석된다.
그러나 cluster-level에서는 효과가 희석된다.
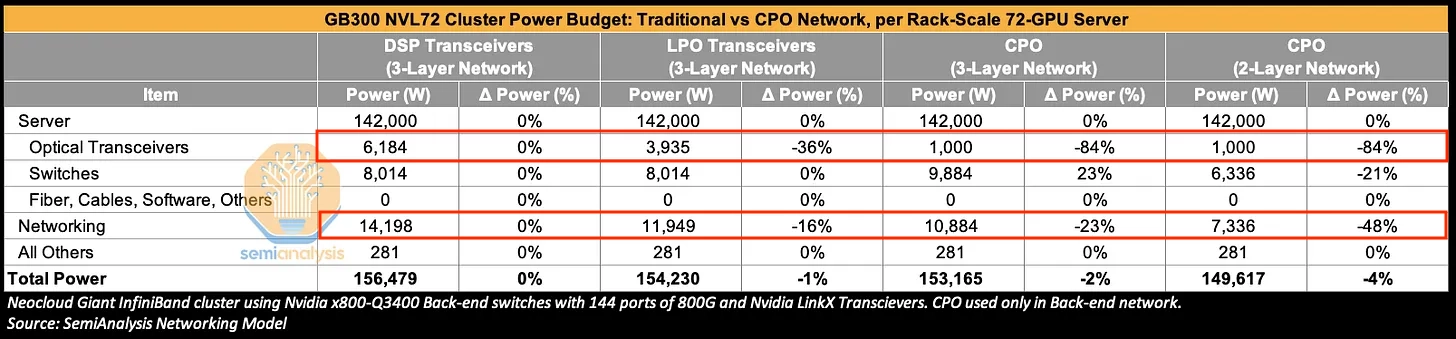
3-layer GB300 NVL72 cluster에서 DSP transceiver를 CPO로 전환하면 transceiver power는 -84%, networking power는 -23% 감소시킨다.
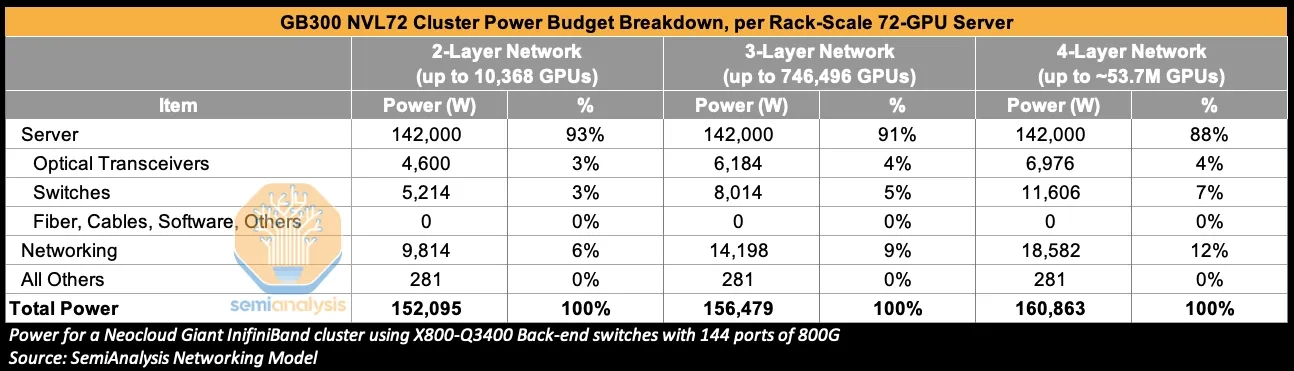
다만 networking power는 total cluster power의 약 9%다.
따라서 transceiver power -84%, networking power -23% reduction은 total cluster power 기준 약 2% saving에 그친다.
2-layer CPO network는 더 큰 networking power reduction을 만들 수 있으나 total cluster power saving은 약 4% 수준이다.
비용 측면에서도 동일한 희석이 발생한다.
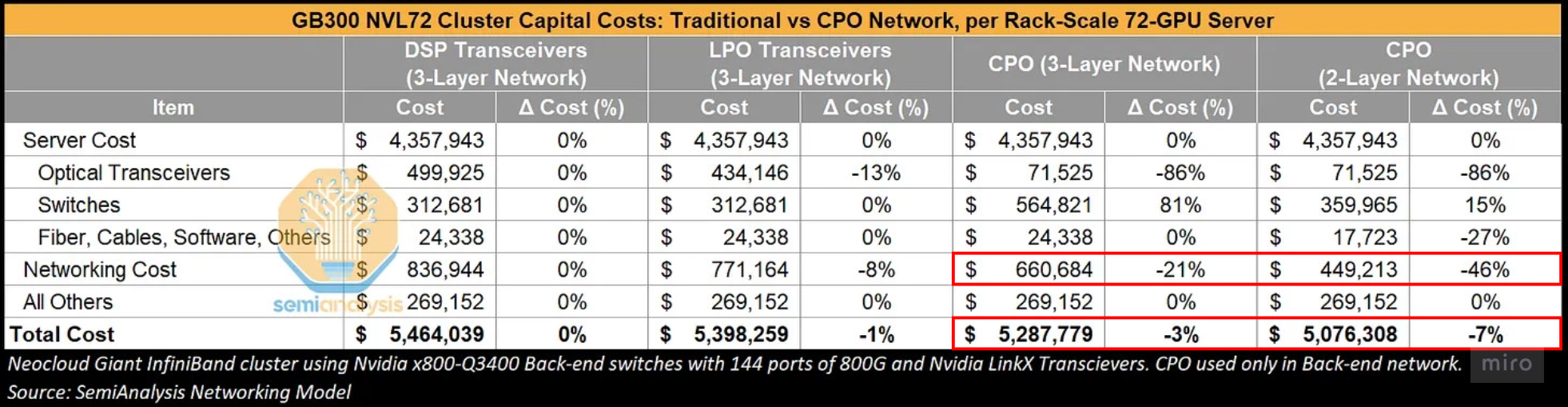
3-layer network에서 total cost는 CPO 도입으로 21% 낮아질 수 있으나, total cluster cost는 약 3% 낮아진다.
2-layer CPO network에서는 total networking cost가 약 46% 낮아질 수 있으나, total cluster cost saving은 최대 약 7%다.
Scale-out CPO는 유효한 기술이나, 그 자체만으로 하이퍼스케일러의 빠른 adoption curve를 정당화하기는 어렵다.
3–7% total cluster cost saving과 2–4% total cluster power saving만으로는 serviceability, reliability, vendor lock-in 부담을 압도하기 어렵다.
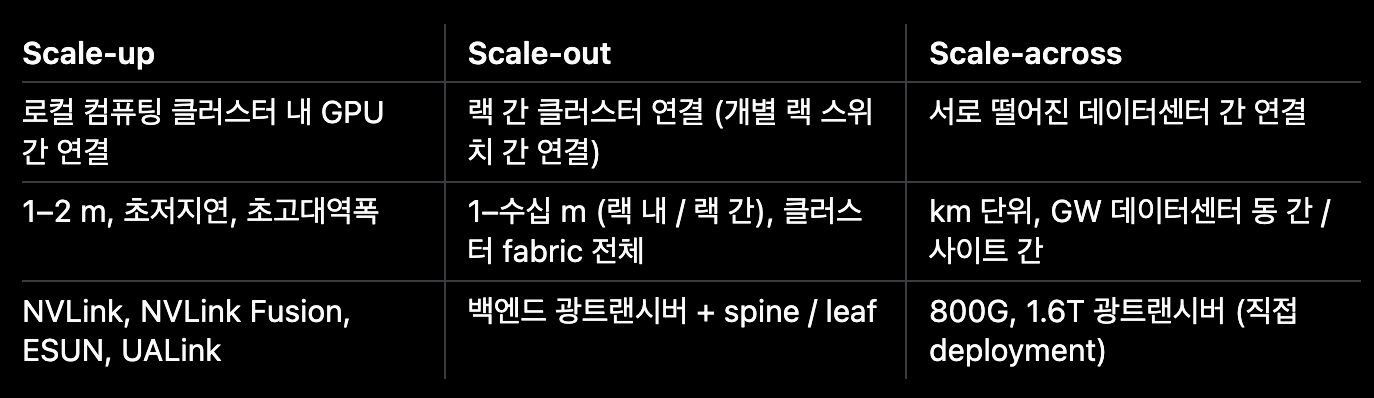
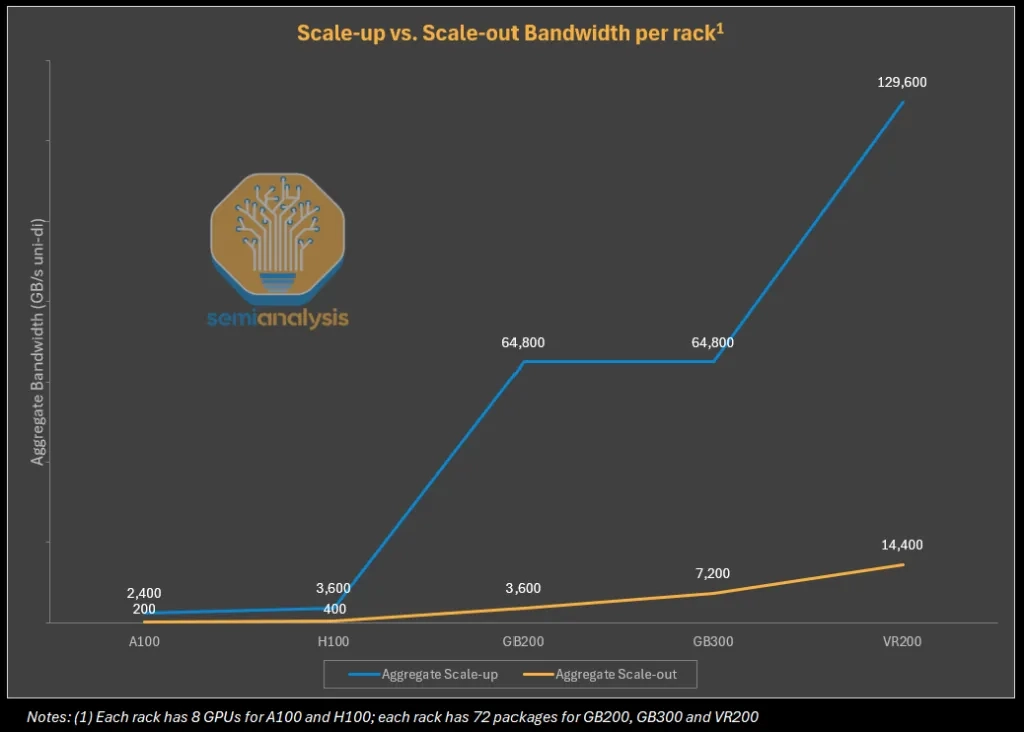
Scale-out CPO는 cost / power 문제다.
Scale-up CPO는 physics and architecture 문제다.
Scale-up fabric은 back-end scale-out network보다 훨씬 높은 bandwidth와 낮은 latency를 요구한다.
Scale-out: GB300 NVL72의 back-end scale-out network에서 CX-8 NIC 기준 GPU당 100 GByte/s (800 Gbit/s).
Scale-up: Nvidia Blackwell NVLink의 GPU당 bandwidth는 900 GByte/s (7,200 Gbit/s)이다. Scale-out 대비 약 9배 높은 수준이다.
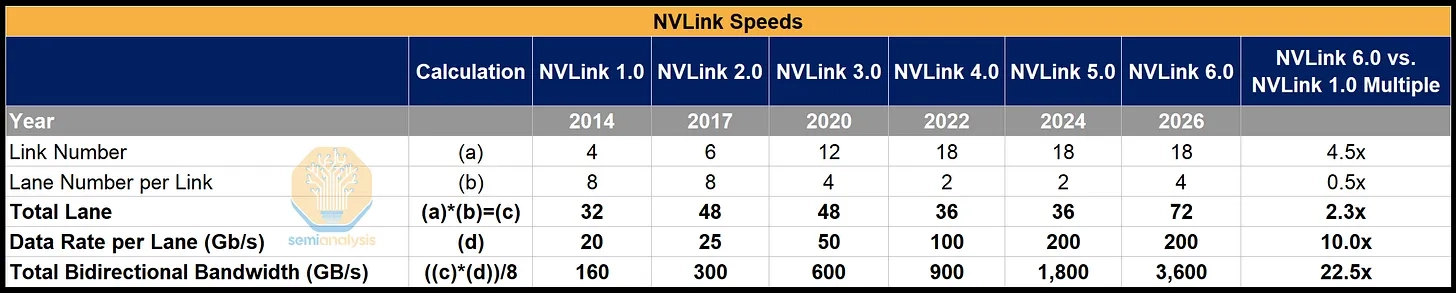
NVLink 6.0의 Total Bandwidth (TBW)는 이전 버전인 5.0 대비 2배 (1,800GB / s → 3,600GB / s) 증가했다.
NVLink 2.0부터 5.0까지는 lane별 data rate를 2배씩 증가시키면서 total bandwidth 상향을 이루었는데, NVLink 6.0부터는 lane별 data rate는 고정된 반면 total lane 수를 2배 늘렸다.
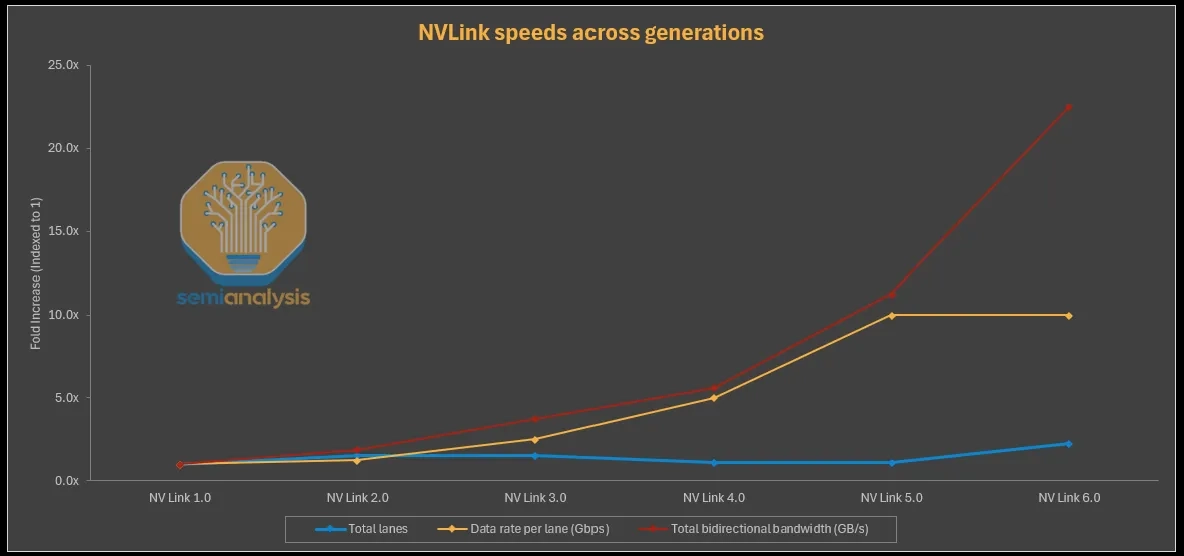
직관적으로 그래프를 통해 해석하면, total bandwidth를 계속 2배씩 올리려면 per-lane speed를 올리거나 lane count를 늘려야 한다.
NVLink 5.0까지는 link 내부 신호 밀도와 SerDes 속도를 높이고, 세대별로 GPU당 link 수를 늘리거나 유지하면서 aggregate bandwidth를 확장했다.
즉 NVLink 6.0의 핵심 변화는 lane speed-only scaling이 아닌 package / rack spine이 감당해야 하는 link·port·escape density를 2배로 끌어올림으로써 lane count를 2배로 증가시키는, shoreline bandwidth density scaling이다.
현 엔지니어링 구조를 유지할수록, 다음 세대 NVLink에서는 bandwidth scaling 부담이 더 커진다.
Total bandwidth를 2배로 늘리려면 두 가지 lever 중 하나가 필요하다. lane count를 늘리거나, per-lane data rate를 높여야 한다.
하지만 두 lever 모두 물리적 제약에 가까워지고 있다.
Per-lane data rate는 SerDes power, copper loss, signal integrity에 막히고,
lane count는 package shoreline, bump pitch, routing density에 의해 제한된다.
NVLink 6.0의 lane count 증가도 단순한 physical lane doubling은 아니다.
Total lane count가 36에서 72로 늘어난 것처럼 보이지만,
이는 기존 36개 physical copper lane을 그대로 ...
