CPO에 관하여 Pt.4 | 현존 주요 CPO Products

s4ndwalker
2026.05.09조회수 114회
s4ndwalker
구독자 64명구독중 13명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.

Nvidia (Quantum-X / Spectrum-X)와 Broadcom (Humboldt / Bailly / Davisson)의 production CPO 제품 라인업, Nvidia 세대별 도입 타임라인, 그리고 두 vendor의 진입 경로 비교.
현재 CPO production roadmap을 실제로 끌어가는 vendor는 사실상 두 곳이다 — Nvidia와 Broadcom.
두 vendor 모두 결국 TSMC COUPE platform으로 수렴하지만, 도착하는 경로와 architectural 선택은 매우 다르다.
Nvidia의 CPO roadmap은 두 단계로 나뉜다. Quantum-X는 supply chain validation을 위한 1세대 제품이고, Spectrum-X는 더 공격적인 architectural bet에 가깝다.
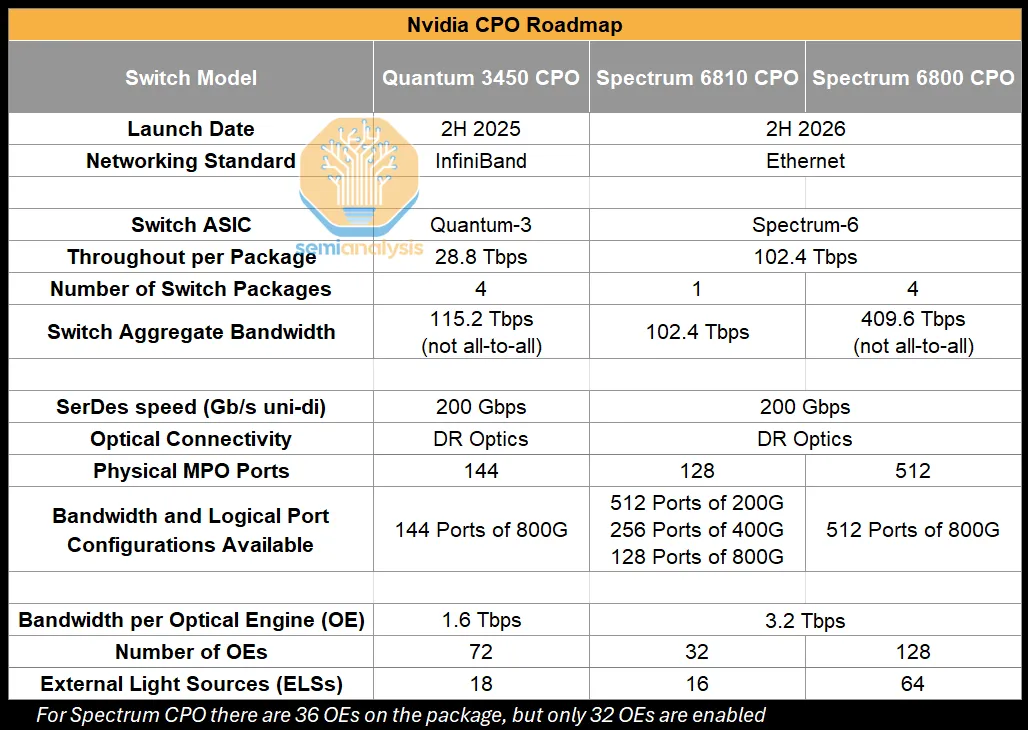
Quantum X800-Q3450 — Nvidia 1세대 production CPO switch.
Standard: InfiniBand
Launch: 2H 2025
Aggregate BW: 115.2 Tbps
OE BW: 1.6 Tbps (Gen 1)
Architecture: 4 monolithic ASICs, multi-plane
Multi-plane Architecture
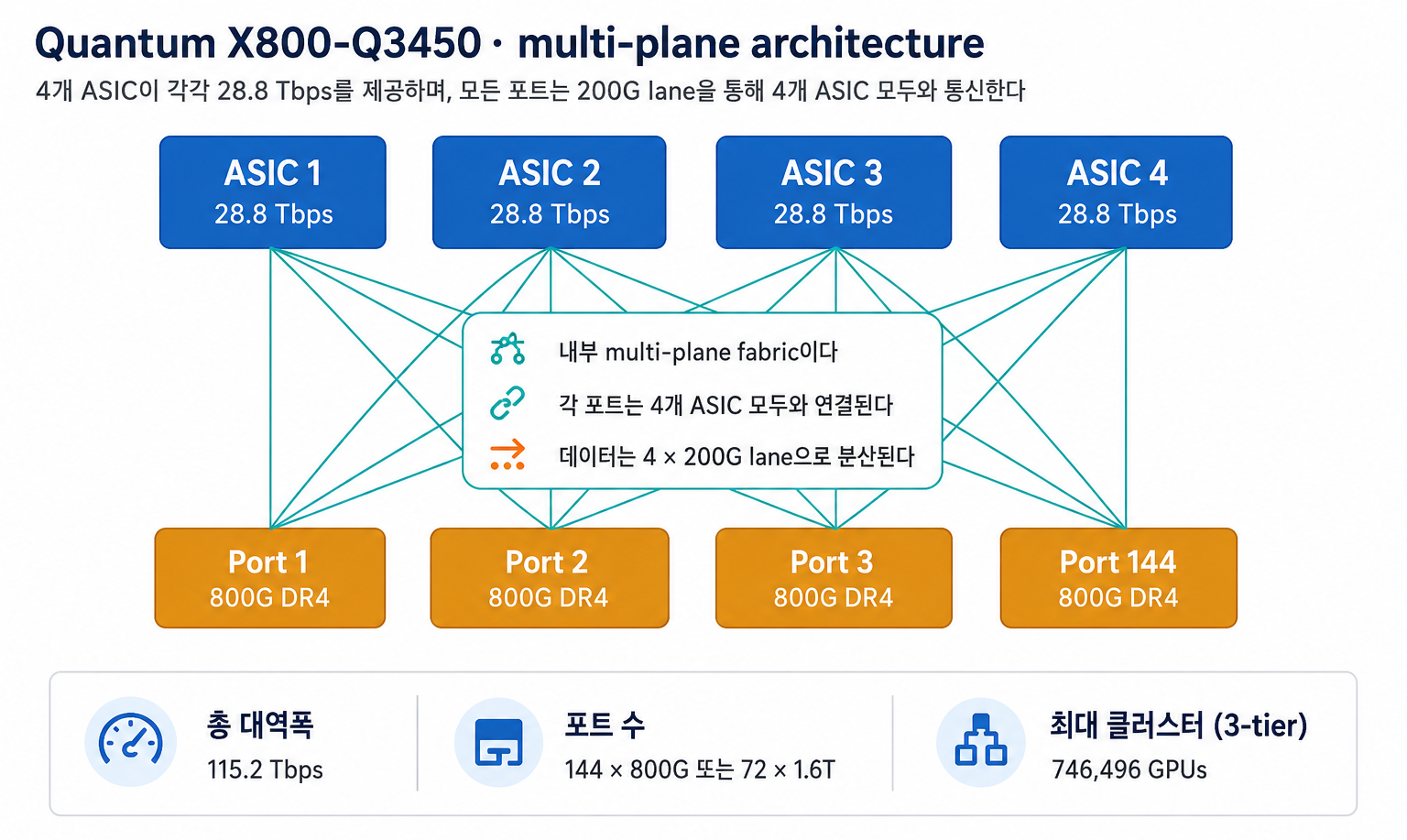
Quantum-X의 핵심은 multi-plane architecture다.
각 800G physical port는 4 × 200G lane으로 split되며, 각 lane은 서로 다른 ASIC에 연결된다.
데이터는 4개 ASIC 전체에 spray되고 destination port에서 다시 recombine된다.
결과적으로 4대의 28.8T discrete switch와 동일한 maximum cluster size (3-tier 기준 746,496 GPU)를 만들 수 있지만, shuffle이 box 내부에서 일어나기 때문에 외부 fiber complexity가 크게 줄어든다.
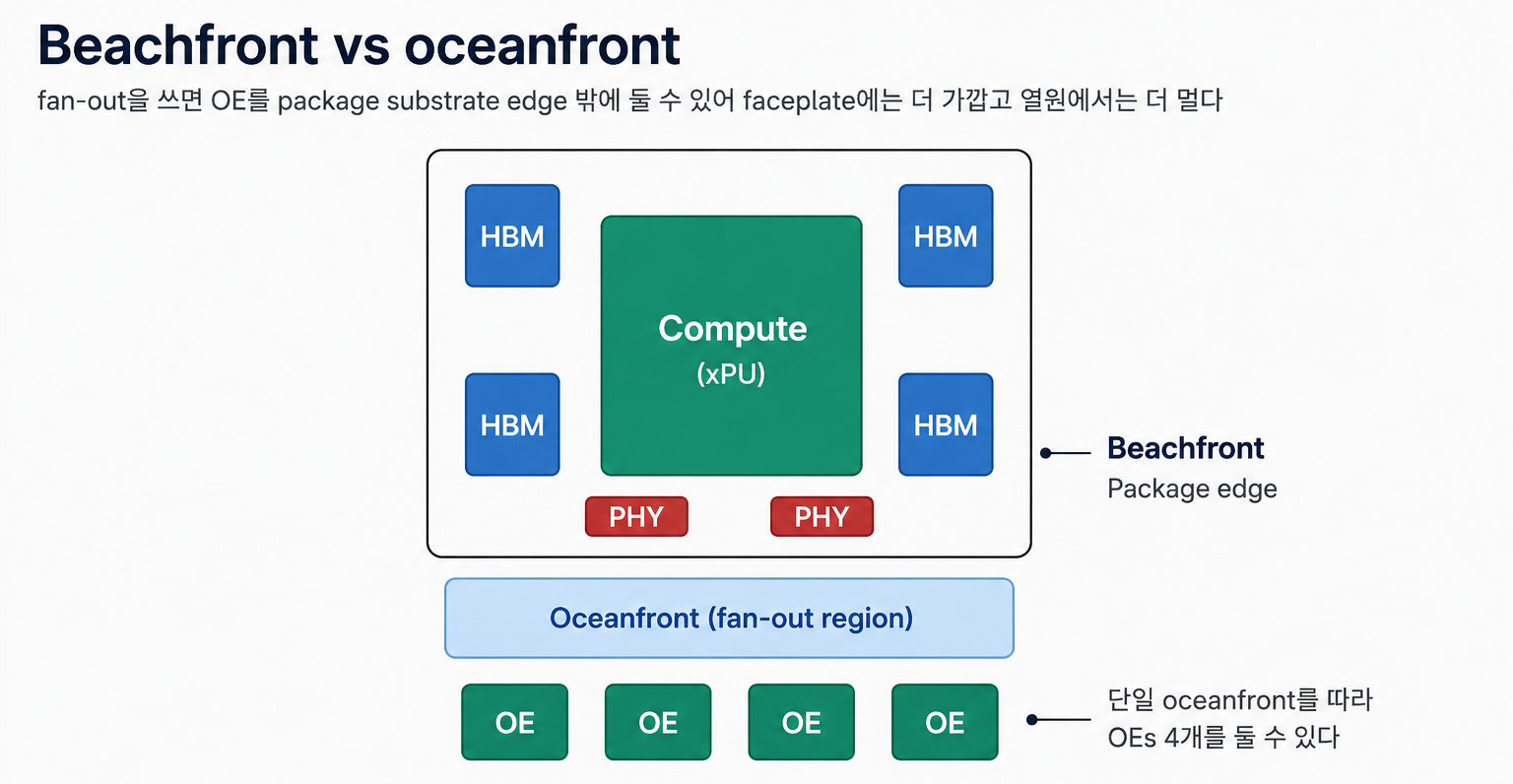
Inside the package
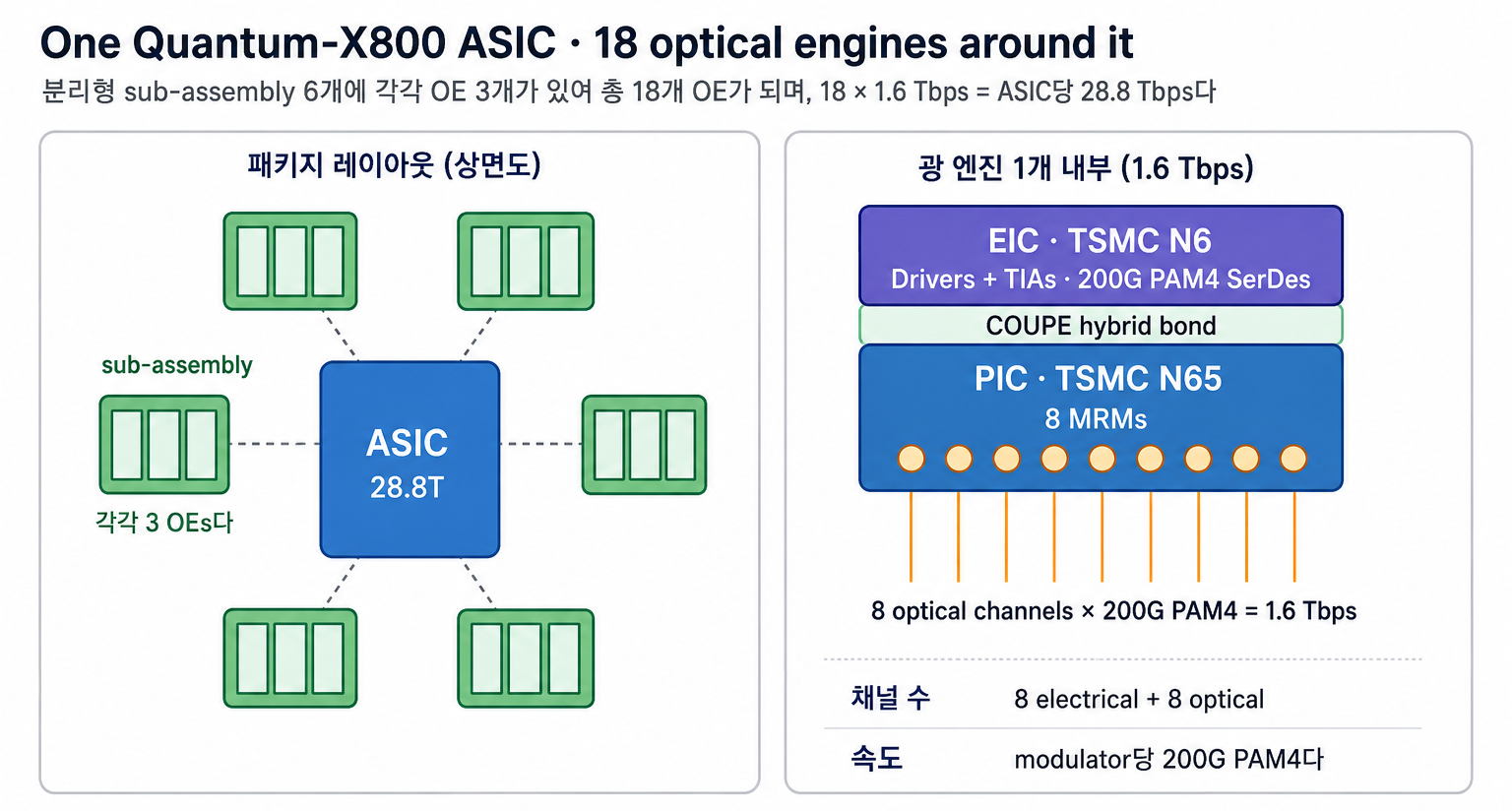
4개의 ASIC 각각은 6개의 detachable optical sub-assembly로 둘러싸여 있고, 각 sub-assembly는 3개의 optical engine을 포함한다.
ASIC당 18 OE × 1.6 Tbps = 28.8 Tbps.
Package 전체로는 4 ASIC × 18 OE = 72 OE, 4 × 28.8T = 115.2 Tbps aggregate.
Sub-assembly가 detachable이라는 점이 중요하다 — 기술적으로는 NPO에 가깝고, full CPO 대비 serviceability burden을 낮춘다.
200G MRM breakthrough
Quantum-X의 가장 중요한 engineering claim은 각 MRM이 200G PAM4로 동작한다는 점이다 (8 modulators × 200G = 1.6 Tbps per engine).
이는 가장 빠른 MZM과 동등한 수준이며, “MRM은 NRZ에 묶여있다”는 industry assumption을 뒤집은 결과다.
Nvidia + TSMC가 만들어낸 engineering 성과이고, 동시에 MRM-centric 전략을 정당화한다.
Process node split
PIC는 N65 (mature node) 위에서 제작된다. Optical component는 scaling으로 얻는 이득이 거의 없고, 오히려 larger geometry에서 더 안정적인 성능을 낸다.
EIC는 N6 (advanced node) 위에서 제작된다. Driver, TIA, control logic은 density와 power efficiency 측면에서 advanced node의 이점이 명확하다.
두 die는 TSMC COUPE의 hybrid bonding으로 sub-micron interconnect 수준에서 연결된다.
Cooling

두 개의 copper cold plate가 ASIC 위에 closed-loop liquid cooling 형태로 얹혀있다.
ASIC thermals만을 위한 것이 아니라, 온도에 민감한 MRM을 narrow operating window 안에 묶어두기 위한 장치에 가깝다.
Quantum-X 시사점
Quantum-X는 supply chain pipe-cleaner다.
Detachable sub-assembly, smaller monolithic ASIC, 비교적 보수적인 1.6T OE는 1세대 제품으로서 fault tolerance가 높다.
무언가가 fail하면 sub-assembly를 swap하면 된다. Nvidia는 full-CPO architecture에 commit하지 않은 상태에서 real-world reliability data를 확보한다.
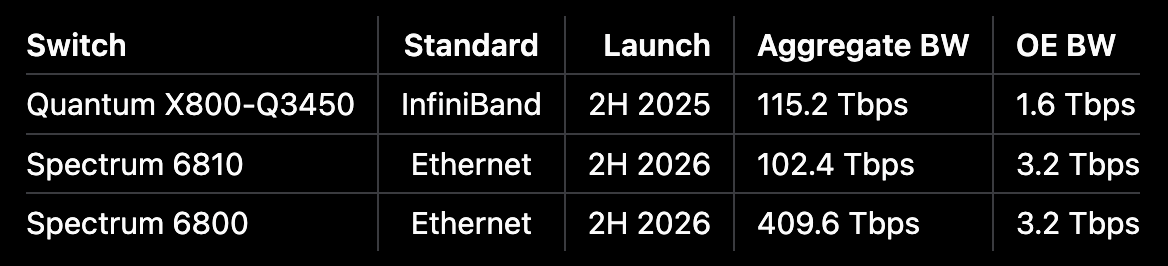
Spectrum-X Photonics — Nvidia 2세대 CPO switch (Spectrum 6810 / 6800).
Standard: Ethernet
Launch: 2H 2026
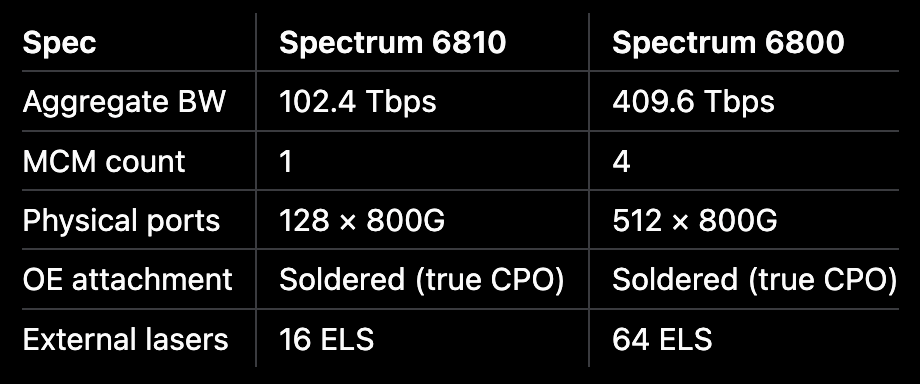
Aggregate BW: 102.4 Tbps (6810) / 409.6 Tbps (6800)
OE BW: 3.2 Tbps (Gen 2)
Architecture: Multi-chip module (MCM)
Spectrum-X는 Quantum-X와는 본질적으로 다른 architecture를 갖는다. Quantum-X가 monolithic ASIC 4개의 multi-plane 구성이라면, Spectrum-X는 훨씬 더 큰 reticle-class multi-chip module (MCM)에 기반한다.
6810은 단일 MCM을 사용하는 single-package 제품이다.
6800은 6810의 MCM (Spectrum-6 + 8 SerDes chiplet + OE 세트) 4개를 하나의 chassis 안에 통합하고, package 간 fiber shuffle을 내장해 4× aggregate bandwidth를 만든다.
Why MCM matters
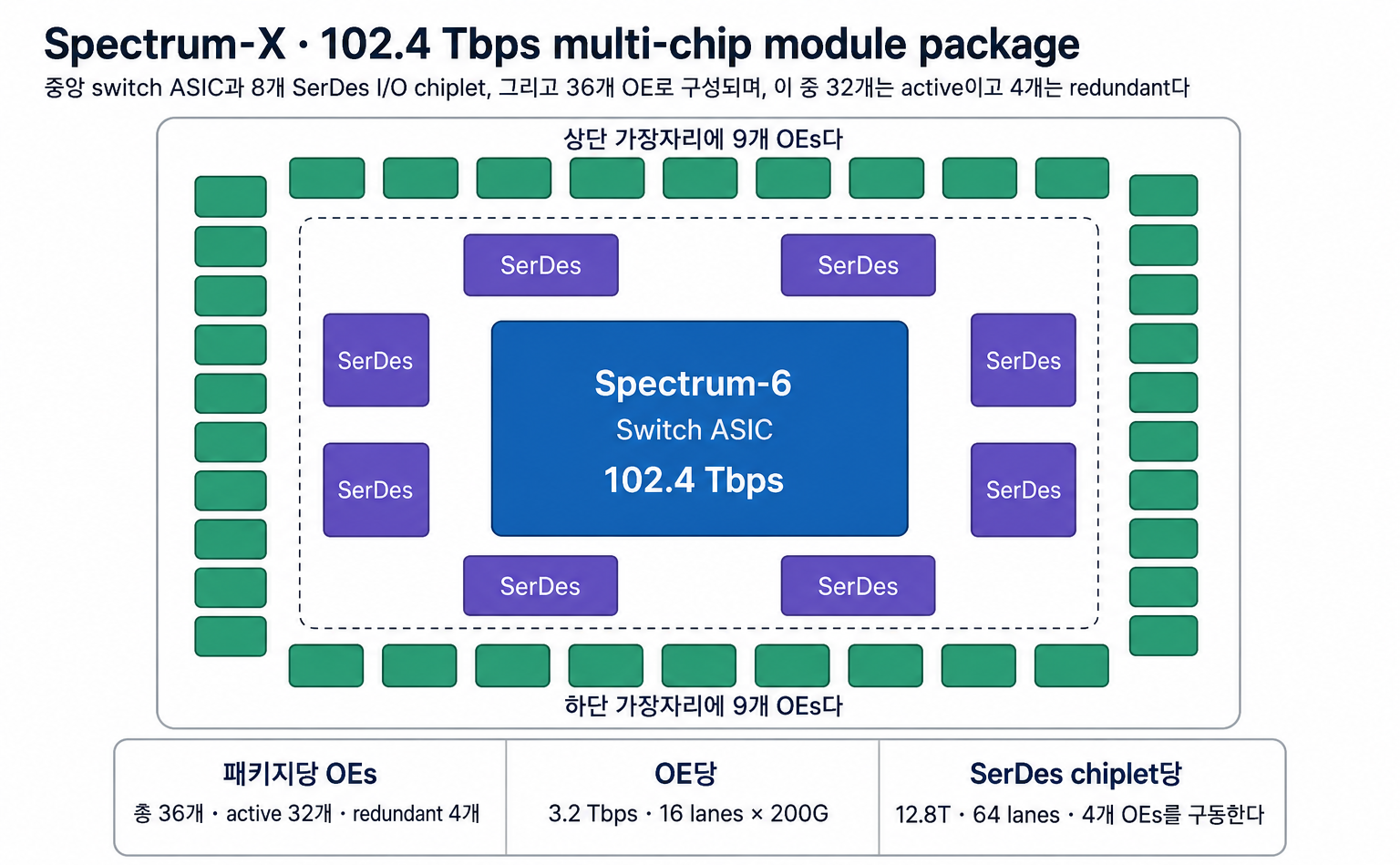
중앙의 Spectrum-6 switch ASIC은 102.4 Tbps의 reticle-class die다.
그 주위를 8개의 SerDes I/O chiplet (각 변에 2개씩)이 둘러싸며, 각 chiplet은 64 × 200G lane으로 12.8T를 처리한다.
이 분리 구조 덕분에 monolithic 대비 훨씬 더 많은 shoreline을 I / O에 할당할 수 있고, 이것이 Quantum-X 대비 4× per-package bandwidth를 가능하게 만든 핵심이다.
3.2 Tbps Optical Engine (Gen 2)
OE 하나당 16 optical lane × 200G.
Package 위에는 36개의 OE가 올라가지만, 그 중 32개만 active, 나머지 4개는 redundancy다.
Quantum-X와 달리 OE는 substrate에 soldered 되어있어 in-place replacement가 불가능하다. 즉, field에서 OE 하나가 fail하면 spare OE가 takeover하는 구조에 의존한다.
I/O chiplet 하나가 OE 4개를 feed한다 (12.8T per chiplet → 4 × 3.2T 깔끔한 fan-out).
6810 vs 6800
Spectrum-X 시사점
Spectrum-X는 architectural bet이다.
Soldered OE (no field swap), 3.2T engine, 8개 SerDes chiplet을 동반한 MCM packaging 등, 훨씬 공격적인 design이다.
이 design은 Quantum-X가 지금 build하고 있는 supply chain을 전제로 한다.
Redundant OE 4개는 “field에서 일정 비율은 fail하지만 in-place fix는 어렵다”는 현실에 대한 architectural 인정에 가깝다.
200G MRM이 두 ...


