
원문: Skew index: descriptive analysis, explanatory power and short-term forecast.
※ ChatGPT로 초벌번역 후, 매끄럽지 않은 부분은 문맥을 고려하여 임의로 수정하였습니다
초록
본 논문은 스큐 지수(Skew Index) 의 행태를 분석하며, 금융시장 연구에서 널리 사용되는 대표적 주가지수들(S&P500과 MSCI World 지수)의 분석을 통해 얻어진 일련의 기술적 사실(stylized facts, 경험적 특성)을 제시한다.
또한 스큐 지수는 투자자의 공포를 나타내는 다른 지수들(CBOE의 VIX, IVX, 금·은 지수(XAU), Bull-Bear Spread 등)과 비교된다. 분석에 사용된 데이터는 시카고 옵션거래소(CBOE) 스큐 지수의 1990년 1월부터 2018년 12월까지의 월별 데이터를 포함한다.
스큐 지수는 S&P500 지수의 꼬리 리스크 가격(tail risk price), 특히 해당 지수의 외가격(OTM) 옵션 가격을 기반으로 산출되며, 금융 재앙(financial disaster)에 대한 투자자들의 두려움으로 인해 시간이 지남에 따라 커다란 보상(compensation) 변수를 나타낸다.
마지막으로 ARIMA와 GARCH 프로세스를 활용하여 스큐 지수의 단기적인 움직임을 예측할 수 있는 모델을 개발하였다.
1. 서론
금융시장 붕괴(financial crashes)를 분석하기 위해 여러 접근 방식이 활용되어 왔으며, 그중에서도 조건부 변동성 모형(conditional volatility models)은 문헌에서 가장 일반적으로 사용된다. 본 논문은 CBOE 스큐 지수(Skew Index) 를 연구 대상으로 삼아, 이 지수가 꼬리 리스크(tail risk)를 정량화하는 데 있어 얼마나 유의미한지를 검증하고, 설명력 분석 및 ARIMA와 GARCH 같은 시계열 모형을 통해 예측 가능성을 평가하는 것을 목표로 한다.
꼬리 위험(Tail risk)이란 금융 포지션의 수익률이 평균으로부터 2~3 표준편차 이상 움직일 확률을 의미하며, 본 연구에서는 특히 손익 분포의 왼쪽 꼬리 방향(손실 방향)으로의 이동을 지칭한다. Akgiray & Booth (1988)과 같은 기존 연구들은 금융자산의 수익률 분포가 두터운 꼬리(heavy tails)를 가진다는 것을 보여주며, 이는 전통적인 정규분포(가우시안 분포)와 매우 다른 특성이다.
금융 리스크 이벤트 또는 시장 붕괴를 연구해야 하는 이유는, 수익률 분포가 두터운 꼬리를 가지는 자산 포트폴리오의 경우 단 한 번의 부정적인 이벤트만으로도 포트폴리오 전체 혹은 경제 전반의 가치가 크게 하락할 수 있기 때문이다. Xiong, Idzorek, & Ibbotson (2013)은 1929년 대공황, 1987년 블랙 먼데이(스큐 지수가 창설된 계기), 1997년 아시아 금융위기, 2000년 닷컴버블 붕괴, 2008년 글로벌 금융위기, 2014년 유가 위기 등 주요 위기를 분석하였다. 이들은 투자자들이 꼬리 리스크가 큰 자산을 보유하기 위해 추가적인 프리미엄(premium)을 요구한다는 결론을 내렸다.
[그림 1] 스큐 지수, 추세 및 주요 경제 위기
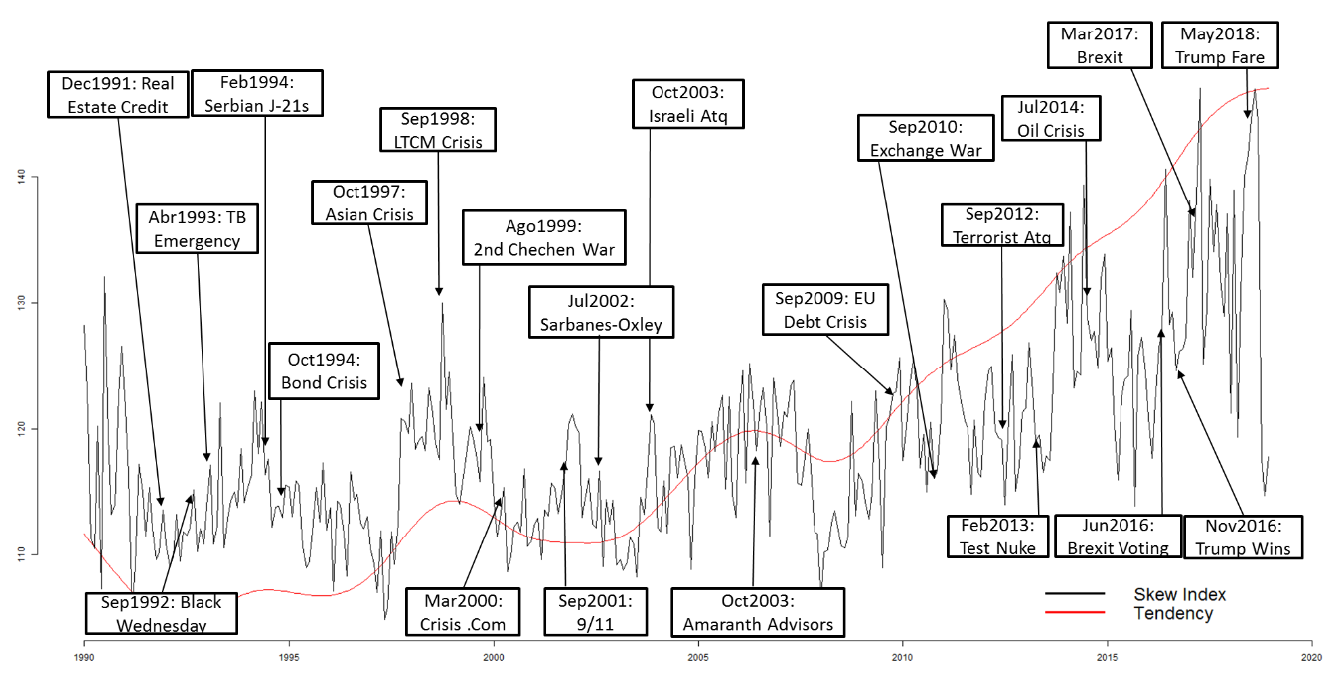
이러한 사건들은 본 연구에서 분석의 이정표(milestones)로 사용된다. [그림 1]은 스큐 지수의 움직임과 그 추세, 그리고 주요 경제 위기를 보여준다. 이 추세는 경제 및 금융 연구에서 널리 사용되는 Hodrick–Prescott(HP) 필터를 통해 생성되었으며, 시계열 데이터의 장기적 순환(cycle) 및 추세(trend) 성분을 추출하는 데 활용된다. 일반적으로 HP 필터를 사용하면 저주파 성분은 제거되고 고주파 성분은 통과하게 된다(Serletis, 2006).
CBOE 자료에 따르면, 1987년 10월에 발생한 사건들은 미국 주요 주가지수에 압력을 가했고, 일주일 만에 30% 이상 하락했으며 이는 10월 말이 되기 전에 전 세계 경제에 영향을 미쳤다. 이러한 상황은 다음과 같은 요인들에 대한 통제를 요구하게 된 주된 배경이었다:
주식의 매수·매도를 자동으로 실행하는 컴퓨터 프로그램 거래의 통제 실패
파생상품 중심의 시장 구조에서 발생한 리스크 증가 및 불확실성 확대
대량의 주식 매도로 촉발된 유동성 부족
미국 각 주 정부의 재정적자
다수 종목의 과대평가(버블) 상태 (Sornette, 2003)
이 논문의 주요 목적은 S&P500 수익률의 극단적 하락 가능성을 관측하고자 하는 투자자들의 수요에 대응하기 위해 사용되는 스큐 지수(Skew Index) 를 분석하는 것이다. CBOE의 연구에 따르면, 스큐 지수의 전형적인 값은 100 전후이며, 이때는 S&P500의 로그 수익률이 정규분포를 따른다. 그러나 이 지수가 100 이상으로 상승할수록 손익 분포의 손실 쪽 꼬리(tail)가 더 두터워지고, 해당 이벤트가 발생할 확률 또한 증가한다. 시장이 '부정적 기대 없이' 움직인다고 간주되는 경계선(일반적인 범위)은 150포인트 이하이다.
금융 문헌에서는 VIX(변동성 지수)에 대한 연구는 매우 풍부하다. 현재 VIX는 S&P500의 ATM(등가격) 옵션을 기반으로 산출된다. 일반적으로 VIX는 자본시장과 음(-)의 상관관계를 가지는 것으로 나타나는데(Gregoriou, 2013), 이는 S&P500의 기대 수익률이 높은 변동성을 보일 때 VIX 지수가 상대적으로 높게 나타난다는 뜻이다. 하지만 Black (2006)은 많은 헤지펀드의 수익률이 비대칭적이고 레프토커틱(leptokurtic, 뾰족꼬리 분포)을 보이며, 이 특성은 VIX 현물 가격에 대한 롱 포지션 헷지를 통해 완화될 수 있다고 주장한다.
이러한 이유로 Whaley (2009)는 VIX와 스큐 지수 모두 단기(30일) 기대 변동성에 대한 투자자의 심리를 반영하는 지수이며, '공포 지수(Fear Index)'로 분류된다고 반복적으로 설명하였다.
한편, 스큐 지수(Skew Index) 는 S&P500의 외가격(OTM) 옵션 가격을 기반으로 계산된다. 특히, OTM 풋옵션의 가격은 포트폴리오 보험에 대한 수요에 관한 중요한 정보를 포함하고 있으며, 그 결과 시장 변동성을 반영한다(Whaley, 2009). 이는 시장 수익률과 변동성 사이의 높은 음(-)의 상관관계에 기인하는데, Aboura & Chevallier (2016)에 따르면 이러한 상관관계는 S&P500의 로그 수익률 분포에서의 꼬리 리스크(tail risk) 를 30일 시계열 구간 내에서 측정하는 것이다.
따라서, S&P500 수익률의 꼬리 리스크가 증가할수록 계산된 스큐 지수의 값도 증가할 것으로 예상된다.
VIX와 스큐 지수 사이의 중요한 차이점은 다음과 같다
스큐 지수는 분포의 비대칭성(asymmetry)에 따른 영향을 측정하며,
VIX는 변동성 리스크(volatility risk)의 영향을 근사적으로 측정한다(Aboura & Chevallier, 2016).
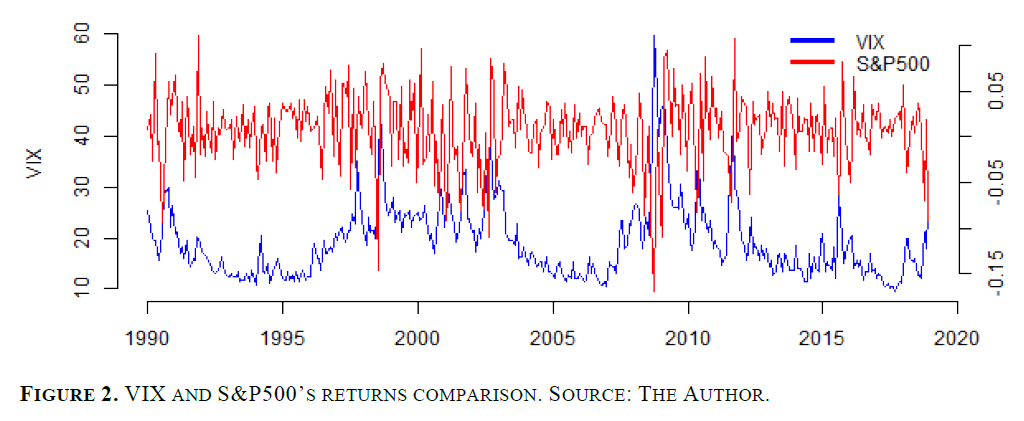
[그림 2] VIX 지수와 S&P500 수익률 비교
[그림 3] 스큐 인덱스와 S&P500 수익률 비교
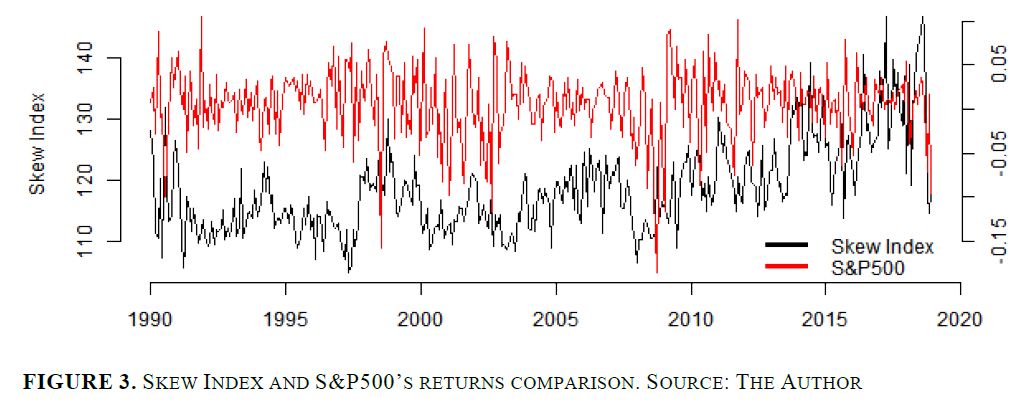
그레고리우(Gregoriou, 2013)의 가설은 [그림 2]에서 확인할 수 있듯이 입증된다. 그는 VIX가 미국 자본시장(S&P500을 대표 지수로 사용) 수익률과 높은 음의 상관관계를 가진다고 주장하였다. 본 연구에서는 VIX와 S&P500 수익률 간의 월간 상관계수가 -0.3782로 나타났으며(Appendix 1 참조), 이는 그의 주장과 일치한다. 반면, S&P500 수익률과 스큐 지수 간의 상관관계는 약하며, 상관계수는 0.119에 불과하다.
그러나 VIX와 스큐 지수는 공통적으로 투자자들이 인식하는 변동성과 꼬리 리스크(tail risk)를 정량화하는 도구라는 점에서 유사하다(Guillaume, 2015). 두 지수 간의 상관계수는 -0.2368로 나타났다.
추가적으로, Gregoriou (2013)는 VIX 흐름(fear index flow) 과 S&P500 수익률 간의 상관관계가 글로벌 금융위기처럼 시장이 급변할 때 더 강해진다고 주장하였다. 특히 2008년 9월부터 2009년 3월까지 그 상관성이 증가했다는 분석을 제시하였다.
한편, 시장 참여자 및 규제 당국의 주요 관심사 중 하나는 극단적인 시장 움직임 중에 국제 금융시장에서 발생하는 시스템 리스크(systematic risk) 이다(Trabelsi & Naifar, 2017). 따라서 이러한 상황을 예측하고, 시장 참여자 전반을 위한 보다 나은 추정치를 제공하기 위해 해당 리스크의 예측 방법을 연구하는 것이 필수적이다.
또한 시장 변동성과 관련된 중요한 요인 중 하나는 정보 그 자체이며, 기업이 정보를 숨기는 전략, 그리고 정보 공시를 강제하려는 법제도도 포함된다. 이 맥락에서 2002년 7월 30일에 제정된 사베인스-옥슬리법(Sarbanes-Oxley Act) 은 중요한 분석 대상이다. 기존 연구(Hutton, Marcus, & Tehranian, 2009)에 따르면 이 법률은 이익 조정(profit management) 행위 감소 또는 기업이 내부 정보를 숨기기 어려워졌다는 결과로 이어질 수 있다. 그림 1에서도 이러한 규제가 스큐 지수의 움직임에 어떤 영향을 주었는지 확인할 수 있으며, 이는 뉴스 및 규제가 경제와 그 지표들의 형태를 결정짓는 데 중요한 역할을 한다는 것을 시사한다.
이 논문의 구성은 다음과 같다:
2장에서는 VIX와 같은 공포 지수에 대한 기존 금융 시계열 연구들을 정리한다.
3장에서는 Cont (2001)의 연구를 기반으로, 스큐 지수의 기술적 분석과 경험적 특성을 설명한다.
4장에서는 시계열 모형(ARIMA, GARCH 등)을 활용한 예측 방법론을 제시한다.
5장에서는 본 연구의 결론을 제시한다.
2. 문헌 리뷰
주식시장 지수가 도입된 이후, 이를 대상으로 한 다양한 연구들이 진행되어 왔으며, 그중에서도 VIX(변동성 지수) 는 반복적으로 활용되어 온 대표적인 지표이다. 하지만 스큐 지수(Skew Index) 는 아직까지 학계나 투자자들 사이에서 충분히 조명되지 않은 영역이며, 따라서 본 연구는 S&P500 및 전체 시장에서 이 지수가 가지는 중요성을 이해하는 데 핵심적인 기여를 한다.
Kaeck & Alexander (2013)는 VIX의 급등(jump)은 오히려 상대적으로 평온한 시기에 더 자주 발생한다는 사실을 발견하였다. 또한, 이들은 VIX가 급등했던 날이 주요 정치 또는 경제 이벤트와 일치하는지를 추적하였다. 이러한 분석은 본 연구에서도 스큐 지수에 대해 동일하게 검증하고자 하는 주요 사실 중 하나이다.
이와 유사한 맥락에서, Constantinides는 2011년에 VIX의 한계값을 경제 위기의 주요 시점과 비교하여 분석한 바 있으며, 이는 스큐 지수가 임계 구간을 초과하는 현상을 관찰할 때의 기준선(reference)으로 활용된다(Constantinides, Czerwonko, Jackwerth, & Perrakis, 2011). 이 연구 역시 앞서 언급된 역사적 사건들을 분석의 전환점(turning points) 으로 삼는다.
또 다른 변동성 분석 시각은 Fan et al. (2016) 의 연구에서 확인할 수 있는데, 이들은 금융업계 전문가들이 변동성 리스크 프리미엄의 부호(sign) 를 통해 향후 변동성 수준에 대한 시장 기대를 파악하고 있다는 점을 지적하였다. 또한, 고빈도 데이터의 확산이 리스크 프리미엄을 보다 정밀하게 측정할 수 있도록 해준다는 점도 제시하였다.
한편 Kelly & Jiang (2014) 는 테일 리스크(tail risk)가 주식시장 수익률 예측에 있어 매우 강한 설명력을 갖고 있으며, 이 효과는 1개월부터 5년까지의 다양한 기간(horizon)에 걸쳐 유효하다는 것을 발견하였다. 더불어 테일 리스크는 주식 및 풋옵션 수익률의 횡단면(cross-section)에 대한 설명력도 갖는다고 결론 내렸다.
Szado (2009) 는 다양한 비율의 주식과 채권으로 구성된 전통적 포트폴리오와 고수익 채권, 헤지펀드 등 대체자산을 포함한 포트폴리오를 비교 분석하면서, VIX 현물지수(spot VIX) 와 장기 변동성 노출(long volatility exposure) 이 시장 침체나 위기 상황에서 포트폴리오 보호 수단으로 유용할 수 있음을 주장하였다. 이 분석은 본 연구와 마찬가지로 공포 지수(fear index) 의 비교적 방법론과, 이를 통해 예상 시장 변동성 및 글로벌 경제에 대한 정보 도출이라는 목적을 공유한다는 점에서 유의미하다.
기타 연구들은 VIX 지수를 다양한 금융 도구 접근법을 통해 분석한다. 예를 들어, 미국예탁증서(ADR)를 활용한 연구에서 Esqueda, Luo, & Jackson (2015)은 VIX가 GARCH-M 모형으로 적절히 예측될 수 있음을 발견하였다. Mills & Markellos (2008)에 따르면, 이는 예측 모형에 사용된 오차항의 자기상관(serial correlation) 또는 이분산성(heteroscedasticity)에 대해 잘 알려지지 않은 경우 사용되는 추정 기법이다.
이들은 (G)ARCH-in-mean 모형을 사용하여 위험 프리미엄을 분석하고 주식 수익률의 변동성을 모델링하는데, 이때 조건부 분산(conditional variance) 을 회귀 설명 변수로 활용한다.
McNeil & Frey (2000)은, 조건부 분포 접근 방식(즉, 수익률 분포를 현재의 변동성 지수에 조건화시킨 방식)이 비조건부 접근 방식(수익률 생성 과정의 주변 분포를 추정하려는 방식)보다 VaR(Value-at-Risk) 추정에 더 적합하다고 주장하였다. 이때 사용되는 모델링 시스템은 GARCH 모형에 기반한다. 조건부 변동성을 추정하기 위해 Akaike 정보 기준(AIC) 및/또는 Bayesian 정보 기준(BIC) 을 활용하여, 제안된 예측 모형 중 Skew Index의 과거 행태에 가장 적합한 시스템을 선택한다. 또한, GARCH 모형에서의 혁신(innovation)의 꼬리 부분을 보정하기 위해 극단값 이론(EVT) 도 함께 사용된다.
GARCH 모델과 관련하여, 환율 분석에 있어서는 보다 정교한 시스템들이 기본적인 GARCH(1,1) 모델을 능가하기 어렵다는 실증적 증거가 존재한다(Hansen & Lunde, 2005). 이 연구에서 제시되는 하나의 아이디어는 바로 우월한 예측력(Superior Predictive Ability, SPA) 을 검정하는 방법의 활용이다.
요약하자면, 지금까지의 연구들은 모두 지수의 변동성을 유발하는 원인들과 그 원인들이 포트폴리오 가격에 어떤 영향을 미치는지를 규명하려는 목적을 가지고 있었다. 이러한 원인을 분석함으로써, 지수들의 예측력을 향상시킬 수 있을 것이라는 기대가 가능하다.
이러한 맥락에서, 본 연구는 시장 지수로서의 S&P500을 분석할 때, 경제 모형 내에서 어떤 동태(dynamics)가 존재하는지를 관찰하고자 한다.
3. SKEW 지수 및 기타 지수의 기술적 분석
이 절에서는 자본시장의 대리 지표로 사용되는 지수들(S&P500 및 MSCI World Index)과, 문헌에서 제안된 공포 지수들(VIX 및 스큐 지수)에 대한 통계 분석을 통해 도출된 경험적 특성(stylized facts)을 제시한다. 아울러, 덜 분석된 기타 공포 지수들도 함께 제시되며, 이러한 공포 지수들의 선형결합을 통해 S&P500의 향후 30일간 움직임을 설명하려는 시도가 이루어진다.
3.1 경험적 특성 (Empirical Characteristics)
Cont (2001)의 접근법을 따르며, 스큐 지수의 통계적 특성은 실증 연구의 기초 단계로 분석된다. 이는 스큐 지수에 대한 기존 문헌에서는 잘 다뤄지지 않은 부분이므로, 본 연구에서 매우 중요한 요소라 할 수 있다.
분석의 출발점은 평균으로부터의 편차(deviation from the mean) 를 살펴보는 것이며, 이는 지수의 변동성에서 꼬리 구조(tail structure) 를 결정짓는 핵심 요소이다. 정규분포(normal distribution) 로부터의 편차를 정량적으로 측정하는 한 가지 방법은 분포의 첨도(kurtosis) 를 계산하는 것이다. 이때 사용되는 계산식은 다음과 같다.
여기서 는 평균에 대한 4차 모멘트(fourth moment) 를 의미하고, 는 표준편차이다. Joanes & Gill (1998)에 따르면, 첨도(kurtosis)가 클수록 지수 값들이 평균에 더 가까이 집중되는 경향이 있고, 동시에 꼬리가 두꺼운 분포(heavy tails) 를 가진다는 것을 의미한다. 즉, 극단적인 값들이 자주 반복해서 발생할 가능성이 높다는 것이다.
또 다른 고려 요소는 해당 함수 의 비대칭성(asymmetry) 이다.
Joanes & Gill (1998)에 따르면, 평균 기준 오른쪽 꼬리에 데이터가 더 많이 집중되어 있는 경우, 양(+)의 비대칭성(positive asymmetry) 이 존재하는 것으로 간주된다. 이는 음(-)의 수익률 발생 확률이 더 낮다는 것을 나타낸다.
정규성(normality)을 검정하기 위해 Jarque–Bera(JB) 검정을 사용할 수 있으며, 이 검정은 첨도(kurtosis) 와 왜도(skewness) 를 함께 통합한 지표로, 다음과 같이 정의된다.
여기서 n은 관측치의 수이며, k는 사용된 회귀 설명변수(regressor)의 수이다. 첨도(C) 와 왜도(S) 를 동시에 포함하는 이 결합된 모델(Jarque–Bera test) 의 장점은, 해당 데이터 집합이 정규분포(가우시안)를 따른다고 판단하기 위해 두 가지 조건을 동시에 만족해야 한다는 점이다.
계량경제학(Econometrics)과 시계열 분석(Time Series Analysis)에서는 Jarque–Bera 정규성 검정이 단순성과 만족스러운 성능 덕분에 광범위하게 사용되어 왔다. 이 검정의 귀무가설은 해당 시계열이 정규분포를 따른다는 것이며, p-value가 0.05 미만이면 해당 시계열이 정규성을 따르지 않는다고 해석할 수 있다(Górecki, Hörmann, Horváth, & Kokoszka, 2018).
마지막으로, 선형 시계열(linear time series)의 자기상관함수(ACF) 를 추론하기 위한 가장 일반적인 검정 중 하나인 Ljung–Box 검정이 있다. 이때, 임의의 시계열의 ACF는 다음과 같은 식으로 정의된다.
위 수식은 Ljung–Box 검정(Ljung–Box test) 을 다음과 같이 정의하는 데 사용된다.
여기서 T는 시간의 최대 구간(length of the time series), h는 데이터 간의 시차(horizon)를 의미한다. Ljung–Box 검정은 고정된 시차 수 H 에 대해 카이제곱 분포( )에 점근적으로 수렴한다(Hassani & Yeganegi, 2019). 이 검정의 귀무가설(null hypothesis) 은 시계열이 백색잡음(white noise)처럼 동작한다는 것이다. 즉, 자기상관이 존재하지 않는 무작위적 시계열이라는 것을 전제로 한다.
3.2 기술통계량 (Descriptive Statistics)
앞 절에서 제시된 공식을 S&P500 및 MSCI World 시장 지수의 월간 수익률, 그리고 관측된 VIX 및 스큐 지수(Skew Index) 값에 적용하면, 각 지표에 대한 기술통계량(statistics) 은 다음과 같이 산출된다.
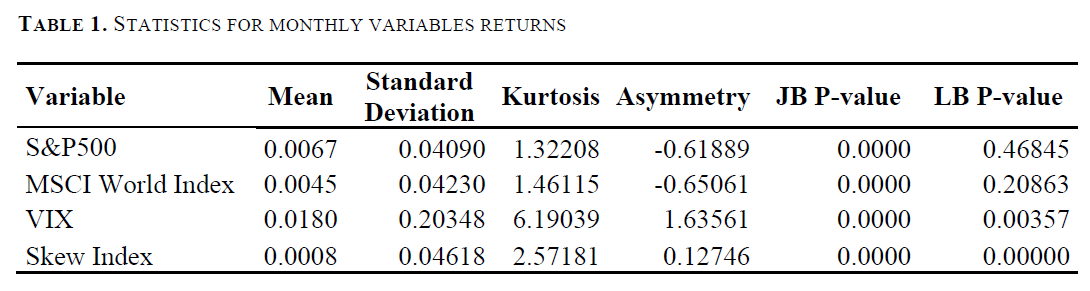
[표 1]에서 확인할 수 있듯이, 모든 월간화된 변수들의 수익률 평균은 0을 중심으로 움직이고 있다. 또한, Jarque-Bera 검정의 p-value 결과는 시장 지수든 공포 지수든 어떤 지표도 정규분포를 따르지 않는다는 점을 보여준다. 반면, Ljung–Box 검정 결과는 S&P500 지수와 MSCI 지수 모두 자기상관이 없음을 의미한다.
이러한 정보들을 종합하면, 해당 시계열 데이터들은 완전히 무작위적(Random Walk) 으로 움직이며, 수익률의 기대값이 0이라는 점에서 효율적 시장 가설(특히 약형, weak-form)에 대한 계량경제학적 함의를 제공한다(Fama, 1965; Samuelson, 1965). 만약 이 조건들이 충족되지 않는다면, 차익거래(arbitrage) 가 가능하거나 주가지수 수준을 예측할 수 있는 여지가 생기게 된다.
또한, ...
![[번역] 변동성 스큐에는 정보가 존재하는가?](https://post-image.valley.town/NPgthmva-6zIuVw4sTOR_.png)
![[번역] 옵션 내재변동성과 왜도를 이용한 포트폴리오 선택의 개선](https://post-image.valley.town/oyQ74AQHOgyuU_ID5a6dw.png)
![[번역] 주가지수 수익률의 선행지표로서의 내재변동성 지수](https://post-image.valley.town/FD-ErTT7ob3P9_faIz_XD.png)
![[번역] 위험중립 왜도(Risk-Neutral Skewness)의 만기 구조가 담고 있는 정보](https://post-image.valley.town/DLdfBv3dM5Ee-YGp73sMA.png)
![[번역] 딜러의 옵션 플로우가 주식 수익률에 미치는 영향](https://post-image.valley.town/2XZsmjvtsLIO4nACkLdoN.png)