Vera Rubin Decoded Pt. 5 | 랙 전력과 네트워킹 fabric

s4ndwalker
2026.05.26조회수 78회
s4ndwalker
구독자 67명구독중 13명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.

시리즈 안내 ⎯ Series Map
Part 1: 플랫폼 개요와 아키텍처 맵 — Blackwell → Rubin 플랫폼의 핵심과 주요 사양
Part 2: Rubin GPU 엔지니어링 심층 분석 — process node, SM, HBM4, NVLink-C2C, 패키지, CPX와 Groq 3 LPX
Part 3: Vera CPU와 네트워킹 실리콘 제품군 — Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6
Part 4: 랙 조립 — 트레이, PCB, 쿨링 — HGX와 NVL72, 컴퓨트 트레이 모듈, cableless 미드플레인, PCB 업그레이드, 액체 냉각
Part 5 (현재 글): 랙 전력과 네트워킹 fabric — 전력 공급, HVDC, tray ↔ rack 배선, scale-up NVLink 6, scale-out InfiniBand와 Ethernet
Part 6: 공급망 마스터 레퍼런스 — sub-system별 공급사 정리
Part 4에서 이어진다. 동일한 NVL72 랙을, 이제는 전력 공급에서 시작해 네트워킹 fabric 이후까지 살펴본다.
랙당 TDP: 180~220 kW (GB200/GB300은 120~140 kW). 전력 공급 과정은 세 단계로 나뉜다.
Step 1: AC 전원 → 50 V DC (rack power shelf)

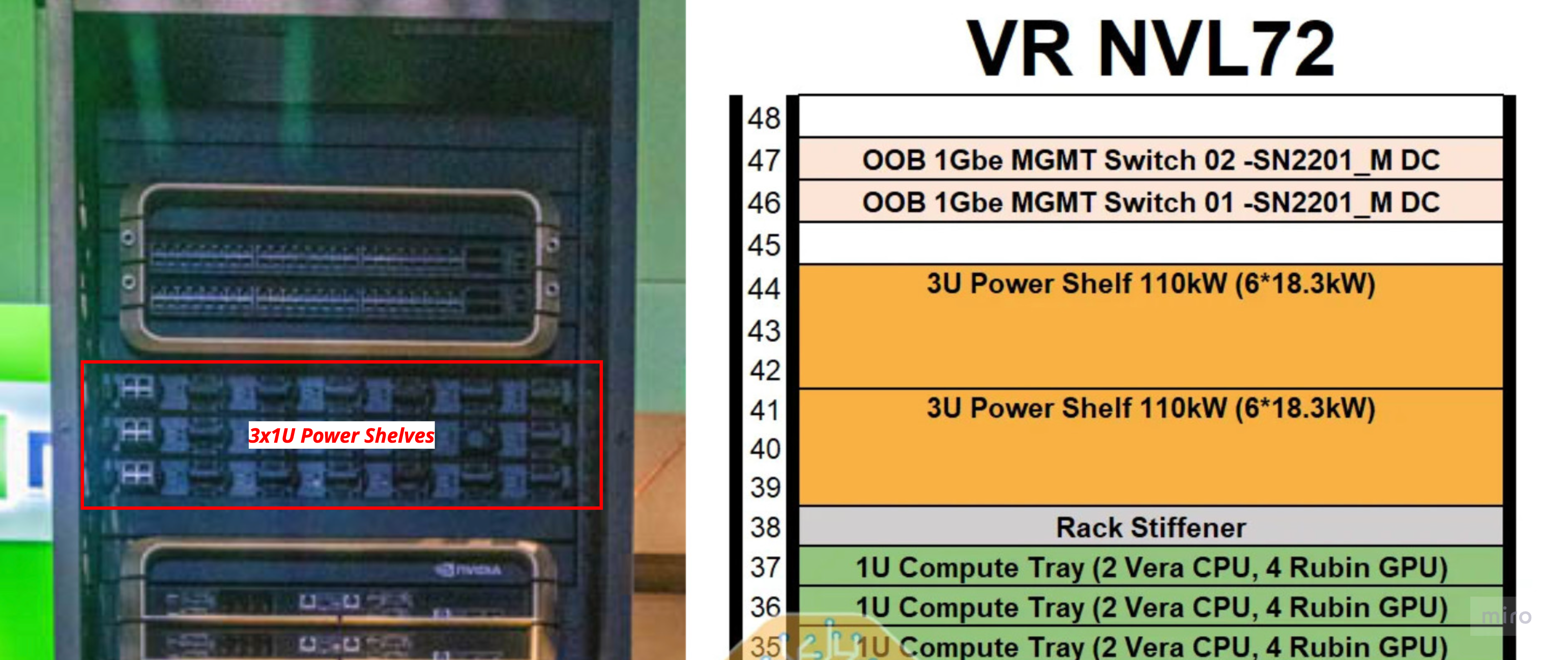
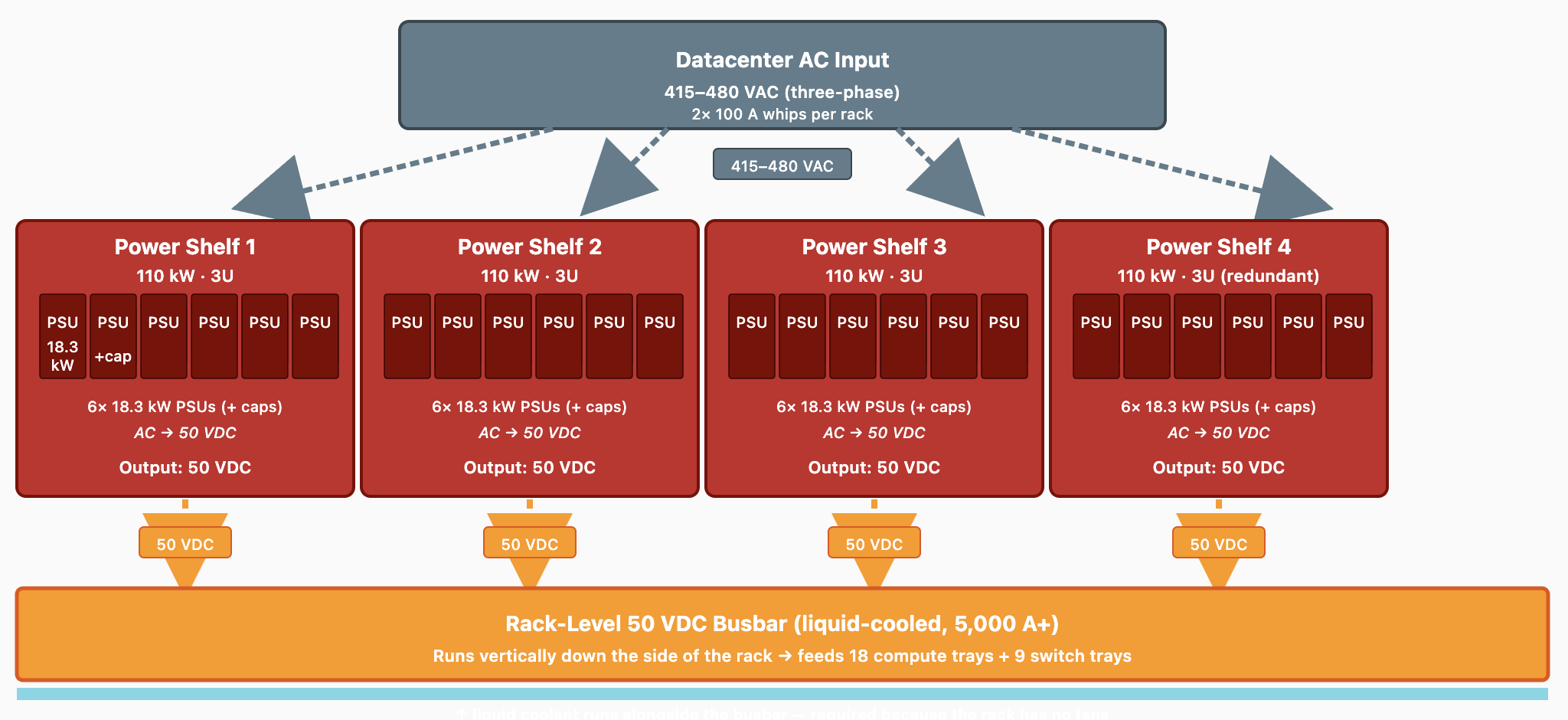
랙 상단과 하단에 3~4개의 power shelf가 자리하며, 각각 110 kW를 담당한다 (N+1 redundancy 구성으로 220 kW 피크 부하에 대해 330 kW까지 공급 가능).
각 shelf는 3U 높이로, 내장 capacitor를 갖춘 18.3 kW PSU를 6개 탑재한다.
Input: 두 가닥의 100A whip을 통한 3상 415~480 VAC.
Output: 5,000 A 이상 정격의 liquid-cooled busbar로 공급되는 50 VDC (GB200은 2,900 A 수준이었다).
왜 liquid-cooled인가? 이 정도 전류 수준에서는 busbar 자체도 꽤 많은 열을 내뿜는데, 랙 안에는 그 열을 식혀 줄 fan이 따로 없기 때문이다.
Step 2: 50 V busbar → compute tray (다이어그램의 노란 점선 경로)
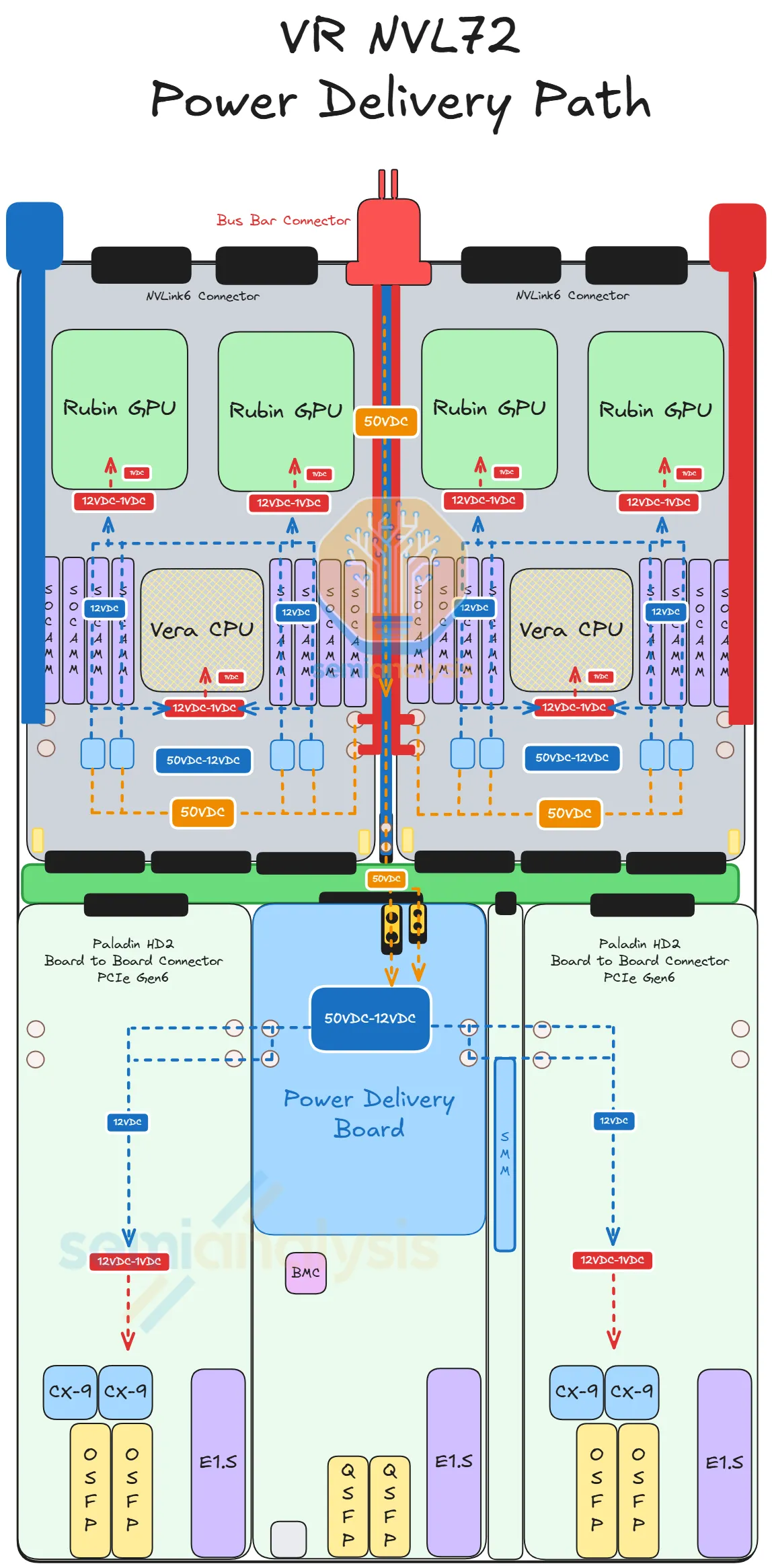
tray는 후면에서 rack busbar에 끼워 맞춰진다.
내부 busbar 케이블이 50 V를 두 갈래로 나눠 보낸다.
Strata Module (50 V를 직접 받는다 — 전류가 너무 커서 중앙 집중식 12 V rail로는 효율이 떨어지므로, Strata가 보드 위에서 직접 강압한다).
전면의 Power Delivery Module (전면의 작은 module들을 위해 50 V → 12 V 변환을 한 곳에서 처리한다).
Step 3: 50 V → 12 V → 1 V (각 보드 위에서)
Strata board는 50 V → 12 V용 자체 IBC (Intermediate Bus Converter)와 12 V → ~1 V용 VRM을 갖추고 GPU/CPU die에 직접 전원을 공급한다.
PDB는 Orchid·BF-4·Mgmt module을 위한 50 V → 12 V 변환을 맡으며, 짧은 내부 busbar를 통해 해당 module들로 12 V를 나눠 보낸다.
왜 tray에 12 V가 아니라 50 V를 보내는가
wire 위의 전력 손실은 전압이 아니라 전류의 제곱에 비례 (I²R) 한다.
50 V에서 4,800 W를 공급한다면 96 A로 충분하지만, 12 V로 공급하려면 400 A가 필요해진다.
즉, 강압을 늦추고 더 높은 전압을 칩 근처까지 끌고 가면, 그 구간의 전력 손실이 17배 줄어든다.
Vera와 Rubin 사이의 "Power Sloshing"
GB300에서 이어 온 기능 — Strata 보드의 4,800 W 전력 예산을 Rubin GPU 2개와 Vera CPU 1개가 동적으로 나눠 쓴다. GPU-heavy 부하에서는 각 Rubin이 2,300 W까지 끌어다 쓸 수 있고 (그러면 Vera에는 200 W가 남는다), GPU가 idle이거나 derate 되면 그 여유분을 Vera가 받아 가져갈 수 있다. 양쪽이 동시에 worst-case로 돌아가는 상황을 대비해 전원을 과하게 잡아 둘 필요가 없다는 뜻이다.
랙 수준의 레퍼런스 설계 (3U 110 kW power shelf 4개 → 50 V liquid-cooled busbar)는 § 8 Step 1에서 다뤘다. 이 섹션은 hyperscaler가 해당 레퍼런스에서 벗어나면서 시도하는 변형들을 살펴본다 — 랙당 TDP가 이미 180~220 kW에 다다랐고, 다음 한두 세대 안에 랙당 1 MW를 향해 올라간다는 흐름이 이를 끌고 가는 동력이다.
이탈 양상은 크게 두 갈래로 나뉜다:
더 높은 전압으로의 분배 — HVDC power rack이 GPU rack 안쪽의 50 V step-down shelf에 공급하는 구조.
에너지 저장의 통합 — peak shaving과 grid bridging을 위해 BBU + CBU shelf를 옆 rack으로 옮긴 구조.
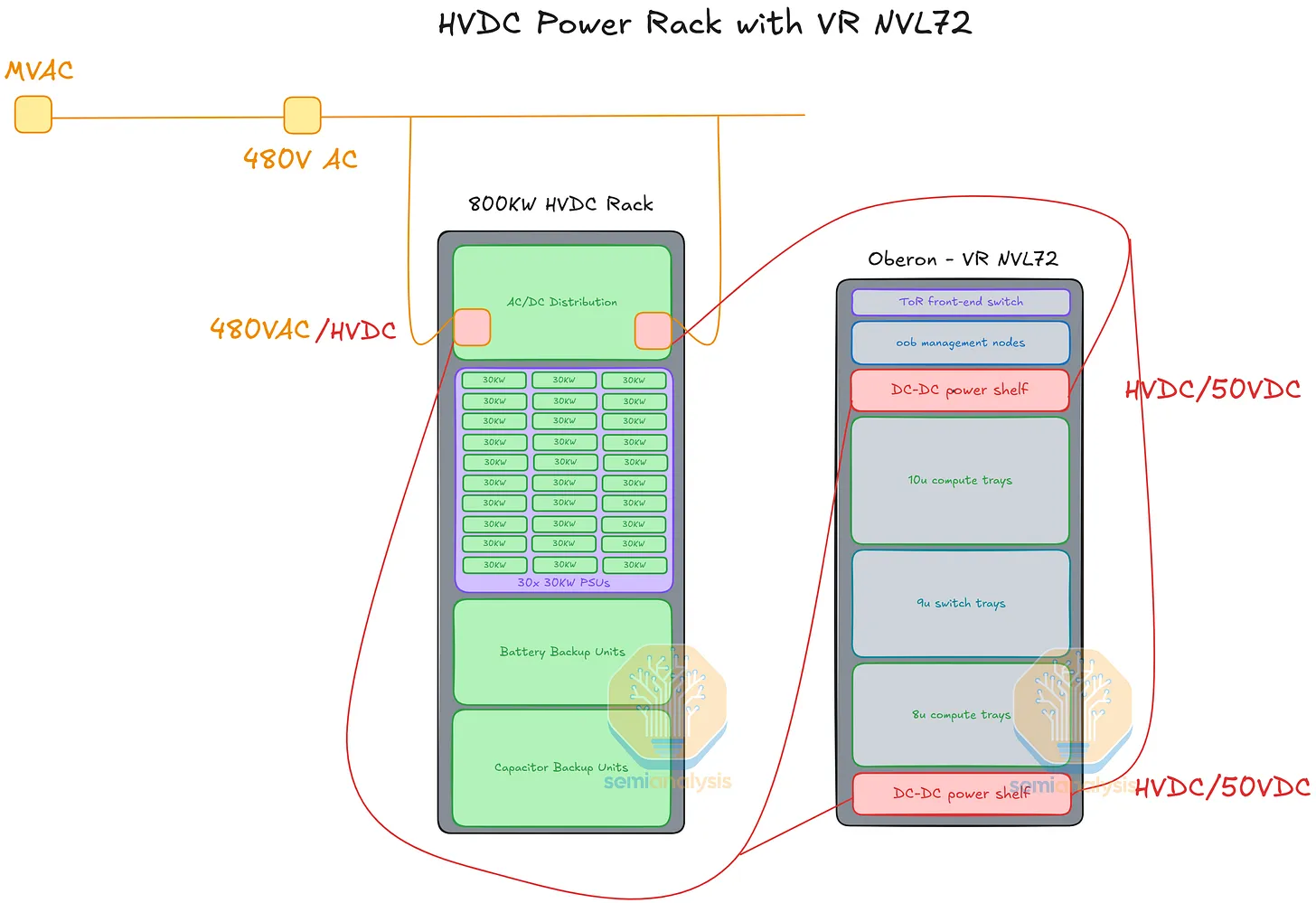
일부 hyperscaler는 별도의 power rack을 훨씬 더 높은 DC 전압에서 운영하고, 이를 수평으로 GPU rack에 공급한다. 통용되는 전압 표준은 두 가지다.
800 VDC — Nvidia 사양.
±400 VDC — OCP (Open Compute Project) 사양.
HVDC 공급의 동작 방식
AC 전원 → power rack에서 800 VDC (또는 ±400 VDC)로 변환한 뒤, 두꺼운 도체를 통해 분배.
수평 800 VDC busbar (또는 케이블)가 인접한 GPU rack들과 power rack을 연결.
GPU rack 내부에서는 DC-DC step-down shelf가 800 VDC → 50 VDC로 변환해 표준 rack busbar에 공급.
그 이후의 공급 경로는 AC 레퍼런스 설계 (§ 8)와 동일하다.
HVDC가 의미 있는 이유
power rack과 compute rack 사이의 긴 수평 구간에서 I²R 손실이 낮다 (tray 안에서 12 V 대신 50 V를 정당화했던 I²R 논리를 더 큰 스케일에 그대로 가져온 셈이다).
Standalone power rack은 전력 인프라를 compute rack에서 떼어낸다 — 업그레이드와 교체가 수월하고, 여러 compute rack이 함께 쓰기에도 적합하다.
AC → HVDC 변환 단계에서 Solid-State Transformer (SST) 를 끼워 넣을 수 있게 된다 — 랙 단위 전력 관리의 알갱이가 한층 더 잘게 쪼개진다. 다만 이를 받쳐 줄 공급망은 아직 자리 잡는 중이다.

OCP 2025에 공개된 Meta의 변형은 추가 전력 인프라를 compute rack 자체가 아니라 옆에 둔 rack에 합쳐 넣는다. 그 보조 rack에는 다음이 담긴다:
BBU (Battery Backup Unit) — grid 흔들림이나 짧은 정전 상황을 버티기 위한 단기 배터리 백업.
CBU (Capacitor Backup Unit) — peak shaving을 맡는 sub-second 단위의 capacitor bank (AI 워크로드의 transient 전력 스파이크를 grid에 부담을 주지 않고 받아낸다).
Network switching — serviceability와 밀도를 위해 같은 보조 rack에 co-located.
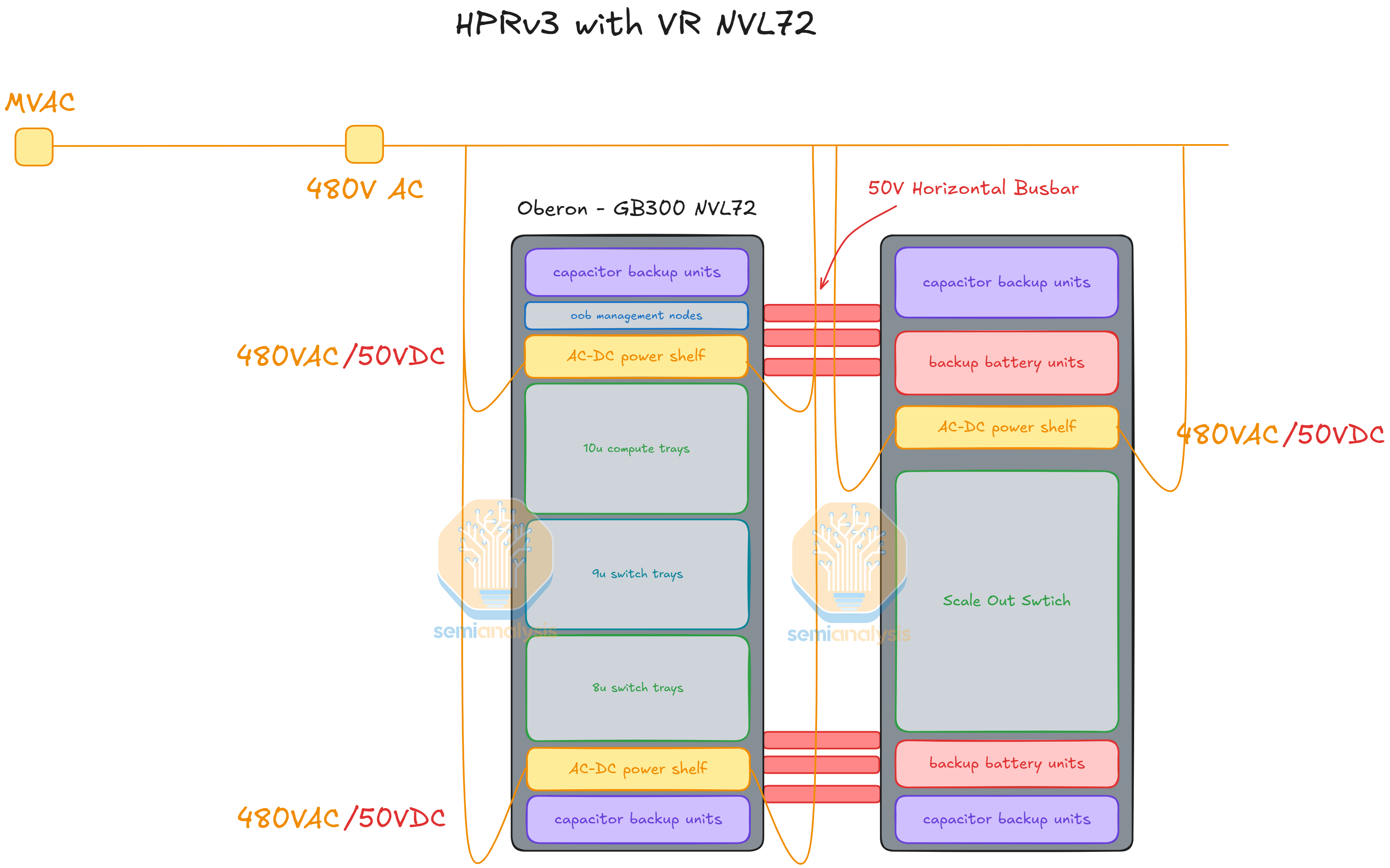
왜 별도의 rack인가? BBU와 CBU shelf는 부피가 너무 커서 GPU rack에 함께 담기 어렵다. 옆 rack으로 옮겨 두면, GPU rack 혼자서는 감당할 수 없는 규모의 에너지 저장 용량을 Meta가 마련할 수 있다. GPU rack과 high-power rack은 수평 50 V busbar를 통해 이어진다.
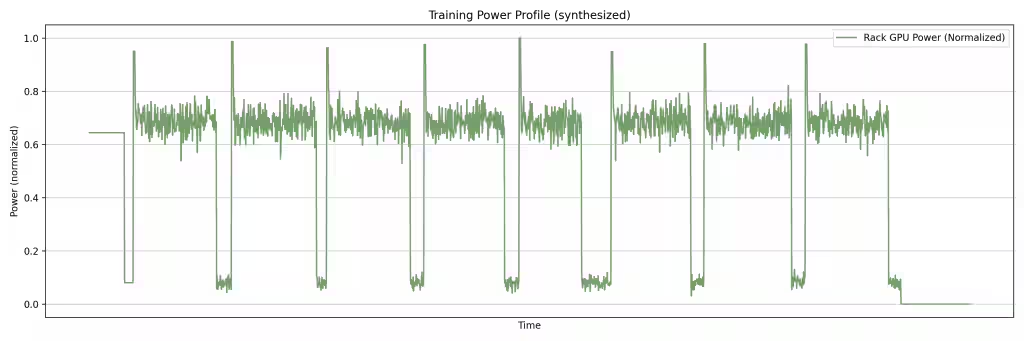
AI training은 많은 GPU가 같은 연산 단계를 동시에 반복하기 때문에, 전력 수요가 완만하게 증가하는 것이 아니라 짧은 순간에 동시다발적으로 급증하는 특성을 가진다 — forward-pass / backward-pass 단계에서 클러스터 안의 모든 GPU가 한꺼번에 ramping 되기 때문이다.
랙 합산 kW 수준에서, 이런 transient는 utility grid에 부담을 주고 보호 회로를 작동시킬 수 있다.
CBU peak-shaving은 sub-second 단위의 스파이크를 로컬 랙 단위에서 완화시키고, BBU bridging은 더 긴 이벤트 동안 워크로드를 떨어뜨리지 않은 채로 버텨 낸다.
두 장치가 함께 맞물려 돌아가면서, AI 워크로드가 grid 안정성 문제로 번지는 일을 막아 준다.
랙 단위 전력 생태계 — AC/DC 변환, 50 V vs 800 VDC 분배, BBU/CBU 통합, liquid-cooled busbar, SST 로드맵, 그리고 벤더별 상업 조건·타임라인 (Lite-On, Delta, Flex, Vertiv, Eaton, Advanced Energy, Hitachi Energy, GE Vernova, TE Connectivity, Amphenol) — 은 Part 6 § 4 (Rack-Level Power Delivery)에 통합 정리되어 있다.
대부분의 비-hyperscaler 구매자에게는 표준 110 kW power-shelf 4개로 구성된 레퍼런스 설계가 그대로 출하된다. HVDC와 BBU/CBU rack 아키텍처는 사실상 hyperscaler 커스터마이즈 영역에 해당한다.
이 섹션은 bottom-up으로 풀어 간다 — 먼저 compute tray 한 대 안의 모든 internal lane을 짚어 본 뒤, 그 tray들이 랙 중앙의 NVLink switch tray와 어떻게 이어져 하나의 72-GPU 가속기로 묶이는지를 살펴본다.
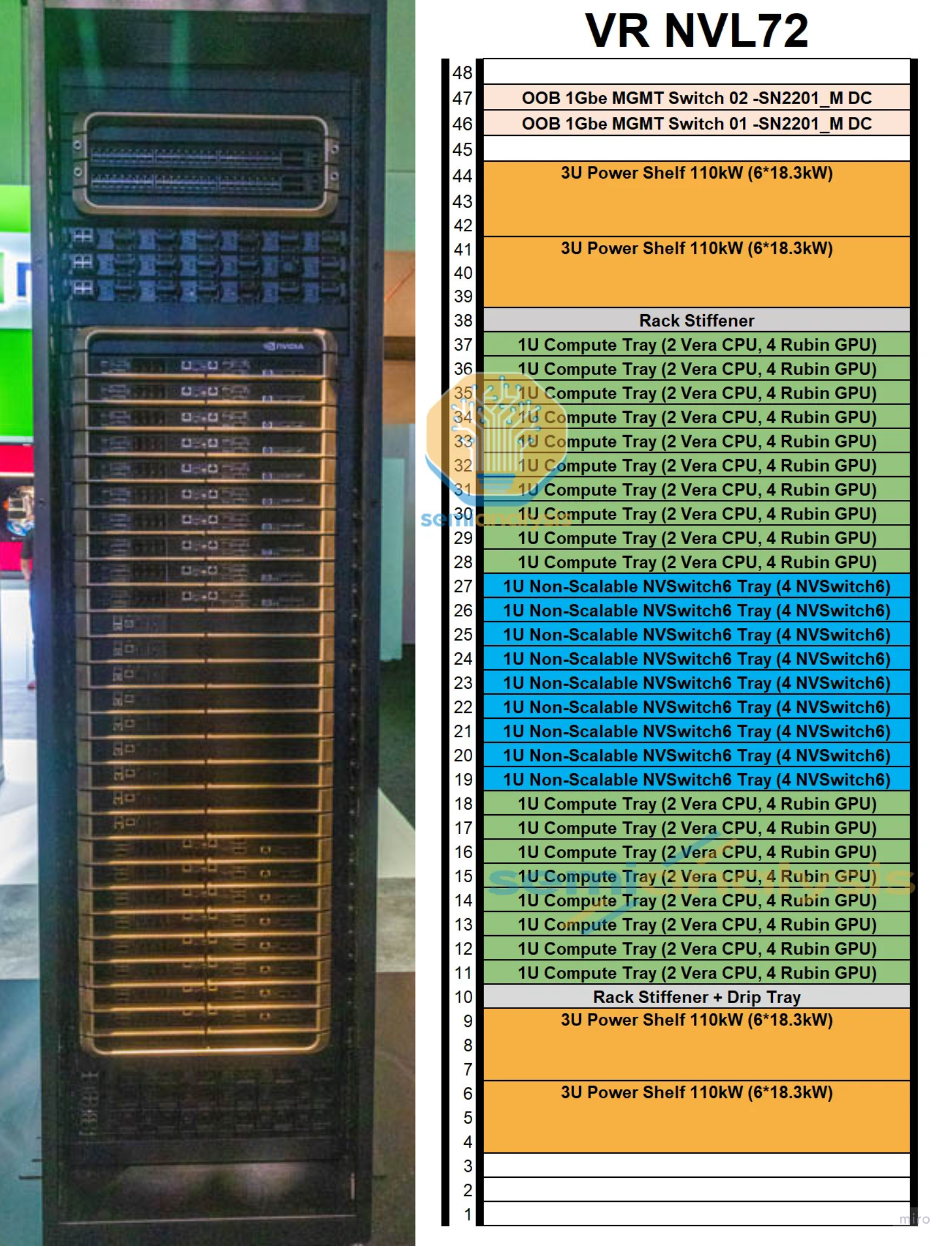
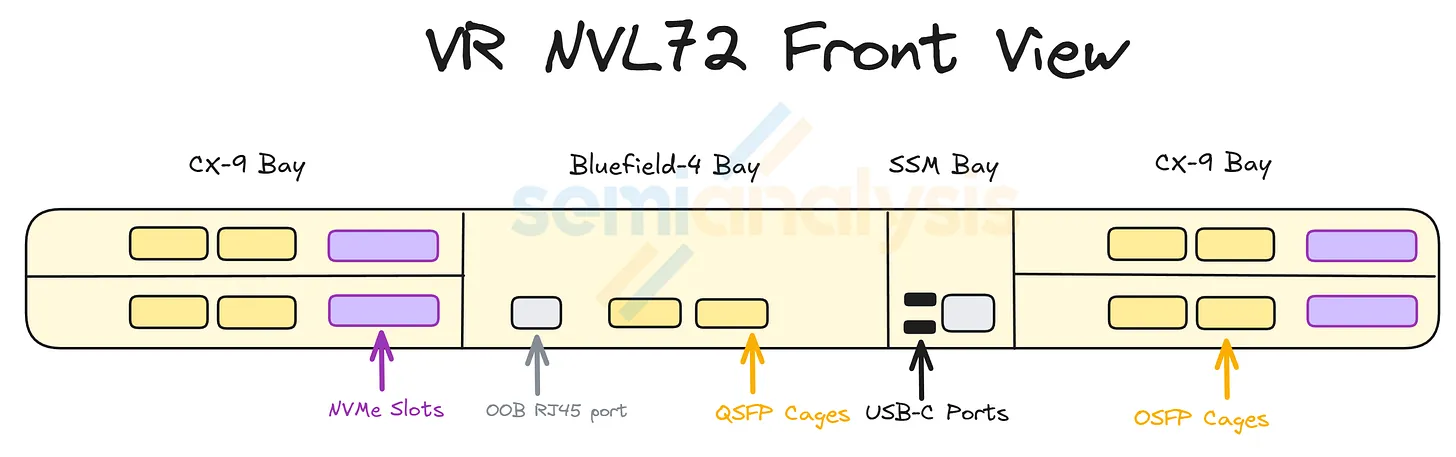
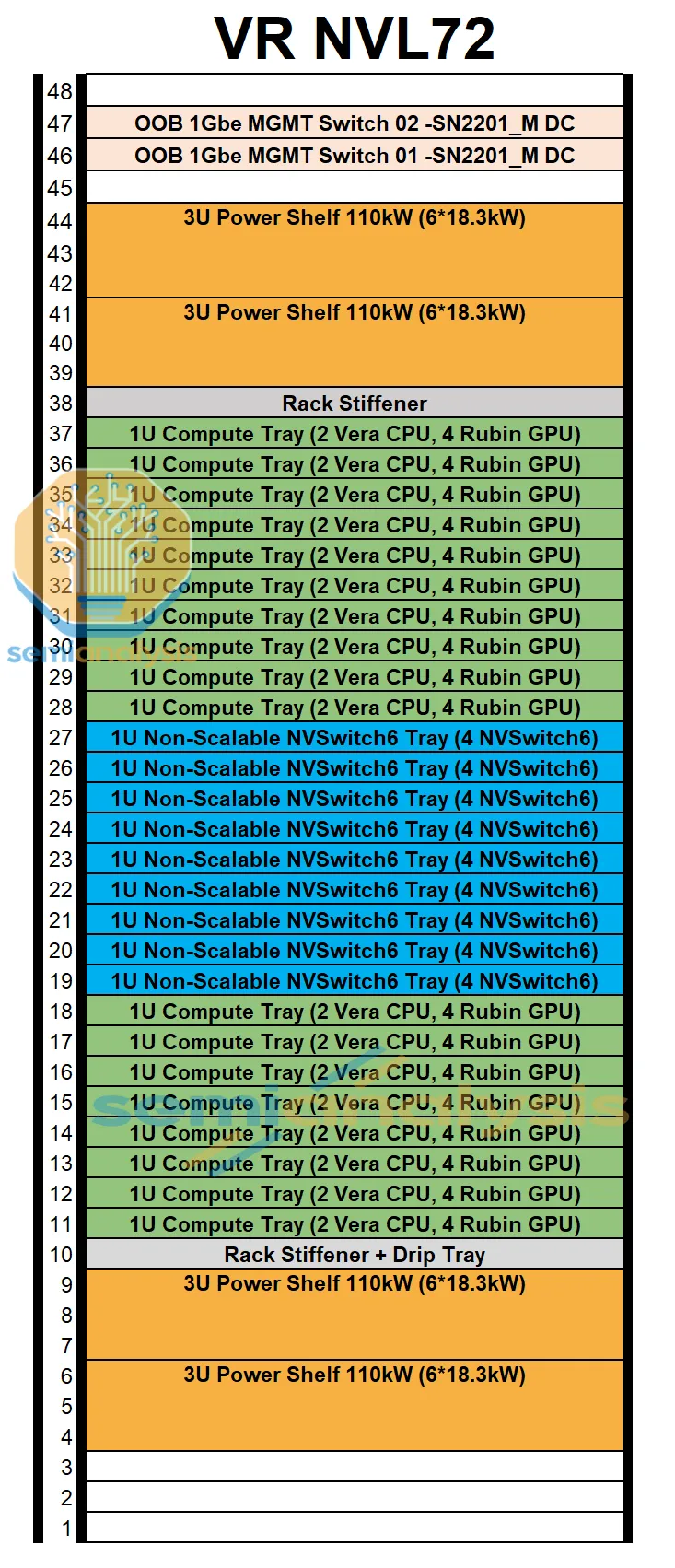
랙은 18 compute tray + 9 NVLink switch tray + 4 power shelf를 19인치 캐비닛 한 대 안에 쌓아 올린다.
각 compute tray는 랙 후면의 NVLink backplane에 슬롯에 삽입된다.
NVLink backplane은 compute-tray midplane과는 별개의 물리 계층이다 — passive copper backplane으로, 각 Strata module에서 NVLink Switch Tray로 NVLink 6 신호를 나른다.
9개의 switch tray (각각 칩 4개 = 합쳐서 36개의 NVLink 6 switch 칩)가 랙 중앙에 자리잡아, 모든 GPU가 다른 모든 GPU와 full all-to-all 토폴로지로 이어지도록 한다.
50 V liquid-cooled busbar가 랙 한쪽 면을 따라 수직으로 지나가며 모든 tray에 전원을 공급한다.
4개의 power shelf — 랙 상단 (U41~44)에 2개, 랙 하단 (U4~9)에 2개 — 가 위·아래 양쪽에서 그 busbar에 전원을 공급한다.
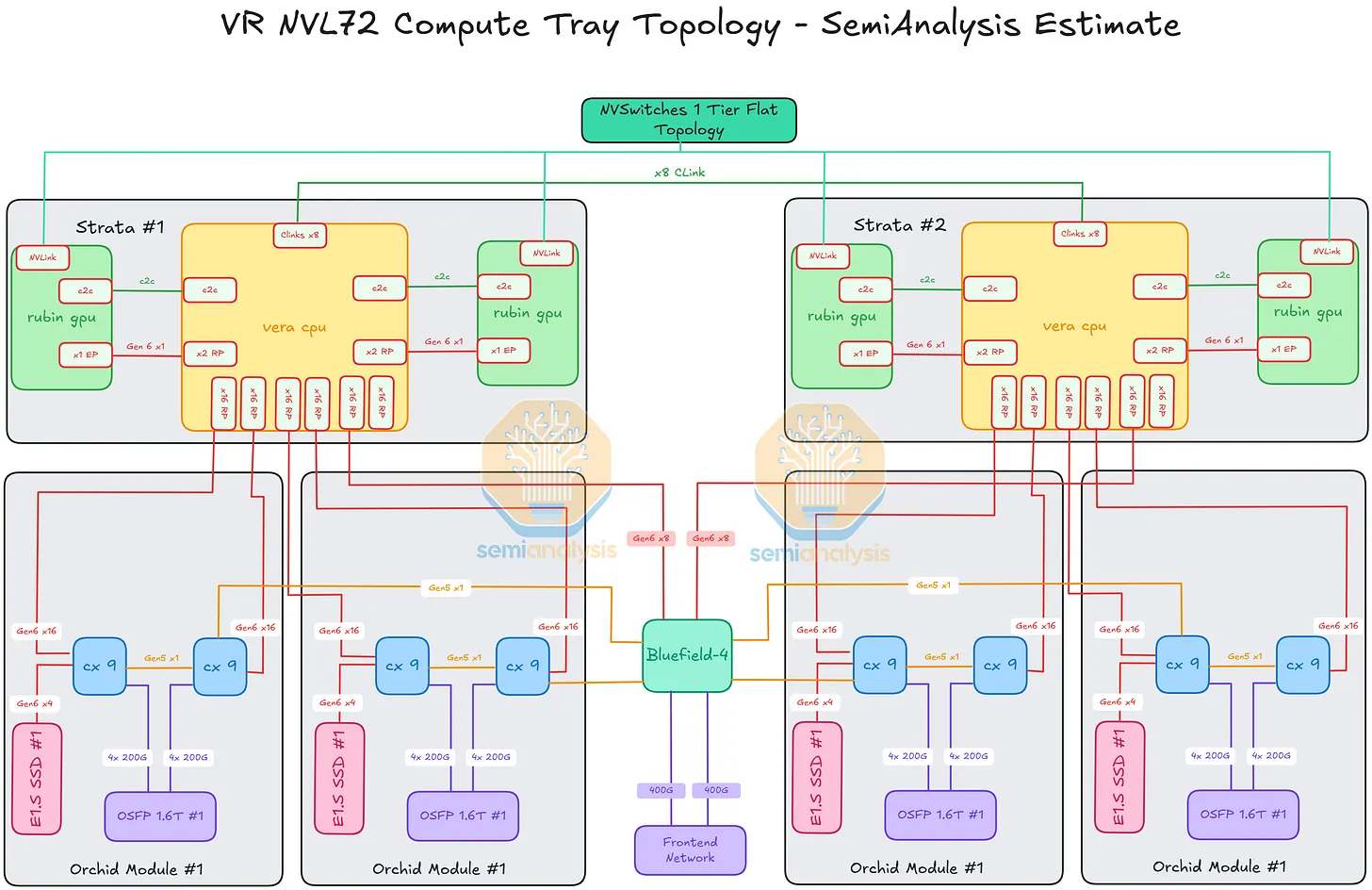
한 compute tray 내부의 네트워크 lane 배선. Strata module부터 바깥 방향으로 읽는다.
단일 Strata Module 내부 — Rubin GPU ↔ Vera CPU ↔ Rubin GPU
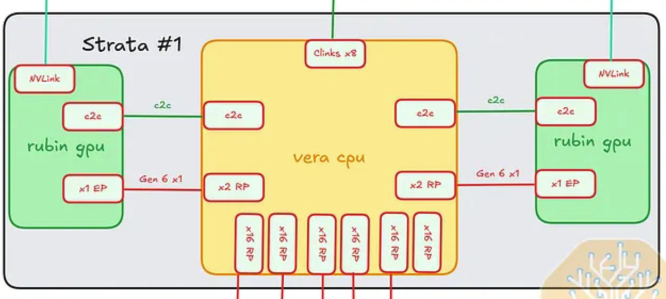
각 Strata module은 Vera CPU 1개 + Rubin GPU 2개를 담는다. 각 Rubin은 두 개의 병렬 경로로 Vera와 이어진다.
NVLink-C2C (coherent path): GPU↔CPU 쌍당 NVLink 6 C2C lane 1개 — 1.8 TB/s 속도로 coherent 메모리 트래픽을 전송한다.
PCIe path: GPU↔CPU 쌍당 PCIe Gen6 lane 1개 — 관리 / secondary I/O 용도.
Strata module당 GPU↔CPU 2쌍이 있다 (각 Rubin GPU에 하나씩).
두 Strata Module 사이 — Vera CPU ↔ Vera CPU
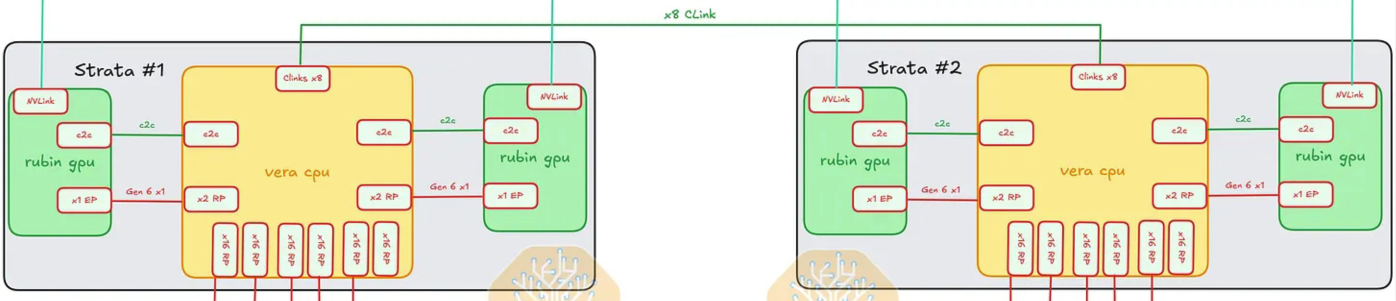
두 Vera CPU (Strata당 하나)는 tray가 하나의 coherent compute가 가능하도록 연결되어 있다.
Vera ↔ Vera: NV-CLink lane 8개.
Rubin GPU ↔ NVLink Switch Tray (rack-scale 경로)
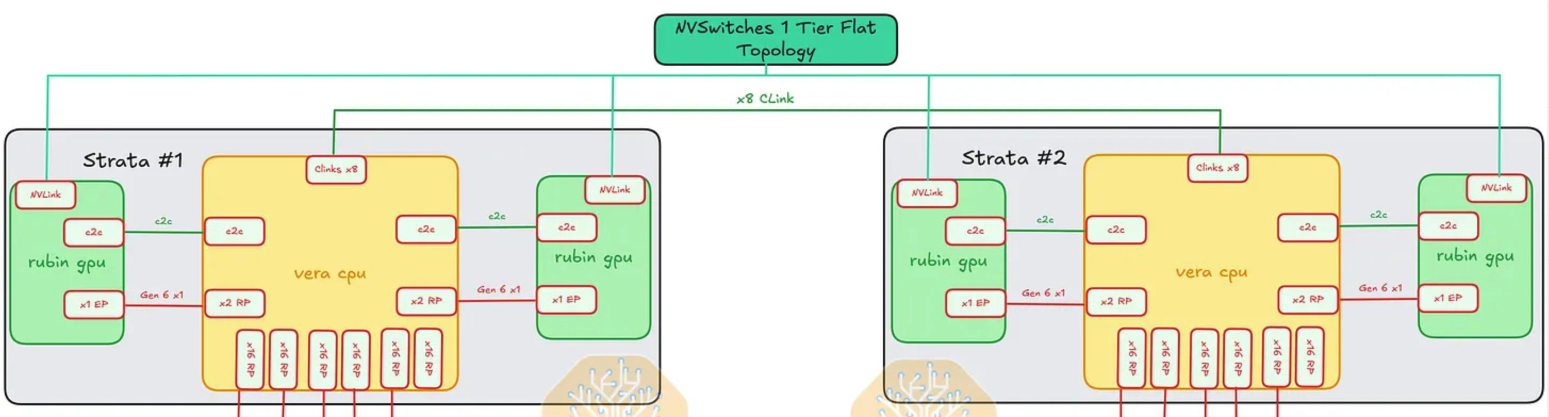
각 Rubin GPU는 tray 밖, rack 단위 NVLink fabric에 직접 이어진다.
Rubin GPU ↔ NVSwitch: 랙 후면의 NVLink backplane을 따라가는 NVLink 6 GPU-to-GPU lane.
이것이 all-to-all rack-scale 경로다 — 전체 토폴로지는 § 11에서 다룬다.
Vera CPU ↔ Orchid Module (scale-out 네트워킹 + 로컬 스토리지)
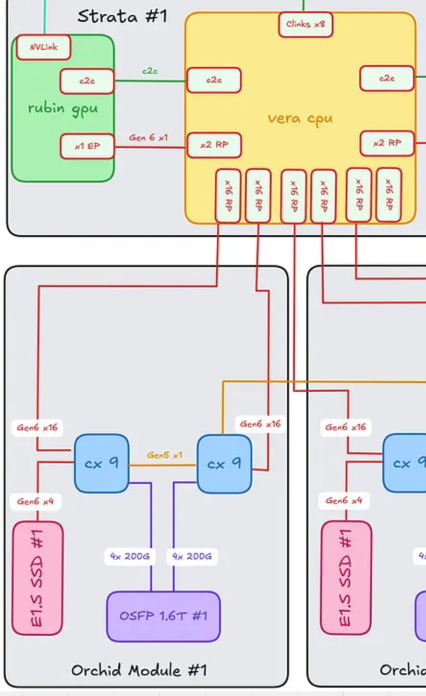
각 tray에 4개의 Orchid module이 있고, 각각 2개씩의 ConnectX-9 (CX-9) NIC를 담는다.
Orchid module당:
Vera ↔ CX-9: CX-9당 16개의 PCIe Gen6 lane (module 위 두 CX-9 합쳐 32개).
CX-9 ↔ CX-9 (peer link): 동일 Orchid 위 두 CX-9 사이의 1개의 PCIe Gen5 lane.
왼쪽 CX-9 ↔ E1.S NVMe SSD 슬롯: 4개의 PCIe Gen6 lane.
CX-9 ↔ 1.6T OSFP cage (scale-out 네트워크): CX-9당 4개의 200G Ethernet/InfiniBand lane (Orchid당 총 8개).
단일 Orchid module의 lane 합계.
36개의 PCIe Gen6 lane (CX-9 두 개에 32개 + E1.S SSD에 4개)
1개의 PCIe Gen5 lane (CX-9 peer link)
8개의 200G Ethernet / InfiniBand lane (전면 패널 scale-out)
Vera CPU ↔ BlueField-4 Module (frontend 인프라 plane)
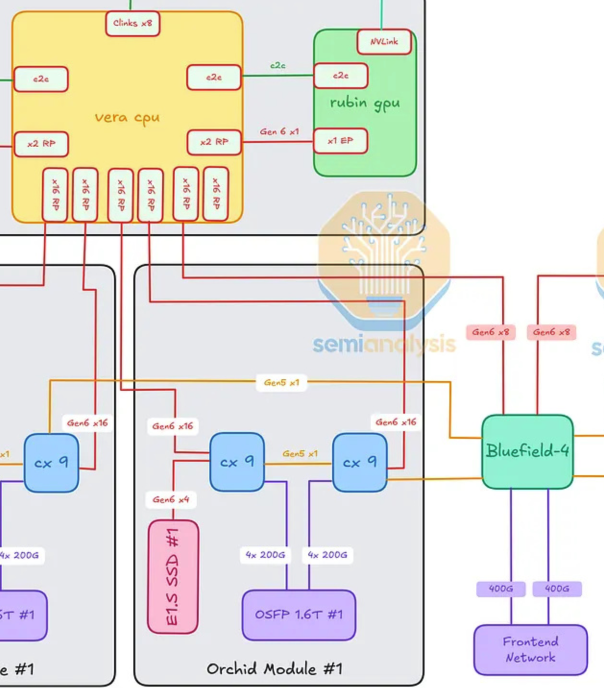
BF-4 module은 Vera CPU에서 출발하는 세 번째 주요 목적지다. BF-4를 드나드는 연결.
Vera ↔ BF-4: Vera당 8개의 PCIe Gen6 lane (총 16개 — Strata당 Vera 1개 × Strata 2개).
CX-9 (각 Orchid의 우측) ↔ BF-4: CX-9당 1개의 PCIe Gen5 lane (tray의 4개 Orchid 합쳐 총 4개).
BF-4 ↔ Frontend Network 포트: 2개의 400G Ethernet/InfiniBand lane.
BF-4 module의 lane 합계.
16개의 PCIe Gen6 lane (두 Vera로부터)
4개의 PCIe Gen5 lane (4개의 Orchid의 우측 CX-9로부터)
2개의 400G Ethernet / InfiniBand lane (frontend 네트워크)
단일 VR NVL72 Compute Tray — Module과 Lane 요약
Tray당 module:
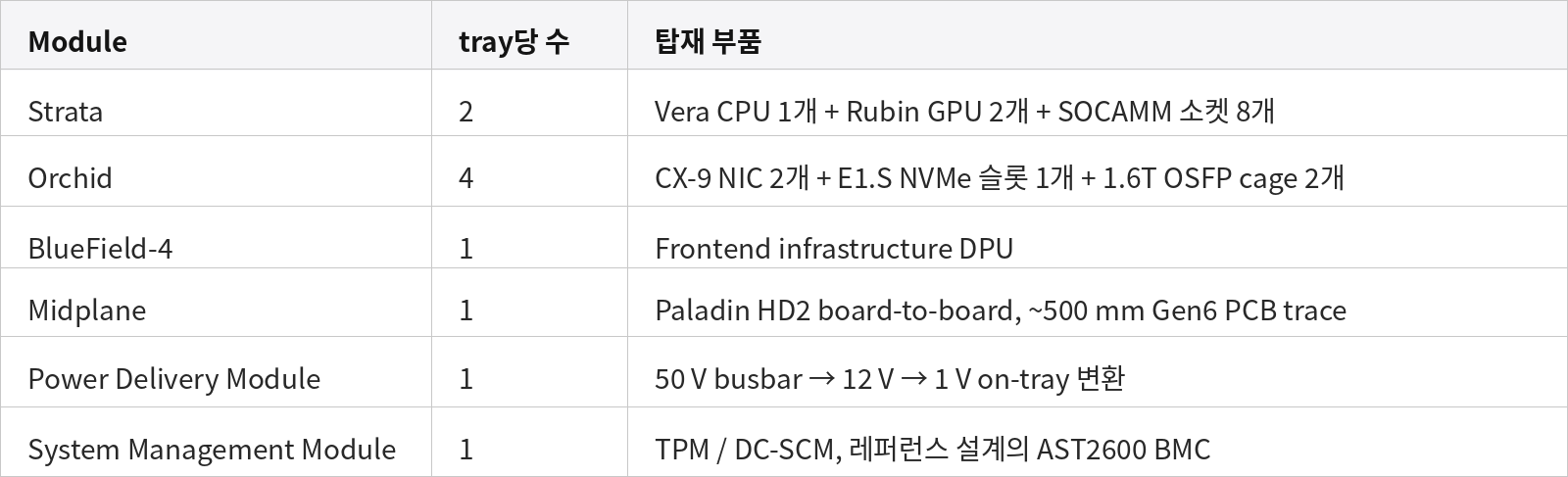
Tray당 lane 수 (모든 module 합산).
Tray당 전면 패널 외부 연결: 1.6T OSFP cage 8개 (scale-out) + frontend 포트 1개 (BF-4 400G lane 2개) + BMC/management 1개.
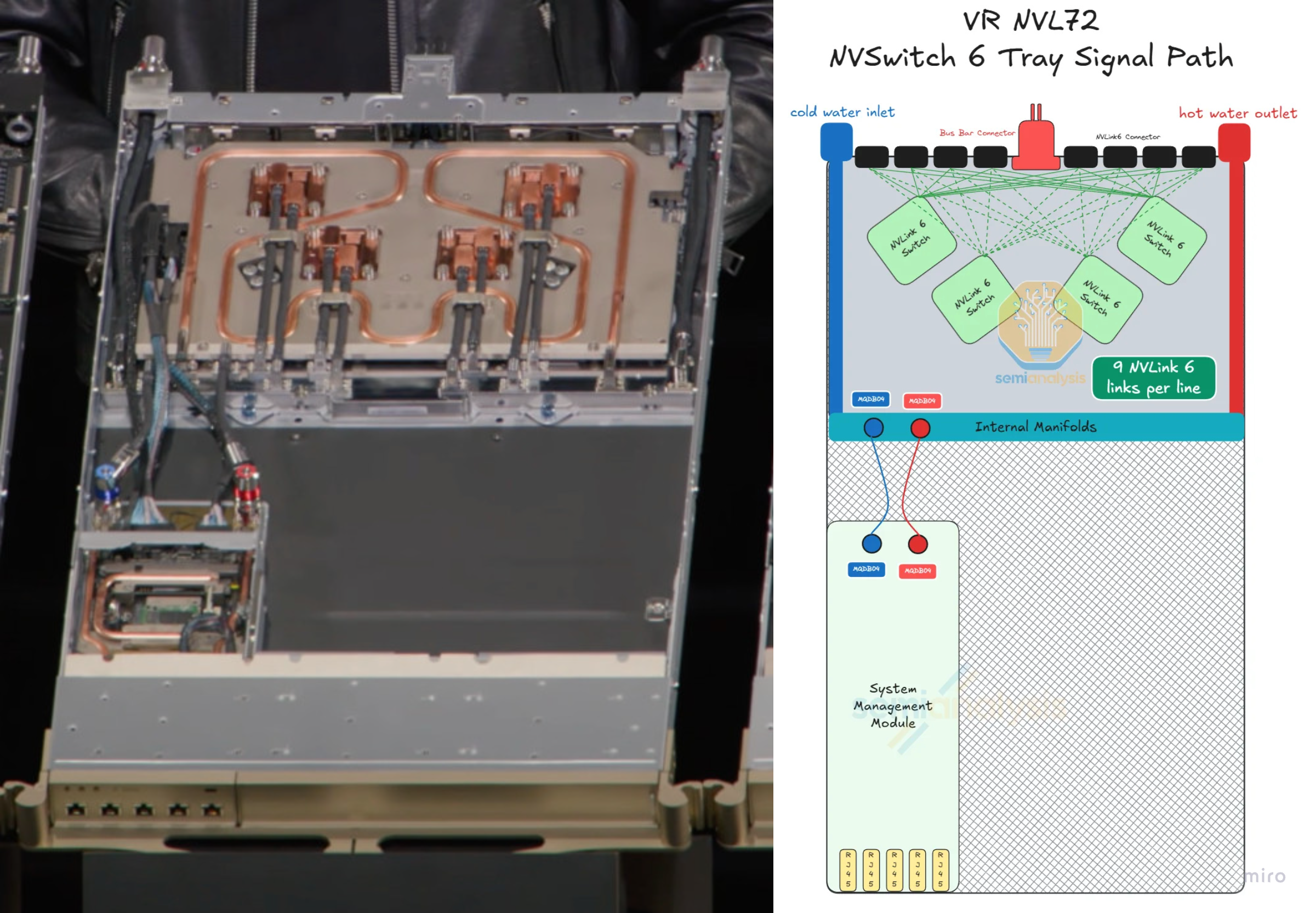
Compute tray는 NVLink 6 copper backplane을 거쳐 랙 중앙의 NVLink switch tray에 이어진다. 각 switch tray는 PCB 한 장 위에 NVLink 6 Switch 칩 4개를 올려 둔다.
Switch Tray 내부
NVLink 6 Switch 보드는 liquid-cooled 방식으로, 단일 cold-plate module이 보드 전체를 덮는다.
tray는 자체 CPU를 가진 System Management Module (SMM) 을 함께 호스팅하며, SMM이 switch tray의 host 역할을 맡는다.
SMM과 switch tray 사이의 연결은 flyover 케이블을 사용한다 — VR NVL72 시스템 전체를 통틀어 유일한 flyover 케이블 연결이다. 이 예외가 허용되는 이유는 (a) SMM으로 가는 PCIe link가 저속이고, (b) switch tray가 담는 module 수가 비교적 적어, 다른 부분을 cableless로 몰아붙이게 만들었던 조립 실패 패턴이 여기서는 재현되지 않기 때문이다.
Backplane Lane 구조
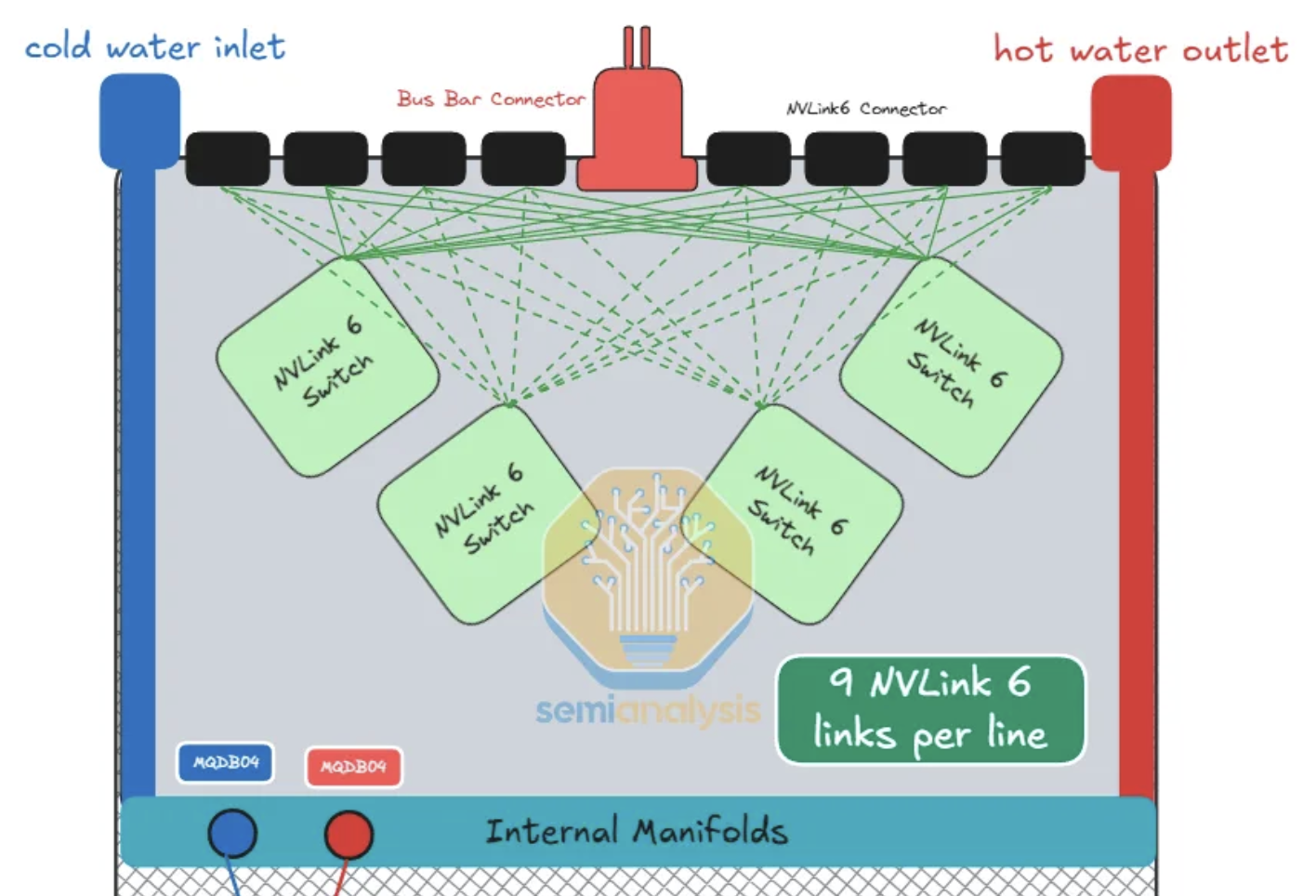
다이어그램의 각 초록색 선은 400G NVLink 6 포트 9개, 즉 200G 기준 TX/RX lane 18개를 뜻한다.
NVLink 6는 bidirectional SerDes를 채택하므로, lane당 1 differential pair (DP) — 어떤 connector와 어떤 switch 사이라도 18 DP, connector 전체로는 72 DP가 된다.
connector당 케이블 수는 이전 세대인 NVLink 5 Switch Tray와 같다 — 대역폭 2배 증가는 구리가 늘어서 나온 게 아니라, 전적으로 bidirectional signaling에서 비롯된다.
Switch Tray PCB 업그레이드
NVLink 6의 bidirectional signaling은 NVLink 5보다 insertion loss에 대한 허용 한도가 훨씬 좁다.
Amphenol PaladinHD2 커넥터와 NVLink Switch 칩 사이의 ...




