Vera Rubin Decoded Pt. 3 | Vera CPU와 네트워킹 실리콘 제품군

s4ndwalker
2026.05.26조회수 88회
s4ndwalker
구독자 67명구독중 13명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.

시리즈 안내 ⎯ Series Map
Part 1: 플랫폼 개요와 아키텍처 맵 — Blackwell → Rubin 플랫폼의 핵심과 주요 사양
Part 2: Rubin GPU 엔지니어링 심층 분석 — process node, SM, HBM4, NVLink-C2C, 패키지, CPX와 Groq 3 LPX
Part 3 (현재 글): Vera CPU와 네트워킹 실리콘 제품군 — Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6
Part 4: 랙 조립 — 트레이, PCB, 쿨링 — HGX와 NVL72, 컴퓨트 트레이 모듈, cableless 미드플레인, PCB 업그레이드, 액체 냉각
Part 5: 랙 전력과 네트워킹 fabric — 전력 공급, HVDC, tray ↔ rack 배선, scale-up NVLink 6, scale-out InfiniBand와 Ethernet
Part 6: 공급망 마스터 레퍼런스 — sub-system별 공급사 정리

Vera는 Nvidia의 2세대 자체 ARM 기반 CPU로, Blackwell 플랫폼의 Grace를 잇는다. 설계 의도가 바뀌었다.
Grace는 GPU 옆에 자리잡은 host CPU였다.
Vera는 data engine으로 자리매김한다 — 데이터를 옮기고, 워크로드를 오케스트레이션하며, GPU의 처리량에 맞는 속도로 control flow를 처리하여 *Rubin GPU에 데이터가 효율적으로 전달되도록 조율하는 것이 역할이다.
Rubin급 GPU 속도에서는 표준 서버 CPU가 병목이 된다. Vera는 그 병목을 제거하기 위해 특별히 설계됐다.
Grace → Vera 한눈에 보기
변화는 네 개의 엔지니어링 레이어로 묶인다 — 무엇이 실행되는지, 무엇이 그것을 저장·공급하는지, 무엇이 그것을 칩 안팎으로 옮기는지, 이 모든 과정이 어떤 실리콘 위에서 작동하는지. 아래 표들은 각각 원시 사양의 변화 (delta)와 엔지니어링 결과를 짝지어 보여 준다 — Vera 섹션의 나머지를 읽을 때 표준 레퍼런스다.
[연산 — Cores · Threads · SIMD]

[캐시 & 메모리 서브시스템]
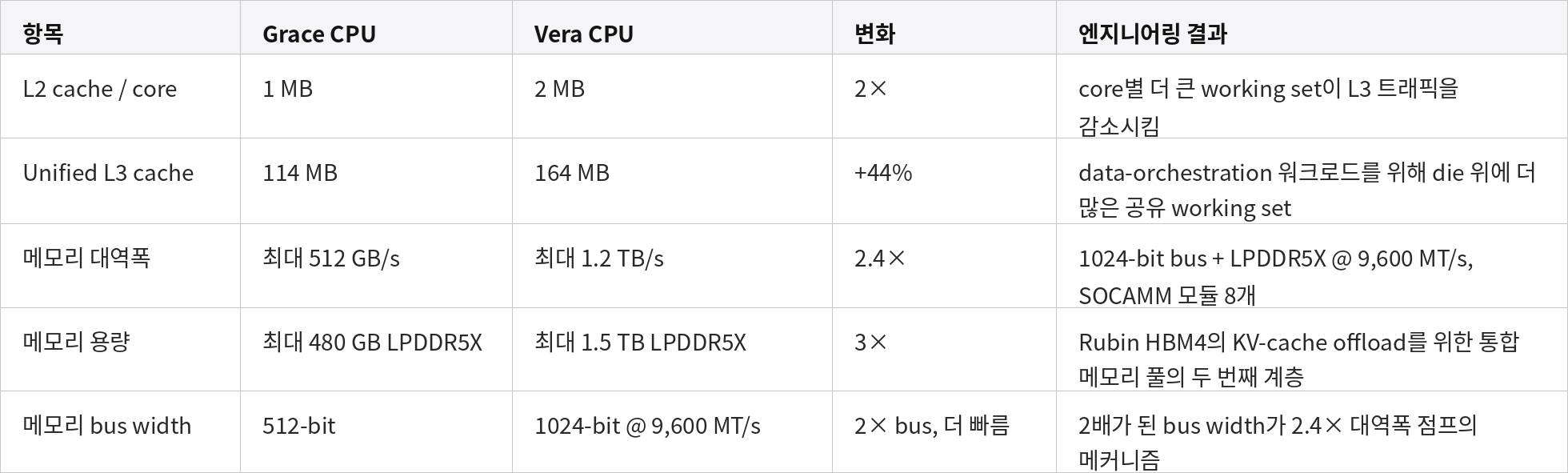
[인터커넥트 & 표준]

[실리콘]

Vera는 Grace에서 사용된 ARM의 기성 Neoverse V2 코어에서 벗어나, Nvidia의 custom ARM 호환 Olympus 코어로 옮겨간다 — Nvidia 자체 CPU 코어 설계의 귀환이다.
Olympus는 wide·deep microarchitecture로, branch prediction, prefetching, load-store 성능이 향상됐다.
일반 enterprise compute가 아닌, control-heavy하고 data movement가 많은 워크로드 (현대 GPU에 데이터를 공급하는 실제 병목 프로파일)에 맞춰 최적화됐다.
ARM v9.2 완전 호환 — 기존 ARM Linux 배포판, 프레임워크, 오케스트레이션 소프트웨어가 수정 없이 실행된다.
Spatial Multithreading이란 (그리고 SMT와 어떻게 다른가)
전통적인 Simultaneous Multi-Threading (SMT — Intel에서는 "Hyper-Threading", AMD Zen 코어에서 사용)은 코어의 실행 자원을 time-slicing해 두 스레드가 단일 코어를 공유하도록 한다. 처리량은 늘지만 스레드별 지연이 예측 불가능해지고 보안상 side-channel 공격 가능성이 생긴다.
Vera의 Spatial Multithreading은 자원을 time-slicing하는 대신 물리적으로 분할하여 코어당 두 스레드를 실행한다.
결과: 88코어에 걸친 176 하드웨어 스레드. 스레드별 지연이 예측 가능하고, 스레드 간 격리가 강화된다.
한 테넌트의 워크로드가 다른 테넌트의 응답 시간에 영향을 주지 않아야 하는 multi-tenant AI factory에서는 결정적인 특성이다.
다이 레벨 yield 트릭
Nvidia는 실제로 die에 91개 코어를 인쇄하지만 88개만 활성화된 채로 출하한다.
3개의 redundant 코어는 순전히 제조 yield를 개선하기 위한 것이다 — 91개 중 어느 하나에 결함이 있어도 비활성화 처리하고 full 88-core 부품으로 출하한다.
GPU 쪽의 floor-sweeping (제조 결함이 있는 일부 블록을 비활성화해 수율을 높이고, 이를 하위 모델로 판매하는 방식)과 동일한 발상이다.
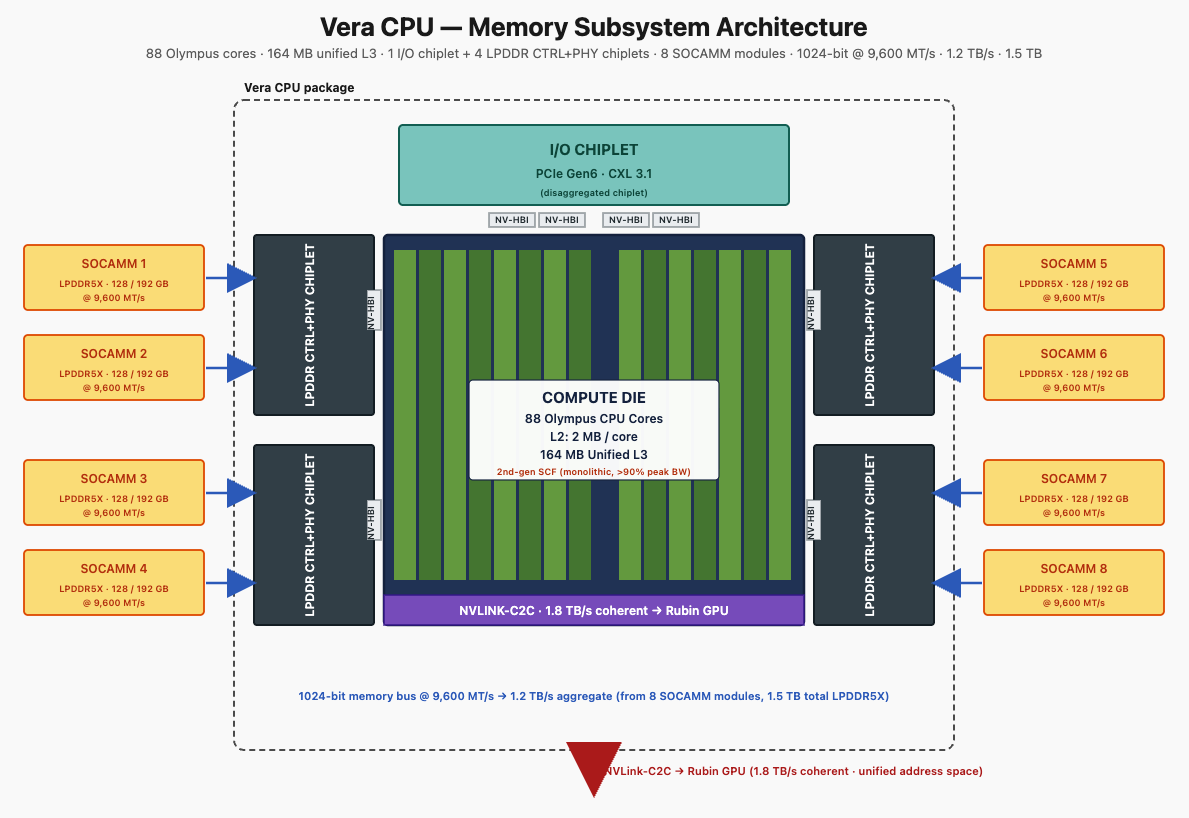
Vera의 메모리 서브시스템은 Grace 대비 용량 3배·대역폭 2.4배로 재설계됐다.
LPDDR5X (Low-Power DDR5X)는 최신 스마트폰·노트북에서 쓰이는 메모리 타입으로, 표준 서버 DDR5 대비 GB/s당 전력 효율이 훨씬 좋다. 대신 CPU에 가깝게 납땜되거나 모듈로 부착된다.
Vera는 SOCAMM 모듈을 사용한다 — Small Outline Compression Attached Memory Module의 약자로, Nvidia가 데이터센터의 신뢰성·교체성 요구에 맞춰 설계한 LPDDR5X form factor다.
Vera 소켓당 8개 SOCAMM 모듈, 총 1.5 TB @ 9,600 MT/s.
1024-bit 메모리 버스 (Grace의 512-bit의 두 배)가, 클럭을 합리적인 수준으로 유지하면서도 총 대역폭을 1.2 TB/s에 도달하게 만드는 메커니즘이다.
메모리 대역폭이 이렇게까지 중요한 이유
Rubin GPU 쪽 HBM 대역폭이 22 TB/s에 이르는 상황에서, 기존 CPU 쪽은 상대적으로 얇아 보였다.
Vera의 1.2 TB/s LPDDR5X는 NVLink-C2C를 통해 애플리케이션에 노출되는 통합 메모리 풀의 두 번째 계층이다 (Part 2의 Rubin 섹션 (4) 참고).
Rubin의 288 GB HBM4 용량을 초과한 KV cache는 어딘가 빠른 곳에 도달해야 한다 — Vera의 LPDDR5X가 바로 그 착륙 지점이다. Vera의 메모리 대역폭이 낮았다면 offload 경로가 GPU 연산을 멈추게 만들 것이다.
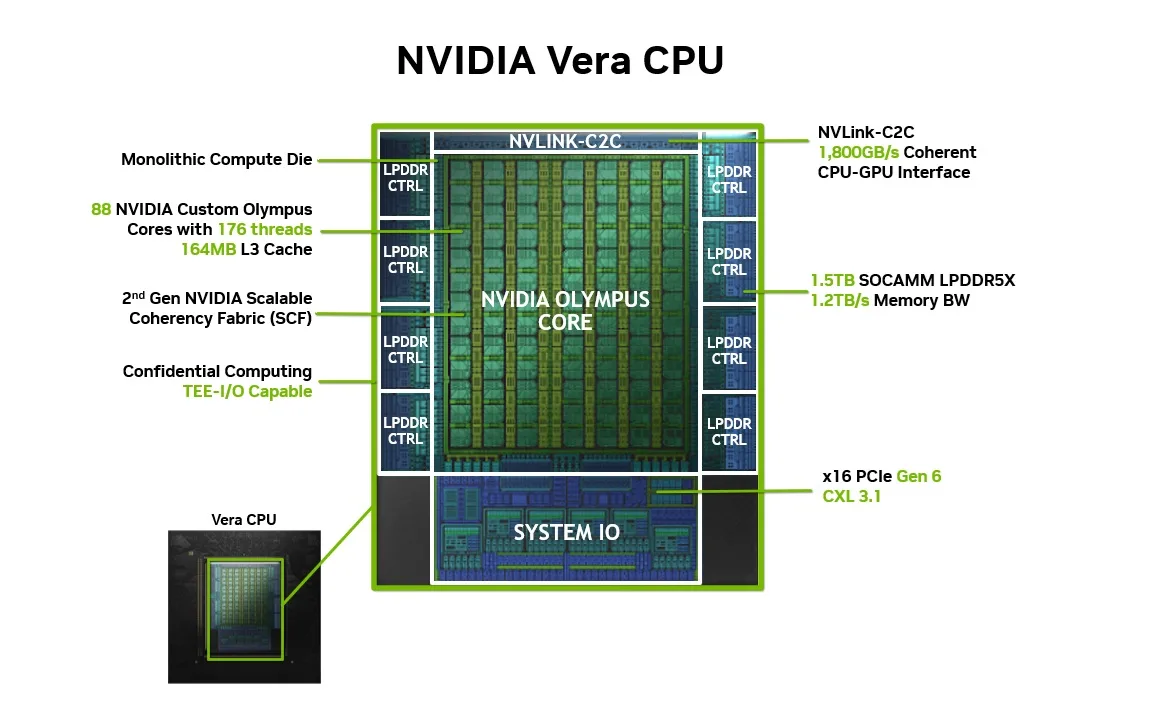
2세대 Scalable Coherency Fabric은 88개 Olympus 코어 모두를 공유 L3 cache와 memory controller로 연결하는 on-chip 네트워크다.
단일 monolithic compute die 위에 구축됐다 — Nvidia가 compute 측에서는 chiplet 경계를 의도적으로 피했다.
이유: chiplet 경계는 지연과 대역폭 편차를 더한다. line rate에서 결정론적 데이터 이동이 본업인 CPU에게 이 편차는 받아들일 수 없다.
결과: SCF는 부하 상황에서도 피크 메모리 대역폭의 90% 이상을 유지한다. 즉, 소프트웨어가 헤드라인 수치인 1.2 TB/s에 근접한 값을 실제로 보게 된다는 뜻이다.
Vera는 memory controller와 I/O는 chiplet으로 disaggregate하지만 (Rubin과 유사), compute die는 monolithic으로 유지한다는 점에 주목할 만하다. 이 분할은 엔지니어링 우선순위를 반영한다 — 독립적인 yield 관리가 도움 되는 부분은 chiplet 단위로 세분화하고, 결정론적 지연 (compute die 내부 연산·데이터 이동의 latency가 매번 일정하게 예측 가능해야 한다. 그래서 compute block은 chiplet보다 monolithic 구조가 유리하다.)이 필요한 부분은 monolithic으로 둔다.
Vera는 host 측 모든 I/O 인터페이스를 2배로 올리거나, 새로 도입했다. Grace 대비 비교는 다음과 같다:
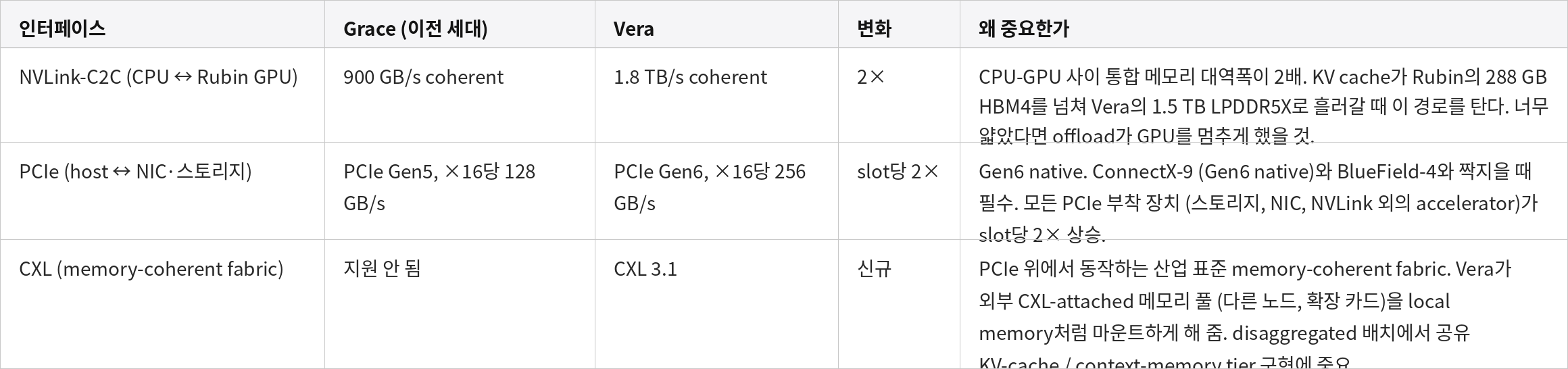
NVLink-C2C 행의 "Coherent"는 CPU와 GPU가 명시적 동기화 없이 동일한 메모리 내용을 자동 동기화를 통해 접근 가능하다는 의미다 (Part 2의 Rubin 섹션 (4)에서 자세히 다룬다).

Vera는 일반적인 경우 단일 CPU로 판매되지 않는다. 기본 배포 단위는 Vera Rubin Superchip이다 — Vera CPU 1개 + Rubin GPU 2개를 단일 host 마더보드 모듈 위에 긴밀히 결합한 구성이다.
CPU와 두 GPU는 NVLink-C2C를 통해 coherent 메모리 도메인 안에서 연결된다.
이것이 NVL72 랙의 기본 컴퓨트 빌딩 블록이다 — 각 compute tray가 superchip 2개를 담고, 랙은 18 tray를 담는다.
Superchip 한 개당 합계: 100 PFLOPS NVFP4 (Rubin GPU 2개 합산), 2 TB의 fast memory, 88 Olympus 코어, 모듈 위 전체 실리콘의 트랜지스터 합 ~6 T.
Vera는 agentic 처리, 분석, 클라우드, 스토리지, 인프라 서비스용으로 standalone 배포도 가능하지만, 랙 단위 플랫폼 thesis를 끌고 가는 것은 superchip 구성이다.
사양별 전체 변화 (와 엔지니어링적 귀결)는 앞부분 "Grace → Vera 한눈에 보기" 표에 정리되어 있다. 이 섹션은 그 배경에 깔린 thesis만 압축한다.
가장 깔끔한 해석: Vera CPU는 Rubin GPU에 데이터를 공급하는 데 있어 제약 요인을 최소화하는데 목적을 둔다. 모든 사양 업그레이드 — 대역폭, 용량, coherent link 폭, custom 코어 설계 — 은 연결되어있는 GPU의 처리량에 맞춰 보정된 결과다.
NVLink 6 Switch는 Vera Rubin의 scale-up fabric 칩이다 — 랙 단위 NVLink switch tray 안에 들어가, 72개의 Rubin GPU가 마치 단일 가속기처럼 서로 네트워킹 할 수 있게 만드는 실리콘이다.
"Scale-up" = 여러 칩으로 더 큰 가상 가속기를 (랙 내에서) 구축하는 것.
"Scale-out" = 데이터센터 안의 여러 랙을 연결하는 것 (ConnectX-9 + Spectrum-6가 별도로 담당).
NVLink Switch는 랙에 대해, multi-core 칩의 on-die ring/mesh와 같은 위치 — all-to-all 인터커넥트다.


변화는 세 개 항목으로 나뉜다 — switch 실리콘 내부에서 무엇이 바뀌었는지, tray와 랙이 그 실리콘을 어떻게 합산되는지, switch가 순수 스위칭을 넘어 추가로 어떤 능력을 갖췄는지.
칩 수준 실리콘

Tray + Rack 합산

In-Network Compute (SHARP)

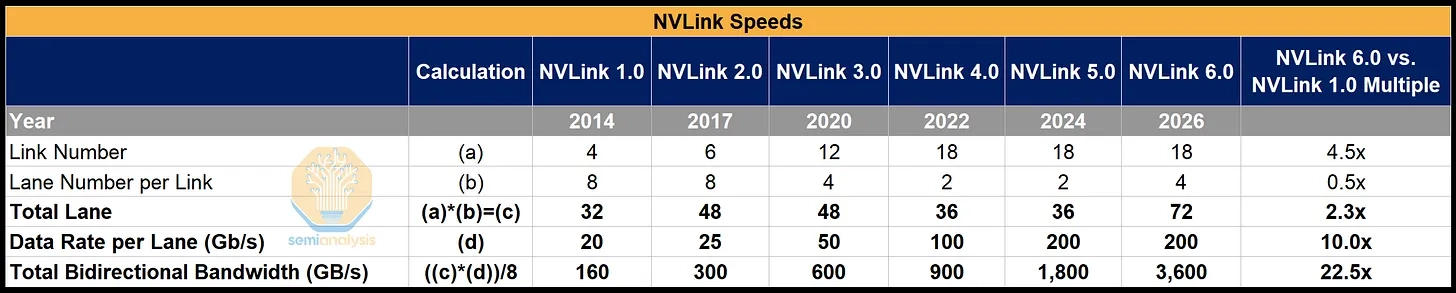
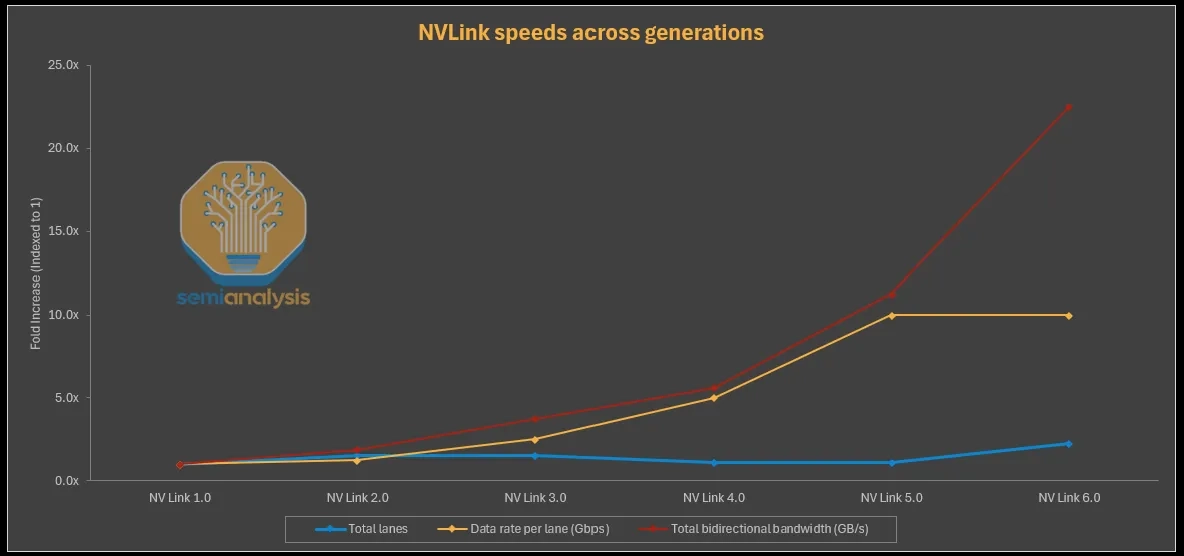
핵심 설계 선택은 칩 수준의 28.8 TB/s 스위칭 대역폭을 NVLink 5와 NVLink 6 사이에서 일정하게 유지했다는 것이다.
칩 수준 대역폭을 두 배로 늘리려면 더 큰 die 혹은 multi-die switch가 필요했을 텐데, 둘 다 설계 복잡도 비용이 크다.
대신 Nvidia는 칩 처리량은 그대로 두고, 링크당 SerDes 속도를 두 배로 (bidirectional signaling을 통해) 올리고 포트 수는 반으로 줄였다.
그 후 랙 단위 2배 스케일링은 tray나 랙 form factor를 바꾸지 않고서, tray당 칩 수를 두 배 (2 → 4) 늘리는 방식으로 달성됐다.
헤드라인 숫자 자체는 단순하다 — NVLink 5는 전기 lane당 224G를 전달했고, NVLink 6는 lane당 448G를 전달한다. lane당 2배 점프다.
흥미로운 질문은 어떻게 Nvidia가 modulation rate나 baud rate를 두 배로 올리지 않고 이 수치에 도달했느냐다 — 둘 중 무엇을 건드렸어도 새로운 SerDes 실리콘과 더 빡빡한 signal integrity 마진이 필요했을 것이다. 답은 같은 구리 wire pair 위에서의 동시다발적 bidirectional signaling이다.
왜 단순한 "케이블 수를 2배로 늘리기"가 답이 아니었나
NVLink 대역폭을 두 배로 만드는 순진한 방법은 기존 200G SerDes를 그대로 두고 backplane 위의 구리 케이블 수만 두 배로 늘리는 것이다. 두 가지 이유로 그 길은 통하지 않는다.

Blackwell NVL72 backplane은 이미 ~5,000개의 구리 케이블을 운반한다. 이를 ~10,000개로 두 배로 늘리는 일은 물리적으로 보면 어려운 과제고, GB200/GB300에서 이미 드러난 신뢰성 실패 모드를 훨씬 더 가속한다.
대안은 랙을 더 넓게 만드는 것 (AMD가 MI400 Helios 랙에서 택한 방향)인데, 이 경우 PCB trace 길이가 길어져 고속에서의 signal integrity가 저하된다.
그래서 Nvidia는 케이블 수는 그대로 두고, 대신 SerDes 속도를 밀어붙였다.
"Bidirectional"이 실제로 의미하는 것
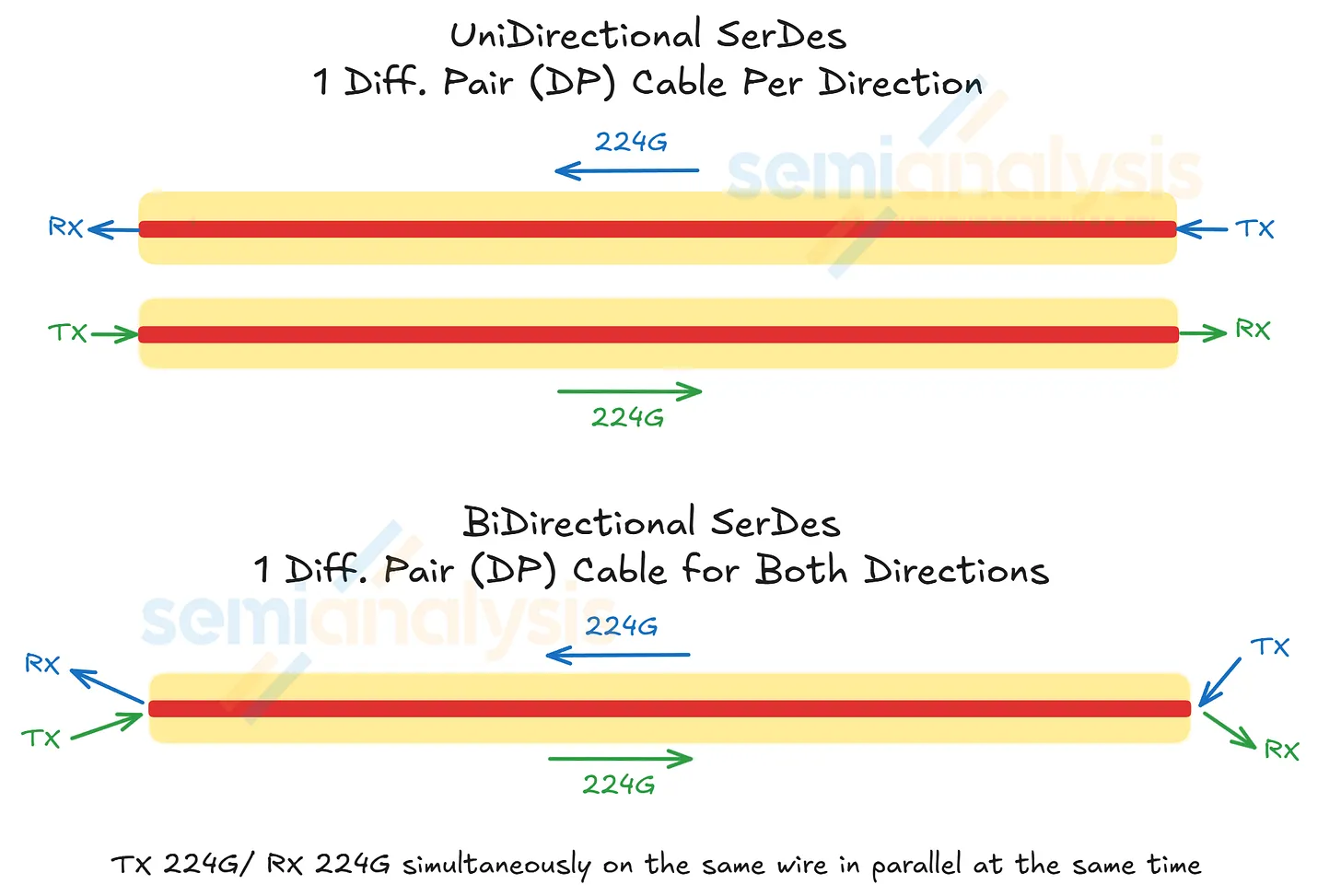
NVLink 전기 lane은 하나의 differential pair (DP) (동일한 크기에 극성이 반대인 신호를 운반하는 두 개의 도체)다. 과거의 NVLink lane pair는 한 방향씩 신호를 운반한다. Bidirectional SerDes는 동일한 pair 위에서 양 방향을 동시에 실행한다.
여기서 발생한 물리적 문제:
광학 (optics)에서는 optical circulator (들어오는 빛과 나가는 빛을 서로 다른 경로로 라우팅해 수신단에서 충돌하지 않도록 만드는 수동 소자)로 해결할 수 있다. (Google의 TPUv7이...




