

시리즈 안내 ⎯ Series Map
Part 1: 플랫폼 개요와 아키텍처 맵 — Blackwell → Rubin 플랫폼의 핵심과 주요 사양
Part 2: Rubin GPU 엔지니어링 심층 분석 — process node, SM, HBM4, NVLink-C2C, 패키지, CPX와 Groq 3 LPX
Part 3: Vera CPU와 네트워킹 실리콘 제품군 — Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6
Part 4 (현재 글): 랙 조립 — 트레이, PCB, 쿨링 — HGX와 NVL72, 컴퓨트 트레이 모듈, cableless 미드플레인, PCB 업그레이드, 액체 냉각
Part 5: 랙 전력과 네트워킹 fabric — 전력 공급, HVDC, tray ↔ rack 배선, scale-up NVLink 6, scale-out InfiniBand와 Ethernet
Part 6: 공급망 마스터 레퍼런스 — sub-system별 공급사 정리
1. 칩에서 Tray, 그리고 Rack까지 — 조립
개별 칩에 대한 설명이 끝났으니, 다음 질문은 그 칩들을 어떻게 조립하느냐다. 6개의 칩은 박스에 흩어진 상태로 출하되지 않는다 — 체계화된 어셈블리 구조 안으로 통합되어 출하된다.
체계: chip → module → compute tray → rack → SuperPOD
Chip — 개별 실리콘 (Rubin GPU, Vera CPU 등).
Module — 하나 또는 여러 개의 칩과 그에 부속된 부품 (메모리 소켓, VRM, 커넥터 등)을 담은 소형 PCB.
Compute tray — 여러 module을 midplane을 통해 하나로 연결한 1U 섀시.
Rack — compute tray 18개 + NVLink switch tray 9개 + power shelf 4개를 담은 19인치 캐비닛.
SuperPOD — Spectrum-6 Ethernet으로 연결된 여러 개의 랙 (섹션 8에서 다룬다).
이 섹션에서는 compute tray 내부의 6가지 module 종류, 그들이 서로 어떻게 연결되고 냉각·전원을 공급받는지, 그리고 이 tray 18개가 어떻게 하나의 NVL72 rack으로 결합되는지를 차례대로 따라간다.
(1) VR NVL72 랙 한 대의 해부
Nvidia가 헤드라인으로 내세우는 수치 (72 GPU 등)는 단순한 산수의 결과다.
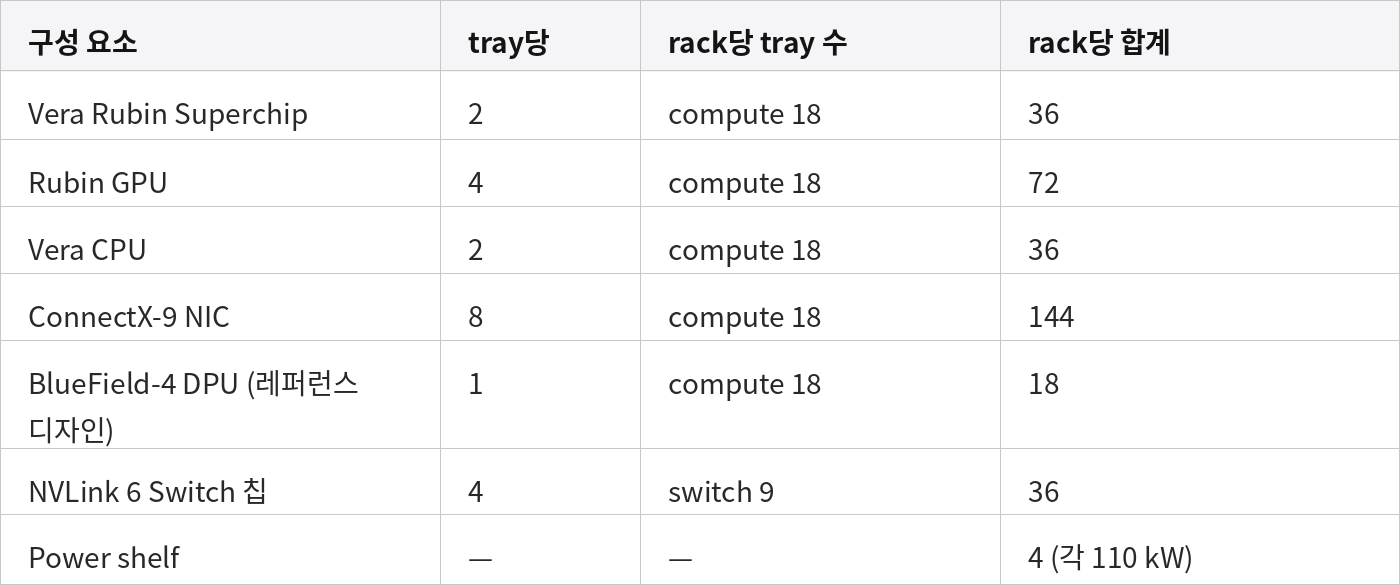
"Vera Rubin Superchip"은 단일 Strata module 위에 NVLink-C2C로 묶인 Vera CPU 1개 + Rubin GPU 2개다. tray당 superchip 2개, rack당 tray 18개 — 72-GPU 수치 뒤의 산수는 여기서 나온다.
원래의 명명은 사실 "VR NVL144"였다 — Nvidia가 한동안 GPU를 die 단위 (Rubin 패키지당 reticle-size die 2개 × 72 package = 144 die)로 세었기 때문이다. 2025년 12월에 package 단위로 환산해 "NVL72"로 되돌린 이후로, 그것이 현재까지 통용되는 표기다.
(2) HGX Rubin NVL8 — 대체 form factor

NVL72 tray 내부로 본격적으로 들어가기 전에 짚고 갈 점은, Rubin이 두 가지 배포 form factor로 출하된다는 사실이다. DGX (turnkey integrated appliance)와 HGX (OEM이 커스터마이즈하는 모듈형 GPU tray).
이 파트의 본문은 rack-scale VR NVL72 — DGX 스타일 제품 — 를 중심으로 다룬다. 대안 form factor는 HGX Rubin NVL8으로, GB300 → HGX B300 계보를 잇는 섀시-스케일 서버 (8 GPU)다. § 3부터는 NVL72에 집중하며, HGX는 본 섹션 안에서만 등장한다.
1) DGX vs HGX — 두 가지 설계 철학
DGX와 HGX는 하드웨어 차원에서 정반대 설계 철학을 구현한 두 모델이다. Nvidia GPU 제품이 둘 중 어느 모델을 기반으로 설계되었는지에 따라, 그 제품에서 허용되는 커스터마이징의 범위가 모두 결정된다.
DGX — Turnkey AI Appliance

고정된, 완전 통합 노드: 사전 정의된 GPU 수, NVLink 토폴로지, CPU, 메모리, 네트워킹, 소프트웨어 스택까지 — 전부 Nvidia가 단일 시스템으로 튜닝해 묶어 둔 구성.
벤더 관리형 통합: Nvidia가 전체 하드웨어 + 소프트웨어 스택을 직접 정의하고, DGX 파트너는 최소한의 구성 선택권만 가진 채 "있는 그대로"로 출하된다.
목적: 고객 쪽의 통합 마찰 (integration friction)을 최소화하는 것. 부품 더미가 아니라 곧바로 동작하는 AI 슈퍼컴퓨터를 산다는 발상이다.
Rubin 세대 사례: DGX Vera Rubin NVL72 랙, 그리고 그 랙들을 모아 구성한 DGX SuperPOD.
HGX — 모듈형 GPU 빌딩 블록

레퍼런스 GPU tray + 레퍼런스 디자인: Nvidia가 모듈형 GPU tray (SXM Rubin GPU 4개 또는 8개 구성)와 레퍼런스 아키텍처를 출하하면, OEM이 그 tray를 자체 섀시 안에 통합한다.
OEM과 클라우드 업체들의 커스터마이징: OEM (Dell, HPE, Lenovo, Supermicro)이 동일한 HGX GPU tray를 중심에 두고 자체 CPU (AMD 또는 Intel), RAM, 스토리지, 네트워크 fabric (Spectrum-X, InfiniBand, 또는 3rd-party), 관리 스택을 자유롭게 선택한다.
목표: Nvidia 브랜드 어플라이언스 형태가 아니라, 커스텀 설계 서버와 hyperscaler 랙 안에 Nvidia GPU를 확장 통합하는 것.
Rubin 세대 사례: HGX Rubin NVL8 서버 (이 섹션의 주제).
한 줄 요약
DGX의 입장: "이건 완성된 Nvidia 통합 AI 노드다. 설계된 그대로 가져가라."
HGX의 입장: "여기 표준 GPU tray를 줄 테니, 너의 시스템을 그 주위에 직접 구성하라."
2) Form-factor 비교 — Tray 수준 vs Rack 수준
가장 의미 있는 1:1 비교는 tray 수준에서 성립한다 — HGX Rubin NVL8 (완전한 섀시) vs VR NVL72 compute tray (랙 안의 1U tray 한 개). 맨 오른쪽 열은 참조용으로 전체 NVL72 rack을 함께 보여 준다.
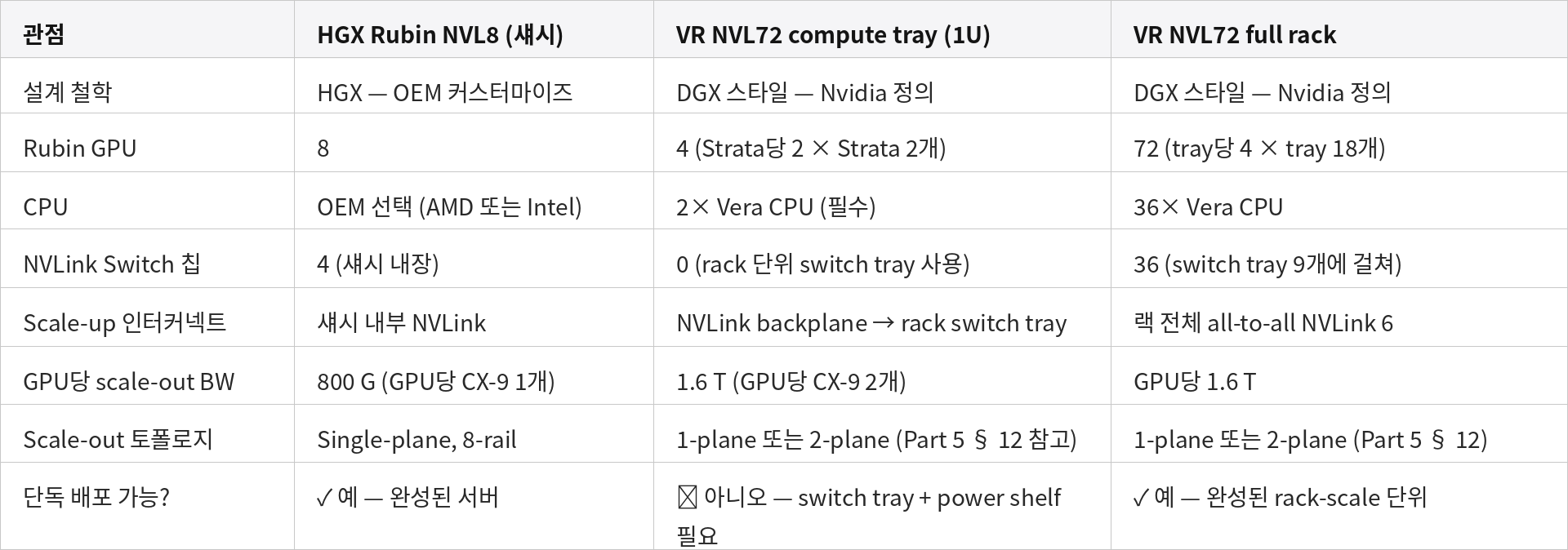
HGX NVL8과 VR NVL72 compute tray는 물리적 스케일이 비슷한 자리에 위치 (서버 섀시 ≈ 1U tray)하지만, 커스터마이즈 스펙트럼의 양 극단에 자리한다.
HGX NVL8은 그 자체로 배포 가능한 단위다. 반면 NVL72 compute tray는 더 큰 rack-scale 설계의 한 조각에 불과하며, standalone으로는 동작하지 않는다.
따라서 의미 있는 배포 수준 비교는 HGX NVL8 ↔ NVL72 rack, 의미 있는 아키텍처 수준 비교는 HGX NVL8 ↔ NVL72 compute tray 쌍에서 성립한다.
3) NVL72가 더 빠른 NIC 없이 GPU당 1.6 T에 도달하는 방법
NVL72는 1.6T NIC 실리콘을 실제로 사용하지 않는다.
대신, GPU당 800G CX-9 패키지 2개가 모두 PCIe Gen6 lane을 통해 짝을 이루는 Vera CPU에 연결된다.
그 결과 논리적으로 "1.6T NIC"이 구현된다 — HGX와 동일한 CX-9 실리콘을 GPU당 두 배의 밀도로 배치한 셈이다.
4) 도입 패턴 — Neocloud vs Hyperscaler
어떤 기업이 어떤 form factor를 택하느냐에는 명확한 방향성이 있다. 절대 규칙은 아니지만 분명한 경향이 존재한다.
Neocloud → DGX (VR NVL72) 쪽으로 기울어진다
플레이어: CoreWeave, Nebius, Lambda, Crusoe, TensorWave.
비즈니스 모델: GPU-as-a-Service — "GPU 임대업"으로서 배포 속도와 GPU 활용도의 최적화가 핵심.
왜 DGX인가: 사전 최적화된 Nvidia 소프트웨어 스택과 turnkey rack-scale 시스템이 통합에 드는 시간을 크게 줄여 준다. Neocloud는 커스텀 서버 엔지니어링 리스크를 떠안지 않고도 수천 개의 GPU를 빠르게 띄우는 것이 우선이다.
수요 패턴: GPU 수, TCO, uptime이 커스텀 토폴로지보다 더 중요하다. 표준화된 DGX 노드는 "그냥 작동한다"는 안정성이 자산이 된다.
Hyperscaler → HGX 쪽으로 기울어진다
플레이어: AWS, GCP, Microsoft Azure, Meta (실무 차원에서는 xAI도 자사 fleet 일부에 사용 중).
비즈니스 모델: 대규모의 자체 커스터마이즈된 데이터센터 fabric. 내부 팀들이 커스텀 서버, 섀시, 네트워킹, 랙 설계를 직접 엔지니어링한다.
왜 HGX인가: Rubin GPU tray를 자체 선택한 CPU (in-house ARM, AMD, Intel)·펌웨어·telemetry·NIC·전력 공급·오케스트레이션과 자유롭게 페어링할 수 있게 해 준다. HGX tray는 기존 커스텀 랙 아키텍처에 자연스럽게 끼워 넣을 수 있고, Nvidia 브랜드 박스를 강제하지 않는다.
수요 패턴: 수백만 대의 서버에 걸친 유연성, 규모, 동질적 통합이 out-of-the-box turnkey 속도보다 우선시된다.
혼합 배포도 흔하다
일부 neocloud는 트레이닝 tier에는 DGX 랙 (빠른 배포, 높은 신뢰성), 인퍼런스 tier에는 HGX (저렴하고 커스터마이즈 가능)로 나눠 운영한다.
일부 hyperscaler는 fleet 대부분을 HGX로 유지하면서, 내부 AI 랩이나 전략 고객 응대용으로만 소수의 DGX 랙을 구매하기도 한다.
5) HGX가 NVL72와 함께 여전히 존재하는 이유
HGX는 rack-scale NVL72가 과한 환경 — 엔터프라이즈 클러스터, 혼합 워크로드 서버, 랩-스케일 인프라 — 즉, 더 작고 유연한 배포가 필요한 영역을 노린다. 자사 섀시에 Rubin GPU를 통합하려는 hyperscaler도 여기 포함된다.
HGX는 single-plane, 8-rail 토폴로지를 따른다 — 1-plane 공식의 한도 (93,312 GPU)에 결국 부딪히게 된다. 사실 HGX 클러스터는 애초에 그보다 훨씬 작은 규모로 빌드되는 경향이 있다 — 8-GPU 섀시 단위 입도로 거대한 클러스터를 ...




