Vera Rubin Decoded Pt. 2 | Rubin GPU 엔지니어링 심층 분석

s4ndwalker
2026.05.26조회수 98회
s4ndwalker
구독자 67명구독중 13명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.

시리즈 안내 ⎯ Series Map
Part 1: 플랫폼 개요와 아키텍처 맵 — Blackwell → Rubin 플랫폼의 핵심과 주요 사양
Part 2 (현재 글): Rubin GPU 엔지니어링 심층 분석 — process node, SM, HBM4, NVLink-C2C, 패키지, CPX와 Groq 3 LPX
Part 3: Vera CPU와 네트워킹 실리콘 제품군 — Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6
Part 4: 랙 조립 — 트레이, PCB, 쿨링 — HGX와 NVL72, 컴퓨트 트레이 모듈, cableless 미드플레인, PCB 업그레이드, 액체 냉각
Part 5: 랙 전력과 네트워킹 fabric — 전력 공급, HVDC, tray ↔ rack 배선, scale-up NVLink 6, scale-out InfiniBand와 Ethernet
Part 6: 공급망 마스터 레퍼런스 — sub-system별 공급사 정리

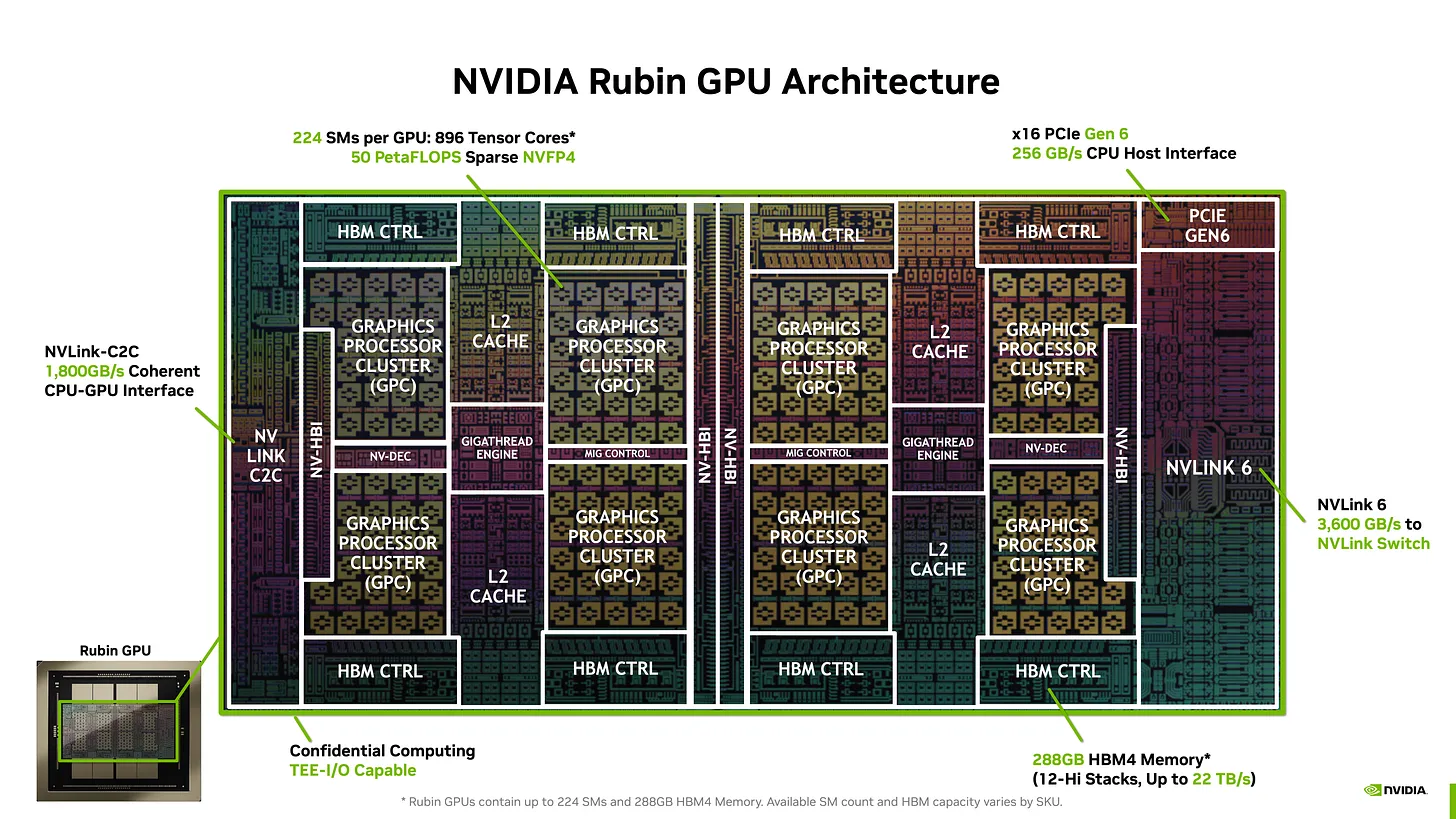
Blackwell 대비 Rubin의 기본 구조는 동일하게 유지된다 — reticle-sized logic die 두 개가 나란히 배치되고, 각각 HBM 스택으로 둘러싸여 있다. ("Reticle-sized"란 각 다이가 현재 photolithography 장비가 단일 노출 (single exposure)로 인쇄할 수 있는 최대 크기, 약 800 mm²라는 뜻이다. "Die"는 패키징되기 전 칩의 회로를 담은 실제 실리콘 정사각형을 가리킨다.)
8개의 HBM 스택은 두 다이와 함께 동일한 패키지에 배치된다. 변화는 다이 내부와 패키지 주변에서 일어난다.
35 PFLOPS dense FP4라는 수치 (GB200 대비 3.5배)는 세 가지 요인이 복합적으로 작용한 결과다.
SM (Streaming Multiprocessor) 수: 160 → 224. SM은 Nvidia GPU의 기본 빌딩 블록으로, CUDA Core (범용 연산 유닛), Tensor Core (행렬 연산 유닛), 레지스터, shared memory를 담은 소형 프로세서다. 현대 GPU는 본질적으로 수백 개의 SM이 병렬로 실행되는 구조다.
5세대 Tensor Core의 폭이 SM당 clock당 32,768 FP4 MAC으로 두 배 늘어났다. MAC은 multiply-accumulate 연산 (a × b + c)으로, 신경망 수학에서 사용되는 행렬 곱셈의 핵심 연산이다.
클럭: 1.90 GHz → 2.38 GHz (+25%). GPU의 내부 사이클 속도로, 클럭이 빠를수록 실리콘 단위당 초당 더 많은 연산을 수행할 수 있다.
해당 문서 내 설명은 SM에서 시작해 메모리, I/O, 정밀도·sparsity, 전력, 마지막으로 패키지 순서로 진행된다.
Rubin은 TSMC의 3nm 공정을 사용하며, I/O를 chiplet 단위로 분산한다. 동시에 Blackwell의 2-die + 8-HBM-stack 레이아웃은 그대로 유지된다.
"chiplet 단위로 분산된다는 것"은 하나의 거대한 monolithic die에 통합하는 대신, 칩을 여러 작은 조각 (chiplet)으로 나눈 후 동일한 패키지에 결합하는 방식이다.
"I/O" (input/output)는 칩에서 외부 세계와 통신을 담당하는 부분으로, 주로 다른 GPU와의 NVLink, CPU와의 NVLink-C2C를 가리킨다.
Compute die는 reticle-size를 유지하면서, I/O 대신 더 많은 SM과 더 넓은 Tensor Core에 면적을 할당한다. NVLink-C2C와 NVLink 6 I/O 블록은 logic die와 독립적으로 설계 및 수율 관리가 가능한 별도의 chiplet으로 분리된다. ("수율 관리"란 manufacturing yield를 의미한다 — 칩을 더 작은 조각들로 나누면 제조 결함이 발생할 시 monolithic die 전체가 아닌 해당 결함 부분만 오작동하기에, 전체 실리콘 중 사용 가능한 비율이 높아진다.)
트랜지스터 수는 208 B (Blackwell) → 336 B (Rubin)로 +60% 증가한다. 더 커진 logic die, 새로운 I/O chiplet, 두 배가 된 Tensor Core가 합산된 결과다.
SM당 Tensor Core의 변화가 FP4·FP8 스케일링을 주도한다. Tensor Core의 폭은 각 SM이 clock cycle당 수행할 수 있는 multiply-accumulate 연산 횟수를 결정한다.

특히, Tensor Core 폭의 2배 증가는 NVFP4와 FP8에만 적용된다.
더 넓은 포맷인 BF16과 TF32는 Blackwell과 동일하게 유지되어, FP16 성능은 Blackwell 대비 1.6배 상승에 그친다. BF16 (bfloat16)과 TF32 (Nvidia의 TensorFloat-32)는 각각 16비트·19비트 포맷으로, 일반적으로 AI 모델 훈련에 사용된다 — FP16보다 더 넓은 수치 범위를 제공하는 대신 FP8/FP4보다는 폭이 넓다.
이 아키텍처 결정은 대부분의 훈련 및 추론 워크로드가 TF32와 BF16에서 FP8·FP4로 옮겨갈 것이라는 Nvidia의 판단을 반영한다.
Special Function Units (SFU). SFU는 각 SM 내부에서 "transcendental" 연산 (지수, 로그, sine, 역수 등 기본 multiply/add보다 훨씬 복잡한 연산)을 처리하는 소형 수학 유닛이다.
Rubin은 SFU 경로를 확장한다. Softmax 가속 (SM당 clock당 EX2 연산으로 측정 — EX2는 2^x, softmax가 의존하는 지수 연산을 의미)이 Blackwell의 16에서 Rubin의 32 (FP32) / 64 (FP16) 로 상승한다. transformer 모델의 attention 블록을 지배하는 exp/softmax 연산이 2~4배 향상되는 셈이다.
(Softmax는 임의의 숫자 벡터를 확률 분포로 변환하고, "attention" 메커니즘 (다음 토큰을 예측하기 위해 모델이 이전 토큰 중 어느 것이 중요한지 가중치를 매긴다)은 inference당 수십억 번 softmax를 호출한다.)
이 SFU 확장이 없었다면 attention 커널이 새로운 FP4 처리량의 병목이 되었을 것이다.
AI + 과학 컴퓨팅의 융합. Rubin은 FP32/FP64 처리량을 AI 스타일 행렬 워크로드 쪽으로 재조정한다. FP64는 전통적인 과학 시뮬레이션 코드 (기후, 유체역학, 계산물리학)에서 사용되는 64비트 double-precision 포맷이다. "Vector" 연산은 배열 원소별 (element-wise) 연산이고, "Matrix" 연산은 대규모 행렬-행렬 곱셈으로, Tensor Core가 가속하는 대상이다.
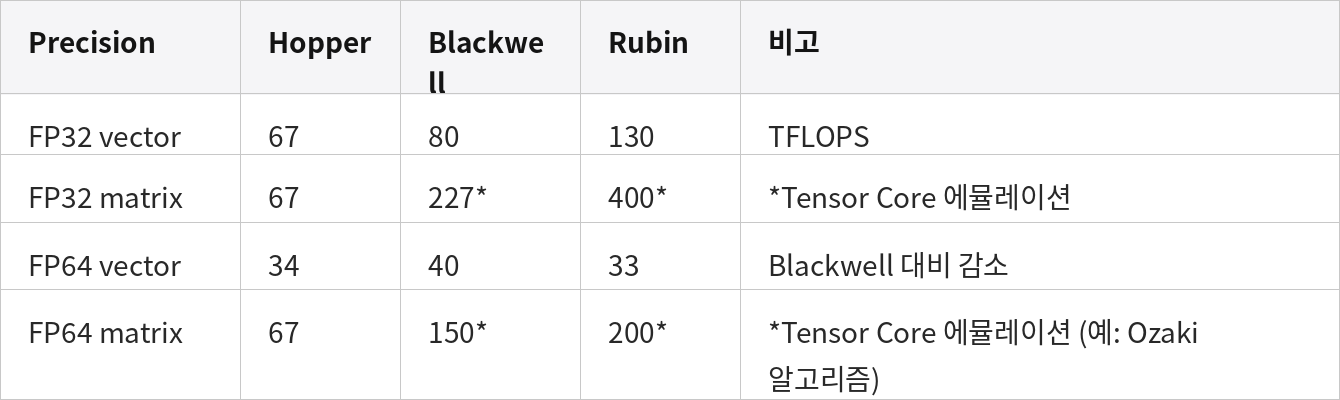
FP64 vector 처리량은 Blackwell 대비 다소 감소한다. Nvidia가 해당 실리콘 면적을 FP4·FP8과 Tensor Core용으로 재할당했기 때문이다.
행렬 연산에서 FP64급 정확도가 필요한 과학 코드는 "Tensor Core matrix emulation"을 거치도록 설계되어 있다. 여러 차례의 저정밀 Tensor Core pass를 실행하고, 오차 보정 규정을 활용해 결과를 결합하여 FP64 결과를 만들어 낸다.
Ozaki 알고리즘이 그러한 기법 중 하나로, 저정밀 하드웨어에서 FP64에 준하는 정확도를 제공한다. Nvidia의 cuBLAS 라이브러리 (표준 선형대수 커널 라이브러리)가 이 에뮬레이션을 기본 탑재한다. FP64 vector는 여전히 연산 처리량보다 메모리 대역폭에 성능이 좌우되는 코드들에서 의미가 있다.
Rubin은 HBM3E (Blackwell에서 사용된 세대)에서 HBM4로 전환한다.
HBM3E 대비 스택당 bus width가 두 배가 됐다. "Bus width"는 HBM 스택을 GPU에 연결하는 병렬 wire의 개수로, wire가 많을수록 clock당 더 많은 데이터를 옮길 수 있다.
Pin speed: 10.8 GT/s (gigatransfers per second — 각 wire가 토글되는 속도).
총 대역폭 목표: 22 TB/s로 Blackwell의 8 TB/s 대비 약 2.75~2.8배. 용량은 GB300과 동일한 288 GB로 유지.
처음 GTC 2025에서는 13 TB/s로 발표되었으나, 이후 Nvidia가 목표를 상향 조정했다.
새로운 memory controller (HBM 읽기·쓰기를 조율하는 on-die 로직) 및 더 긴밀한 compute-memory 통합과 짝지어, 부하 상황에서도 SM 파이프라인에 데이터가 효율적으로 제공된다.

대역폭 업그레이드가 강제된 이유. 원래의 13 TB/s 사양 하에서는 AMD의 MI450이 Rubin보다 더 높은 메모리 대역폭으로 출하될 상황이었다.

앞서 나가기 위해 Nvidia는 JEDEC 표준 이상의 HBM4 pin speed를 요구했다. JEDEC (Joint Electron Device Engineering Council)은 공식 메모리 사양을 정하는 산업 표준 기관으로, 모든 DRAM 공급사는 JEDEC 표준에 맞춰 설계한다.
Nvidia는 사실상 SK Hynix, Samsung, Micron에게 공식 사양 이상으로 오버클럭하도록 요구하고 있으며, 메모리 공급사들은 표준이 보장하지 않는 속도로 부품을 검증해야 하는 상황이다.
HBM4 공급사 Pin Speed 동향
Rubin 세대에서 3사 HBM 경쟁은 명확한 순위가 매겨진다.
SK Hynix — 현재 HBM4 pin speed 검증에서 선두. 목표치인 10.8 GT/s에서 첫 Rubin-grade HBM4를 출하할 것으로 예상된다.
Samsung — SK Hynix를 바짝 뒤쫓는 중이며 Nvidia에서 검증 단계. Rubin 양산이 본격화되면 second-source 공급사 역할을 할 것으로 보인다.
Micron — HBM4 검증에서 상당히 뒤처졌으며 Rubin HBM4에서 사실상 배제되었다. HBM이 logic die 다음으로 GPU 패키지에서 가장 비싼 단일 부품이라는 점에서 의미 있는 상업적 타격이다.
실제로 의미하는 바.
초기 Rubin 출하분은 22 TB/s 헤드라인이 아닌 ~20 TB/s에 가깝게 떨어질 가능성이 높다. 공급사들이 양산 물량에서 풀 10.8 GT/s pin speed를 유지하기 어렵기 때문이다.
Pin speed 검증이 새로운 병목이다. JEDEC 사양을 초과해 부품을 검증해 달라고 공급사에 요구한다는 것은, 수율과 binning ratio가 산업 표준이 아닌 Nvidia 전용 기준이 된다는 의미이기도 하다. 공급 연속성에 실질적인 리스크다.
"Micron이 배제됐다"는 결과는 AI 하드웨어 공급망 전반에 파급된다 — 2026년 Micron의 HBM 매출에서 Nvidia 비중은 급감하는 반면, SK Hynix와 Samsung은 점진적 점유율을 추가로 가져간다.
Rubin의 pin speed 목표가 실제로 검증되기 전까지, 22 TB/s 헤드라인은 보장된 출하 수치가 아닌 포부적 사양으로 받아들이는 것이 현실적이다.

Rubin의 off-die 통신은 이번 세대에 새로 도입된 두 개의 전용 I/O chiplet으로 분리된다. NVLink는 Nvidia의 독점 고대역폭 chip-to-chip 인터커넥트로, 표준 PCIe (GPU를 마더보드에 연결하는 산업 인터페이스)보다 훨씬 빠르다. 절대 수치는 다음과 같다:





