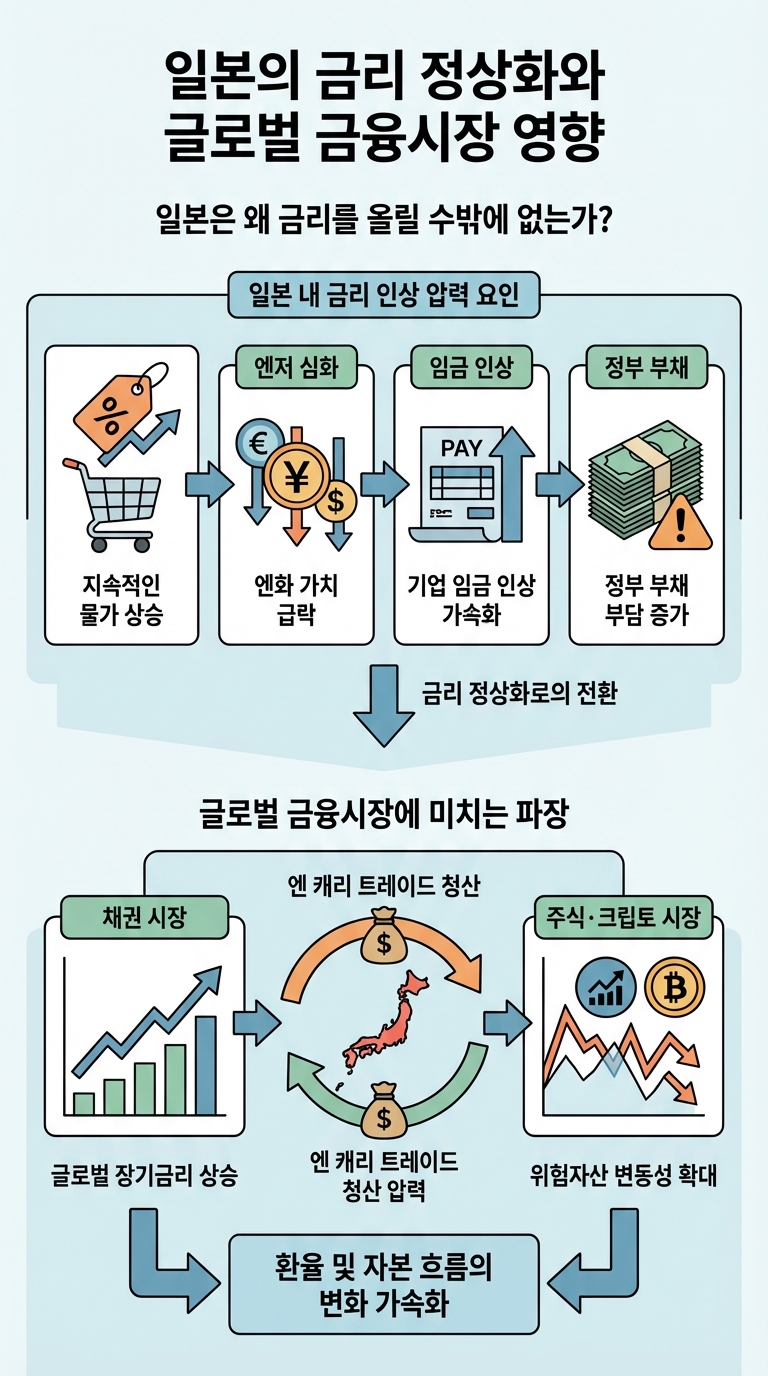
요사이 꽤 의미심장한 뉴스가 들려왔습니다. 미국의 핵심 우방인 싱가포르가 국가 AI 사업에 굳이 중국 알리바바의 모델을 쓰기로 했다는 소식, 그리고 에어비앤비 CEO가 "중국 모델이 빠르고 저렴해서 쓸 수밖에 없다"고 털어놓은 일이었죠.
얼핏 보면 의아한 일이지만 속을 들여다보면 이유는 간단한듯 합니다. 아무리 국제 정세가 복잡해도 비즈니스의 현장에서는 아직까지는 '이념보다는 실리'가 먼저로 보입니다.
그런데...궁금증이 생깁니다. 미국이 그토록 철저하게 AI 반도체 줄을 죄었는데, 중국은 도대체 무슨 수로 글로벌 기업들이 탐낼 만한 경쟁력을 갖췄을까??
찾아보니.. 중국은 전혀 다른 길을 가고 있었습니다. 하드웨어의 한계를 '압도적인 가성비'와 '집요한 현지화'로 뚫어낸 것이죠.
미국이 인간을 뛰어넘는 AGI(인공일반지능)라는 꿈을 향해 달릴 때, 중국은 미국보다 20분의 1이나 싼 비용으로 당장 쓸 수 있는 '실용적 AI'를 뿌리며 조용히 자기들만의 영토를 넓히고 있었습니다.
기술 경쟁에만 우리가 집중할때는 아닌것 같습니다. '압도적 연산력(Compute)의 미국'과 '극한의 효율성(Cost)의 중국'이 맞붙는 거대한 체제 경쟁..
규제의 담장을 넘어 독자적인 생태계를 구축하고 있는 중국의 생존법, 그리고 이 흐름 속에서 우리가 주목해야 할 것은 무엇인지.. 정리해봅니다.
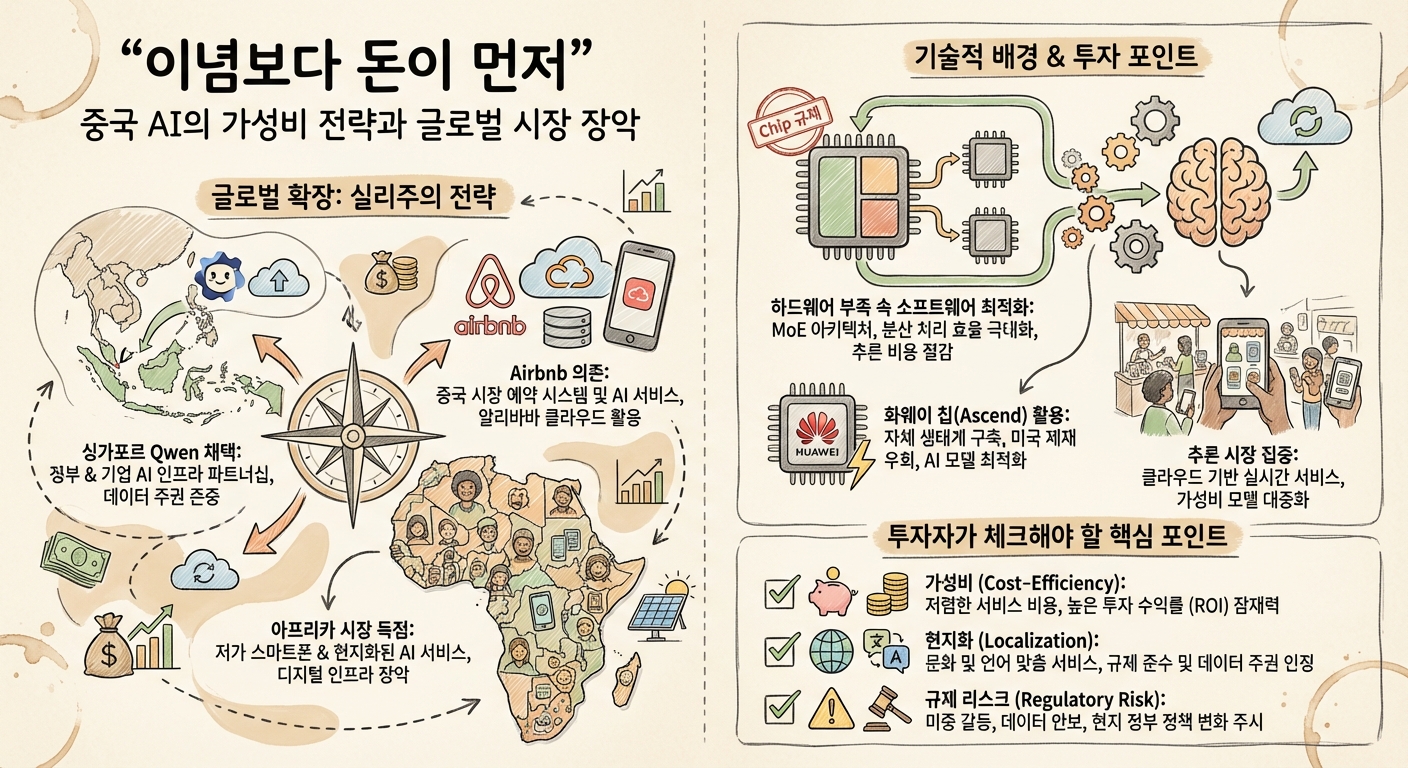
1. 간단 요약
중국 AI, 이미 개도국 + 실리콘밸리 + 싱가포르 정부 프로젝트까지 뚫고 있는 상황임
핵심 무기
가성비: 토큰 단가가 미국 대비 1/10~1/20 수준까지 내려감
다국어·저자원 언어: 동남아·아프리카 언어 커버 강함
오픈소스·커스터마이즈: DeepSeek, Qwen, Yi 등 오픈웨이트 모델 다수 공개됨
문제는, 최상위급 NVIDIA 칩이 부족한데도 사업이 커지고 있다는 점
이게 가능한 이유와, 이 구조를 투자자가 어떻게 읽어야 하는지가 핵심 포인트임
2. 중국 AI의 1차 무기: 가성비 + 다국어 + “AI 일대일로”
2-1. 가성비 구조
DeepSeek R1, OpenAI o1 대비
토큰 단가가 10~20배 이상 저렴하다는 비교 나옴
알리바바 Qwen3-Max,
대형 모델인데도 백만 토큰당 1달러대 수준 가격까지 인하함
중국 빅테크들, 단기 이윤보다
“생태계 확보 + 점유율 먼저, 돈은 나중” 전략 쓰는 중임
2-2. 다국어·로컬 언어
Qwen3
119개 언어·방언, 36조 토큰 학습
동남아 언어 벤치마크(SEA-HELM)에서 상위권 기록
싱가포르의 SEA-LION 팀
Meta Llama 계열 쓰다가 Qwen 기반 Qwen-Sea-Lion-v4로 전환
이유: 인도네시아어·태국어 등에서 서구 모델 성능 부족함을 직접 확인했기 때문임
2-3. “AI 일대일로”
중국 AI,
저가·오픈소스 모델 + 현지 언어 맞춤형 튜닝 조합해서
동남아·중동·아프리카·남미에 패키지처럼 들어가는 중
과거 일대일로(도로·항만·철도)가 인프라 중심이었다면
→ 지금은 AI 인프라·앱·클라우드 버전으로 확장되는 그림임
3. 그런데 칩은? 고급 GPU 부족 속에서도 확장되는 구조
3-1. “칩이 없다”가 아니라 “최상위 칩이 부족한 상태”
미국이 A100·H100·B200급 칩 수출을 강하게 제한하는 건 사실임
대신 현실은 대략 이런 상태임
제재 전 들여온 A100·A800·H800 재고 여전히 존재
수출 규제 맞춰 설계된 H20·L20 같은 다운그레이드 칩은 아직 사용 가능
중국 내에서는 화웨이 Ascend 910B 같은 국산 GPU가 성장 중임
H100급 최상위 칩은 부족하지만,
“중·대형 모델을 돌릴 정도의 연산력은 어떻게든 확보하고 있는 상황”이라 봐야 함
3-2. 훈련은 해외, 서비스는 국내
알리바바·바이트댄스 등
싱가포르·말레이시아·중동 데이터센터에 NVIDIA GPU 모아놓고
거기서 LLM 훈련 돌리는 방식 사용 중이라는 보도 다수 있음
훈련 끝난 모델은
중국 내에선 화웨이 Ascend 등 국산 칩 위에서 서비스
동남아·중동 유저는 현지 데이터센터에서 직접 서비스 받는 구조임
DeepSeek
제재 전에 확보한 NVIDIA H800 + 국산 칩 조합으로 R1 훈련했다는 분석 있음
요약하면,
Training(훈련)은 해외·제3국 GPU,
Serving(서비스)은 중국산 칩·해외 데이터센터로 나눠서 하는 구조라서
칩 제재를 “에둘러 피해 가는” 중이라고 보면 됨
3-3. 모델 효율화 + 소형화
DeepSeek, Qwen, Yi 등
Mixture-of-Experts, 양자화(3bit) 등으로
같은 성능을 더 적은 연산으로 내는 방향에 집중함
실제 서비스에서는
꼭 초거대 GPT-5급 모델이 필요한 경우가 많지 않음
8B, 14B, 30B급 중형 모델이면 웬만한 업무 커버 가능함
그래서
“최상위 칩이 없어도, 효율 좋은 중형 모델을 많이 깔면 된다”는 전략이 먹히는 중임
3-4. 가격 덤핑이 칩 부족을 덮는 구조
칩이 부족한 대신, 중국은 “말도 안 되게 싼 가격”으로 승부를 봄.
DeepSeek R1 API는
입력 기준 0.55달러/백만 토큰,
OpenAI o1은 15달러/백만 토큰으로,
→ 대략 25배 이상 가격 차이가 난다는 비교가 있음.데이터캠프+2Cody - The AI Trained on Your Business+2
알리바바는 Qwen3-Max 등 고급 모델 가격을 크게 내리고,
일부 라인은 입력 0.459달러/백만 토큰, 출력 1.836달러/백만 토큰까지 인하,
심지어 오프피크(야간)에는 추가 50% 할인까지 해줌 .
중국 내 가격 전쟁 탓에
알리바바 클라우드의 AI 관련 매출 성장은 분기 기준 4%대에 그치고,
Qwen-Long 가격은 97% 인하, 바이트댄스 Doubao도 63% 인하 등으로
→ 매출보다 “시장 점유율 + 생태계 확보”에 더 초점을 두고 있습니다.Reuters
토큰단가를 1/10~1/20 수준으로 낮추면
같은 매출을 만들기 위해서는 더 많은 연산이 필요하지만
동시에 사용자가 폭발적으로 늘어남
중국 입장에선
단기 이익보다 “데이터 확보 + 글로벌 점유율 + 생태계”에 우선순위 두는 중
칩이 부족해도,
“적당한 성능 + 미친 가격” 조합으로 시장을 먹는 전략이라고 보면 됨
3-5. 그래도 미국과의 ‘연산력 차이’는 남아 있음.
연구에 따르면, 2026년 이후 미국이 중국으로의 AI 칩 수출을 완전히 막으면
→ 미국의 총 AI 연산력은 중국의 31배 수준,
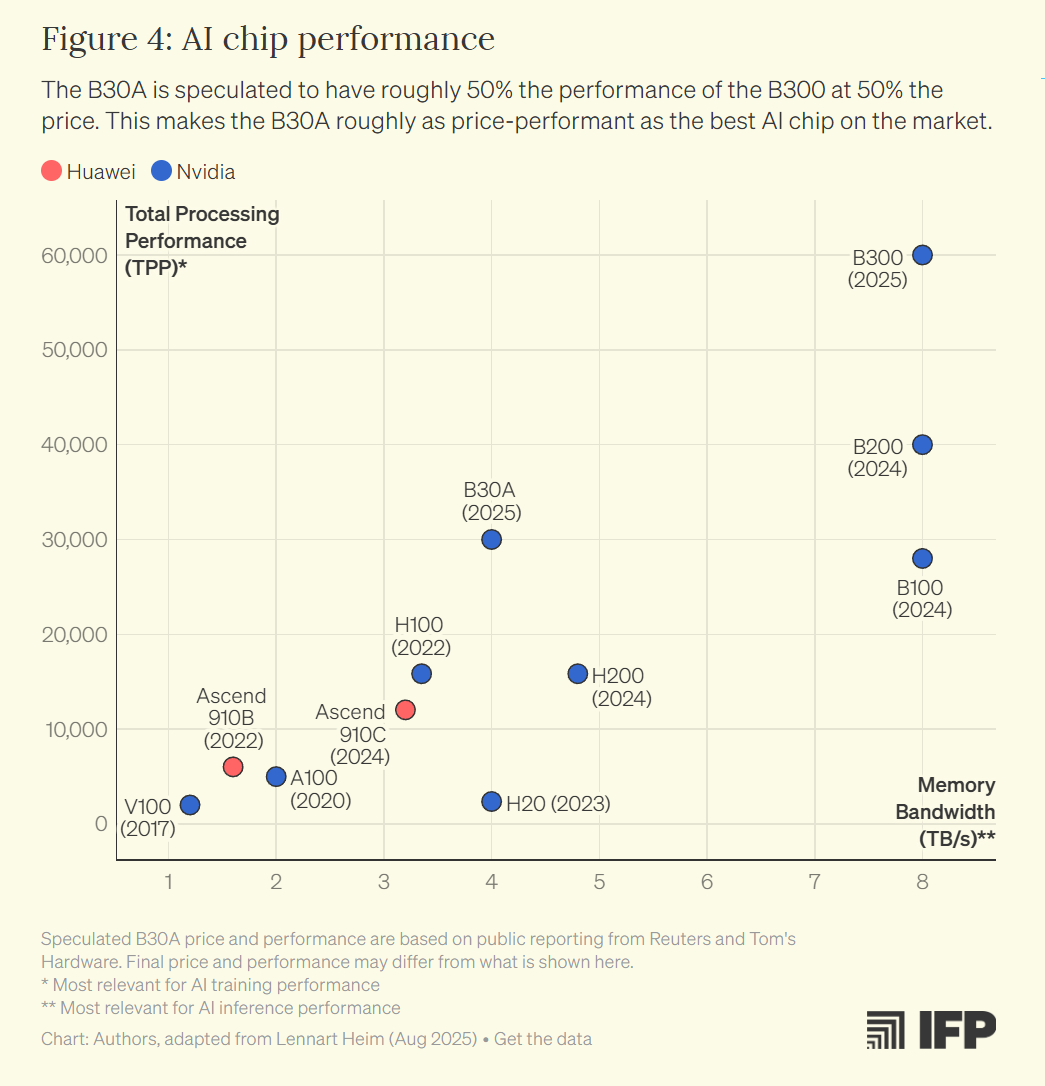
반대로 H20·B30A 수준의 다운그레이드 칩 수출을 허용하면
→ 격차는 4배 미만까지 줄어든다고 추정.
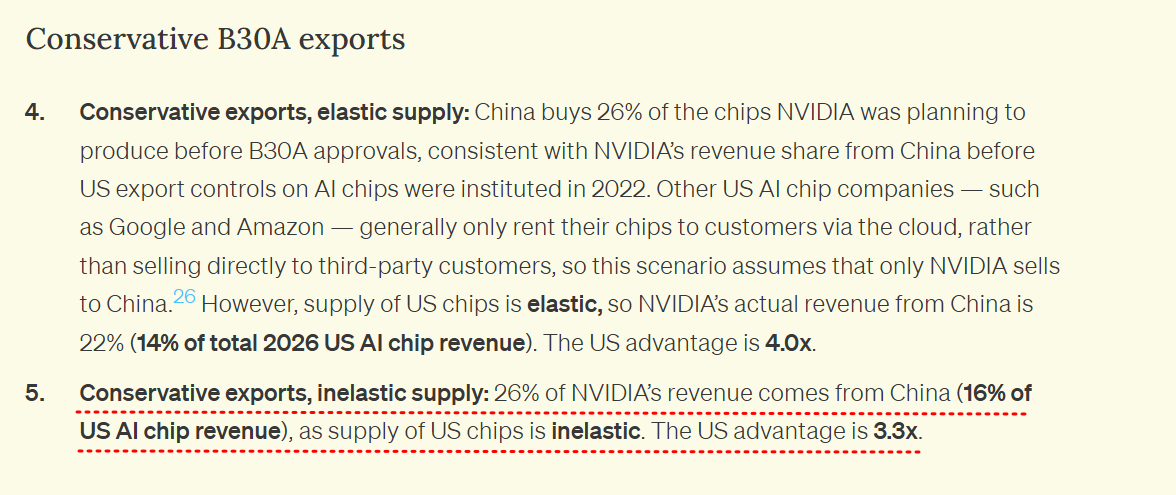
“IFP의 시뮬레이션에 따르면, B30A 수출을 허용하는 보수적 시나리오에서
미국의 AI 칩 연산력 우위는 최소 3.3배(4배 미만) 수준까지 축소될 수 있다.”
출처 : https://ifp.org/the-b30a-decision/?utm_source=chatgpt.com
즉,
절대적인 연산력(Compute) = 여전히 미국 우위
가격 대비 연산력·효율 = 중국이 많이 따라온 상황
이라고 이해하는 게 현실적.
4. 구체 사례로 보는 중국 AI 확장
4-1. 싱가포르 정부 프로젝트
싱가포르 국가 AI 프로젝트 SEA-LION
초기에 Llama 계열 기반으로 시작
동남아 저자원 언어 성능 문제로,
Qwen3-32B 기반 Qwen-Sea-Lion-v4로 전환함
(Qwen3-32B = 알리바바가 만든 큰 AI 엔진,SEA-LION = 싱가포르가 만든 ...