연산에서 네트워킹으로, 병목의 전환

s4ndwalker
2026.06.05조회수 187회
s4ndwalker
구독자 84명구독중 14명
내러티브와 데이터로 투자/트레이드 전략을 구현합니다.
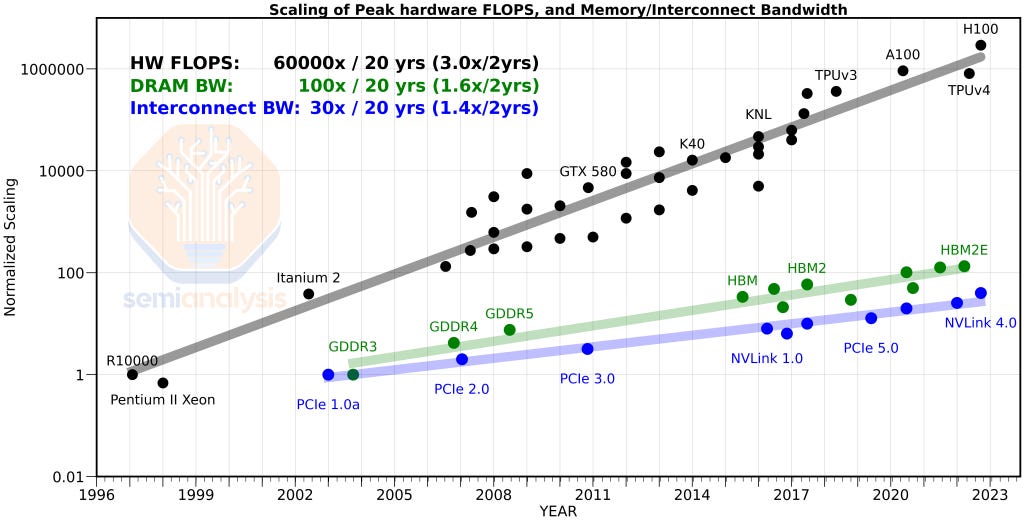
칩의 연산 성능은 20년간 ~60,000배 뛰었지만, 그 연산에 데이터를 공급하는 배선은 따라오지 못했다.
오늘날 AI 가속기의 진짜 제약은 네트워킹이다. GPU↔GPU 네트워크든 GPU↔메모리 HBM 버스든 본질은 같다. 둘 다 비좁은 die edge를 지나야 하기 때문이다.
구리에는 더 내어줄 가장자리가 없다. 결국 광학이 해답이나, 전환은 단계적으로 온다. SerDes를 하루아침에 걷어 내고 co-packaged optics로 바꿀 수는 없다.
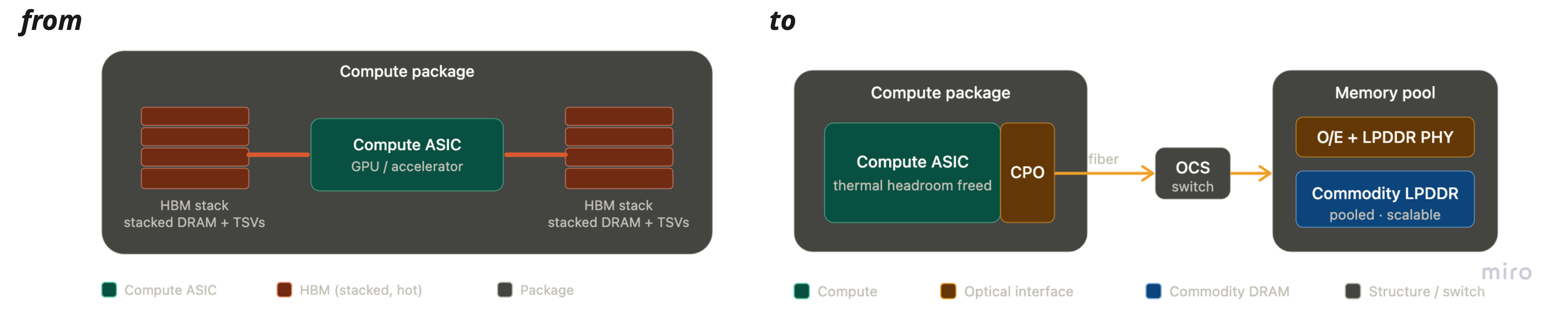
일단 광학이 주 I/O 매체가 되면, 메모리는 GPU 옆에 함께 패키징하는 대상이 아니라 fabric 너머에서 붙여 쓰는 자원이 된다 — 연산 풀과 값싼 commodity DRAM 풀이 하나의 저지연 optical fabric에 연결되고, optical switch가 경로를 잡는다.
HBM은 사라지지 않는다 — 캐시 계층으로 강등될 뿐이다.
Section 0 — 왜 광학인가, 왜 단계적으로 접근할 수밖에 없는가에 대해 짧게 되짚는다.
Section 1–3 — 핵심: 가속기는 네트워크에 묶여 있다 → 메모리도 네트워크의 일부다 → 메모리를 optical 스위치 너머로 분리한다.
Section 4 — 어떤 기업들이 해당 아키텍처를 개발하고 있는지, 어디를 봐야 하는지.
네 개의 출처를 기반해 핵심 주장 하나로 엮었다. 엔지니어링 방향성은 출처들 사이에서 비교적 잘 교차 검증되지만, 정확한 시점과 HBM 쇠퇴의 규모는 불확실하다.
Irrational Analysis — HBM: High-Bandwidth Mistake (Jun 01 2026). 메모리 분리 (disaggregation) 주장. 자기 포지션을 방어하는 색채가 강하다 — DRAM 롱 포지션에서 Samsung을 노골적으로 미는 입장이며, "7~10년 내 HBM 물량 ~90% 감소" 주장은 전적으로 latency 문제 (§3)가 대규모로 풀린다는 전제에 기댄다.
SemiVision — Lightmatter Taiwan Tech Day in 20 Minutes (Jan 29 2026)와 Lightmatter at Computex 2026: The Bottleneck Has Shifted from Compute to Interconnect (Jun 04 2026). Optical fabric 쪽 주장으로, 서술의 중심은 Lightmatter다.
SemiAnalysis — Co-Packaged Optics (CPO) Book — Scaling with Light. CPO의 경제성·단계론·신뢰성 데이터.
CPO 전환, DSP 비용·전력 근거, Rubin의 HBM4 핀 속도 요구에 대한 보강 자료는 동반 노트 CPO에 관하여 (Part 1–2)와 Vera Rubin Decoded (Part 2)에서 가져왔다.
"shoreline"이 뜻하는 것
칩은 하나의 섬에 가깝다. 전력·메모리·네트워크 등 모든 외부 연결은 칩의 둘레를 건너야 한다.
그 둘레는 die 크기로 정해지고, 그 위에 배치할 수 있는 유효 I/O lane 수가 곧 shoreline (=beachfront)이다.
데이터 이동량이 커질수록 병목은 코어가 아니라 이 "칩의 둘레"가 된다.
하나의 문제를 두 관점으로 바라보면
한쪽은 이를 shoreline 문제라 부르고, 다른 쪽은 메모리 대역폭을 "I/O 밀도 문제"로 본다.
동일한 문제를 서로 다른 각도에서 설명하고 있을 뿐이다.
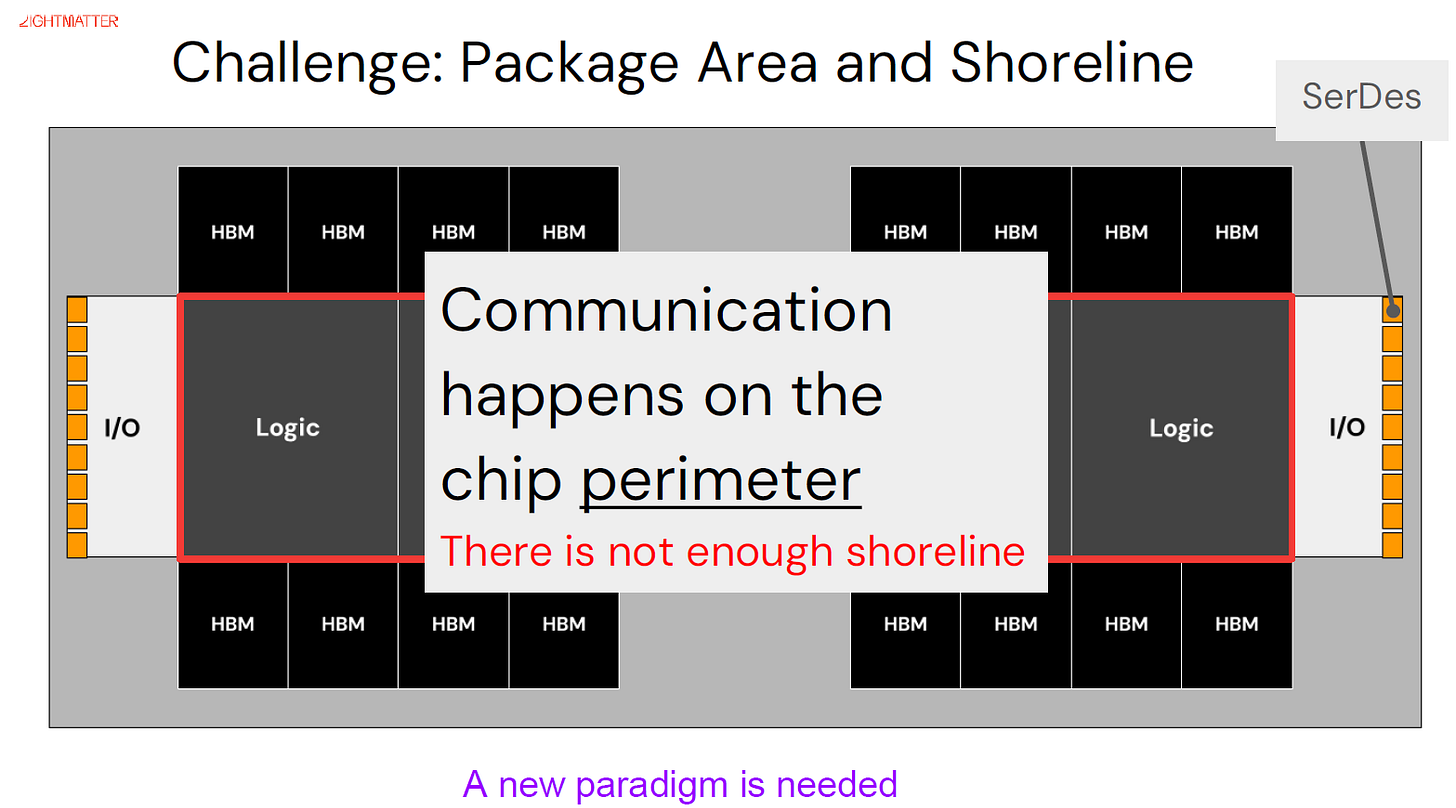
Logic die 주변을 HBM이 둘러싸고, SerDes I/O가 같은 가장자리를 놓고 경쟁한다. "새로운 패러다임이 필요하다."
SerDes & PHY
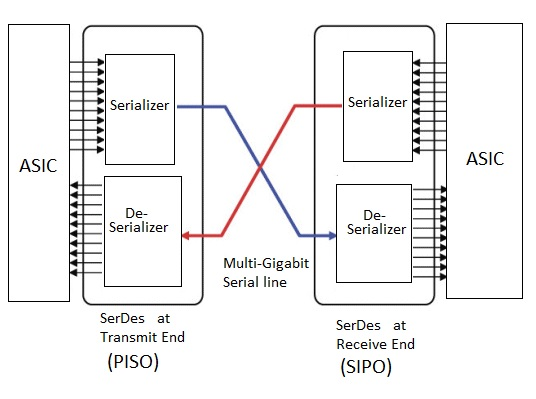
SerDes (Serializer/Deserializer)는 고속 직렬 비트 스트림을 구리선에 싣고, 반대편에서 다시 복원하는 회로다.
PHY: 채널과 물리적으로 맞닿는 더 넓은 아날로그 프런트엔드.
둘 다 die 가장자리에 자리 잡아 shoreline·전력·면적을 잡아먹는다.
세 가지 한계점
도달 거리. 구리선을 탄 고속 전기 신호는 ~2 m를 넘어서면 급격히 약해진다. NVLink는 지금 GPU당 ~7.2 Tb/s 속도로 네트워킹이 가능하나 (Rubin은 ~14.4 Tb/s 목표), 그건 단일 랙 내에서만 가능하다. Copper scale-up 도메인을 랙 외부로, 무한히 확장할 수는 없다.
비선형 전력. Broadcom에 따르면 최근 스위치 세대들에서 대역폭이 ~80배 오르는 동안 시스템 전력은 ~22배 올랐고, SerDes/광학 전력은 코어 로직보다 3배 이상 빠르게 늘었다. 비트가 더 필요해지는 바로 그 지점에서 비트당 전력 효율이 악화된다.
고속에서의 insertion loss.
단일 구리선 내 전기신호의 속도를 224 Gbit/s (그리고 "진짜" 448G)까지 밀어붙이면 신호 무결성의 벽에 부딪힌다 — bump, via, trace, 커넥터 하나하나가 신호를 깎아먹는다.
PAM4로 단일 lane에서 448G의 속도를 내려면 ~244 Gbaud가 필요한데, 전력과 손실 측면에서 감당하기 어렵다.
Nvidia가 채널당 448G에 도달하는 방식도 두 lane을 사용한 양방향 SerDes (한 채널을 224G Tx + 224G Rx가 나눠 쓰는 방식)를 통해서지, 단일 lane을 통한 단방향 448G는 아니다.
PAM4
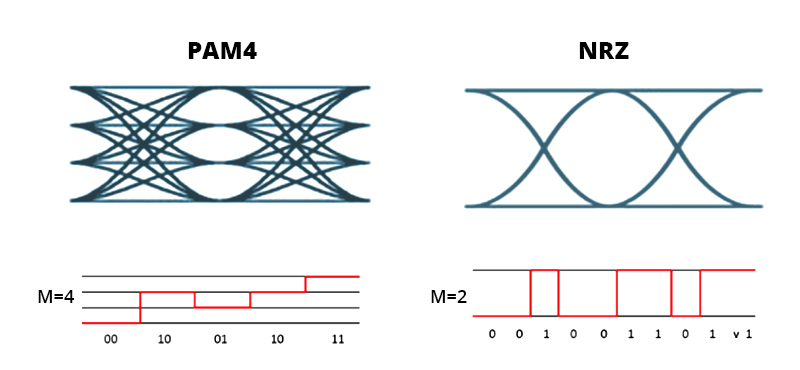
Pulse Amplitude Modulation, 4 레벨 — 자리당 1비트 대신 2비트 (전압 4단계)를 실어, 같은 baud rate에서 비트율을 두 배로 만든다.
더 밀어붙이면 (PAM6/PAM8) 비트는 얻지만 신호 마진과 전력을 잃는다.

212 Gbps에서는 신호가 커넥터에 닿기도 전에 ~20 dB를 잃는다 — 따라서 "특화된 ASIC과 CPO 인터커넥트의 개발을 요구한다."
광학은 정말 중요한 지표에서 이긴다: 네트워킹 거리가 증가해도 유지되는, 에너지당 대역폭 밀도.
구리를 통한 전기 링크는 도달 거리에 따라 신호 품질이 지수적으로 감소하지만, 광학 링크는 거의 변함없다.
업계 격언은 "되도록 가능한 곳엔 구리, 어쩔 수 없는 곳엔 광학"인데, 그 "어쩔 수 없는" 선이 점점 칩 쪽으로 다가오고 있다.
Pluggables → CPO
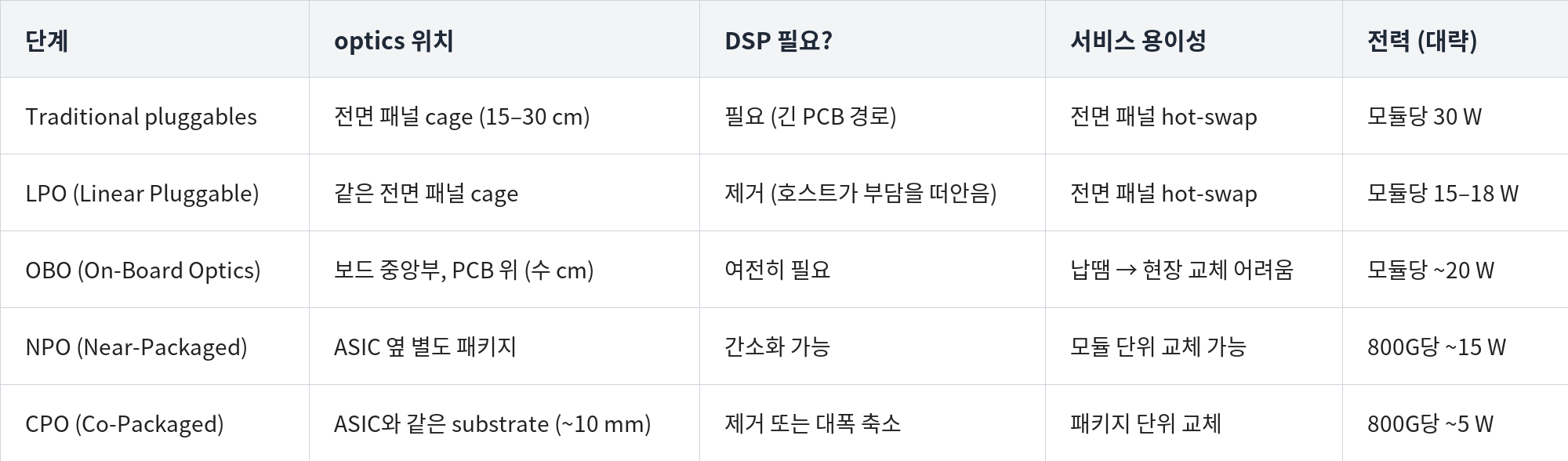
광학은 단계적으로 칩에 가까워진다. 각 단계는 광신호 변환 직전의 전기 구간을 줄이고, 그 결과 DSP (Digital Signal Processor)를 떼거나 SerDes 부담을 낮출 수 있다. 전력 수치는 800G 기준이다.
Traditional pluggables — 엔진이 전면 패널 cage (~15–30 cm)에 있다. 긴 PCB 경로 때문에 DSP가 필요하다. ~30 W; 전면 패널 hot-swap.
LPO (Linear Pluggable) — 같은 cage를 쓰되 DSP를 떼어내 그 부담을 호스트로 넘긴다. ~15–18 W. OBO와 CPO 사이의 한 단계가 아니라 pluggable의 한 갈래다.
OBO (On-Board Optics) — 엔진을 보드 중앙부에 납땜한다 (~수 cm). 여전히 DSP가 필요하고, 납땜형이라 현장 교체가 어렵다. ~20 W. "양쪽의 최악" (CPO의 복잡함 + pluggable의 한계)에 가깝다.
NPO (Near-Packaged Optics) — 광학 엔진이 패키지 근처, 흔히 소켓에 꽂는 별도 substrate에 놓인다. SerDes까지는 여전히 짧은 구리선 구간이 남지만, DSP는 간소화할 수 있다. ~15 W; 모듈 단위 교체 가능. 위험이 낮은 중간 단계다.
CPO (Co-Packaged Optics) — 엔진이 호스트 패키지 위 (~10 mm)에 올라간다. long-reach SerDes와 transceiver DSP를 없앤다. ~5 W; 패키지 단위 교체.
OE (Optical Engine) = PIC (Photonic IC — modulator·waveguide·detector) + EIC (Electronic IC — driver·TIA·제어 로직).
각 단계를 아키텍처 단면도로 보면 다음과 같다. 기준점에서 시작해, 단계마다 optics를 ASIC 쪽으로 당겨 온다:
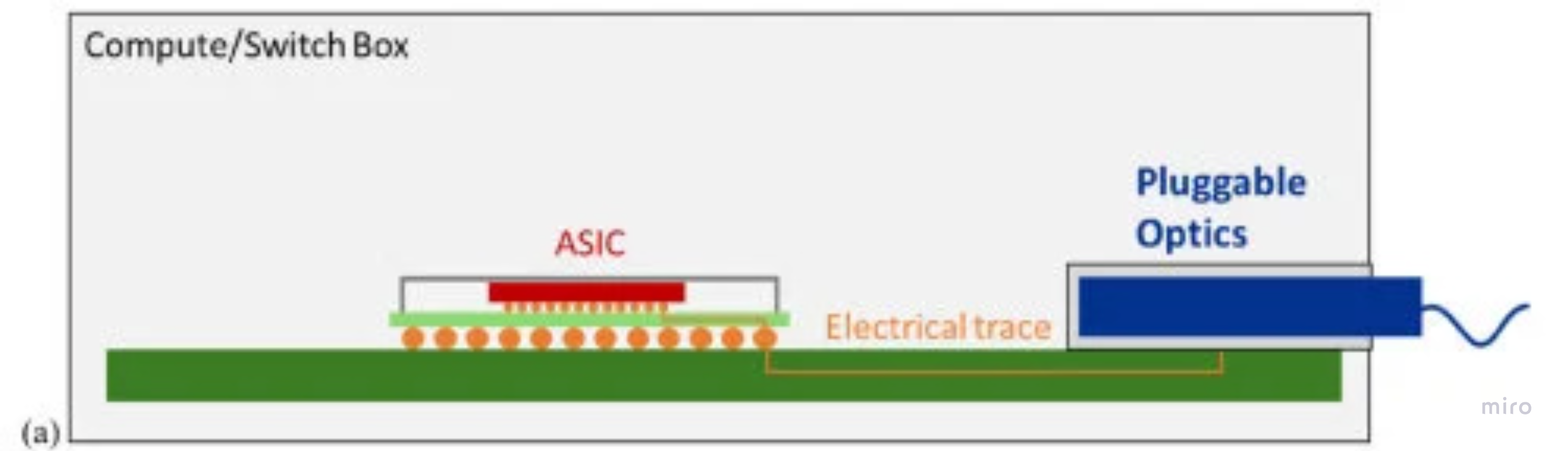
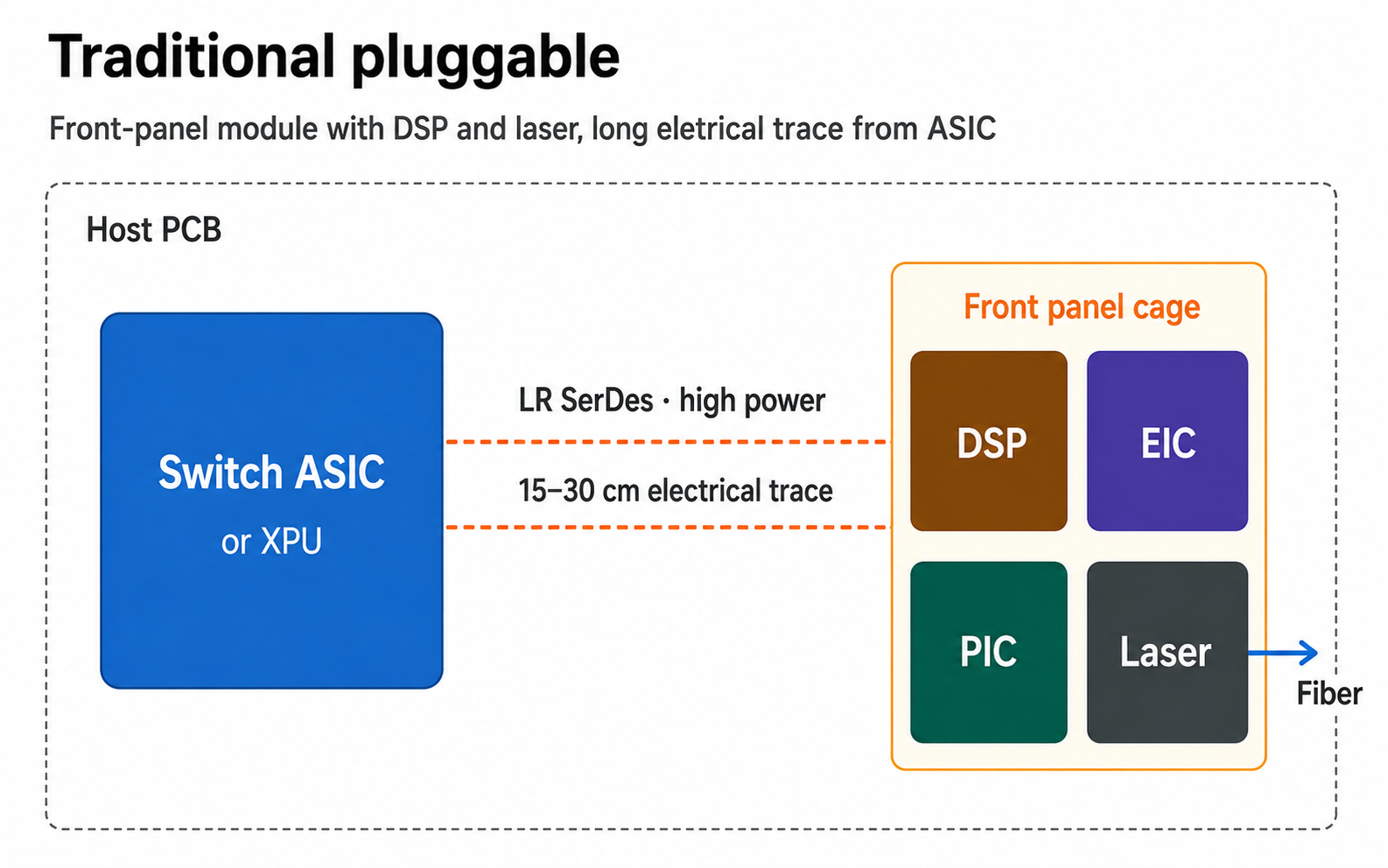
기준점 — traditional pluggables: 모듈이 전면 패널 cage에, ASIC에서 손실 PCB로 15–30 cm 떨어져 있다. 그 긴 전기 구간이 바로 DSP가 복원해야 할 대상이다.
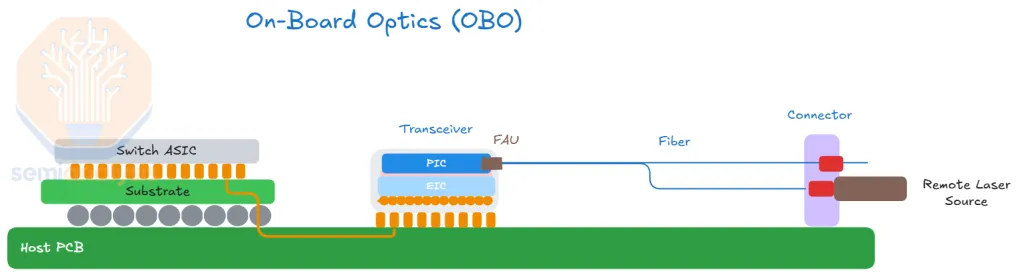
OBO: 모듈이 ASIC 근처 보드 중앙부로 옮겨 오지만, 수 cm의 PCB 구간은 남는다 — 그래서 DSP도 남는다. 광신호는 내부 fiber jumper를 타고 전면 패널에 닿는다.
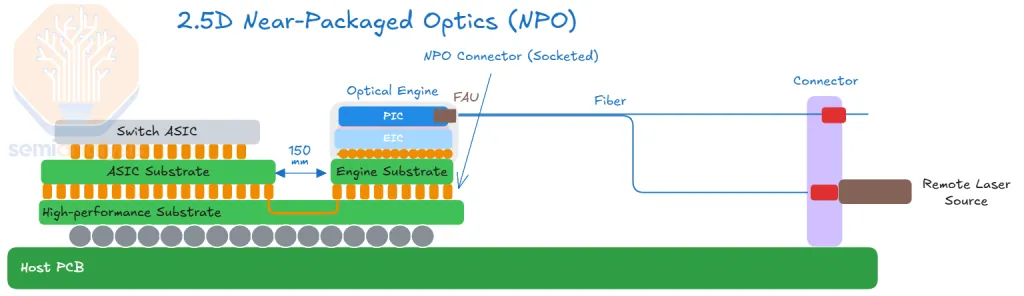
NPO: 광 엔진이 같은 PCB 위 별도의 교체 가능한 패키지로 ASIC 옆에 놓인다 — 전기 구간이 훨씬 짧고 DSP는 간소화할 수 있다.
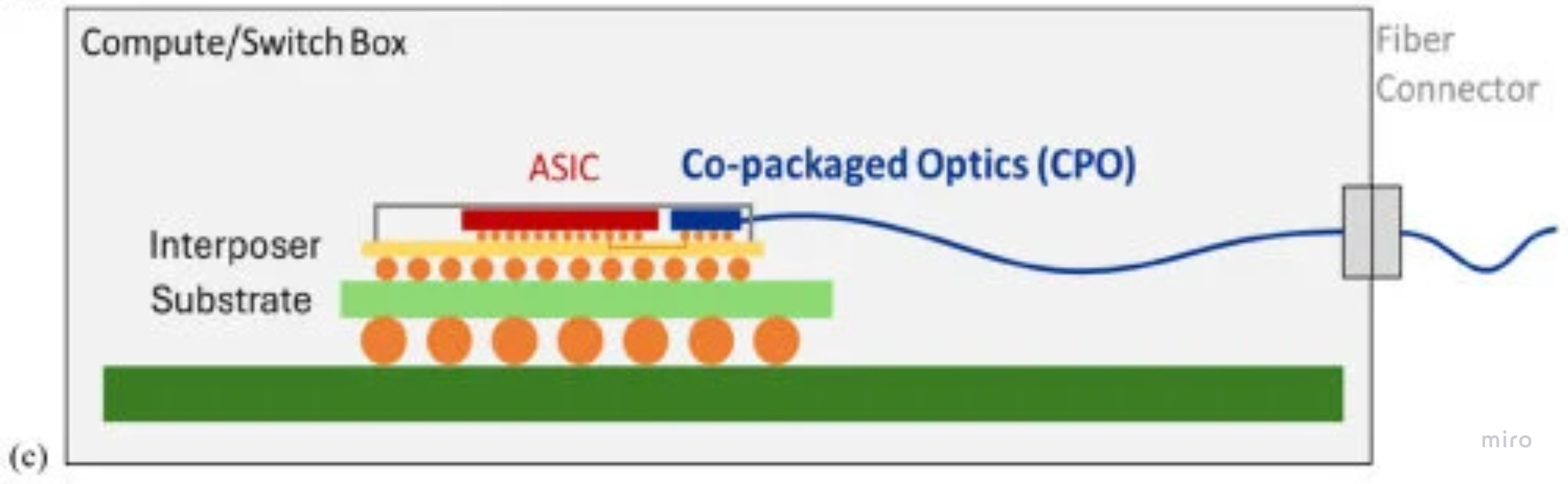
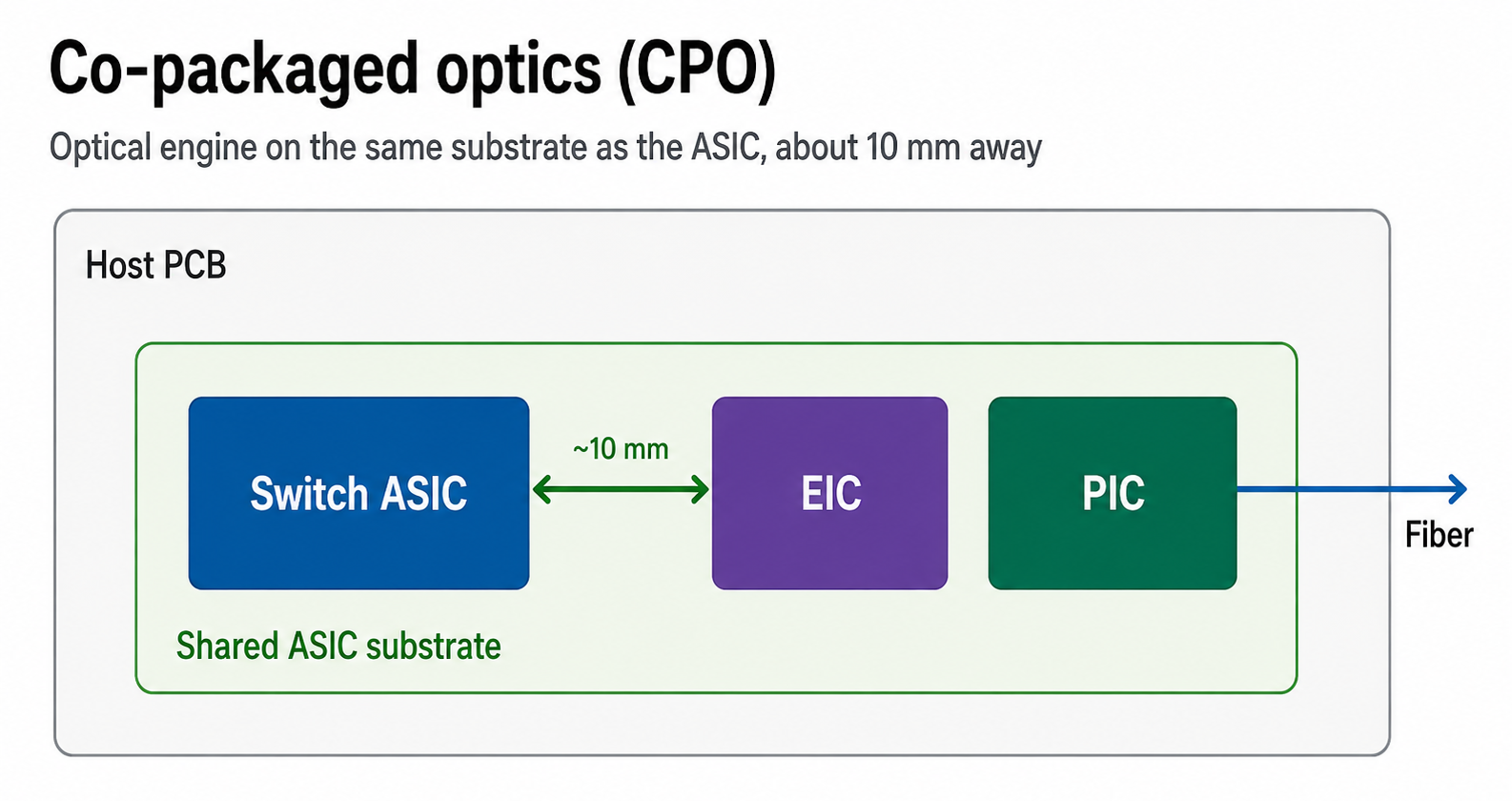
ASIC, EIC, PIC를 나란히 둔 모습 — 광 엔진을 호스트 substrate에 올려 전기 경로를 ~mm로 줄이고 DSP를 아예 없애는 건 CPO뿐이다.
DSP: 비용과 전력의 핵심 표적
Pluggable transceiver에서 DSP는 긴 구리선 구간을 지나며 열화된 전기 신호를 리타이머를 통해 복원한다. 너무 멀리 보내 손상된 신호를 되살리기 위한 회로다.
DSP는 800G 모듈 전력의 ~50% (30 W 중 ~20 W)이고 BoM의 20~30%다. 게다가 transceiver 자체가 클러스터 TCO의 ~10%를 차지할 수 있다. 그래서 DSP는 비용과 전력 양쪽에서 가장 큰 지렛대 중 하나다.
CPO를 통해 전기 신호의 이동 구간을 줄이면 DSP는 더 이상 필요 없다.
계산 예시:
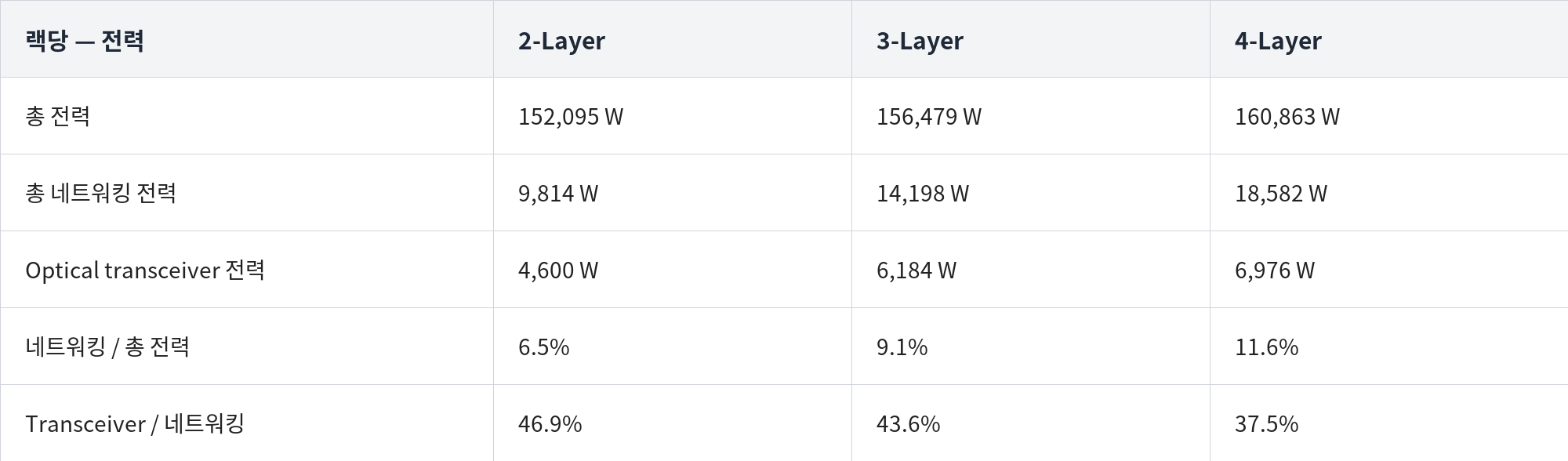
18k-GPU 규모의 GB300 클러스터를 2-layer InfiniBand fabric으로 묶으면 800G transceiver ~18,432개 + 1.6T transceiver ~27,648개가 필요하다.
DSP당 6–7 W (800G), 12–14 W (1.6T)를 소비한다고 잡으면, back-end 네트워크에만 DSP 전력 ~480 kW (랙당 ~1.8 kW)가 들어간다. 여기가 공략 지점이다.
DSP vs CPO — 링크 단위로는 크지만 클러스터 단위에서는 희석된다
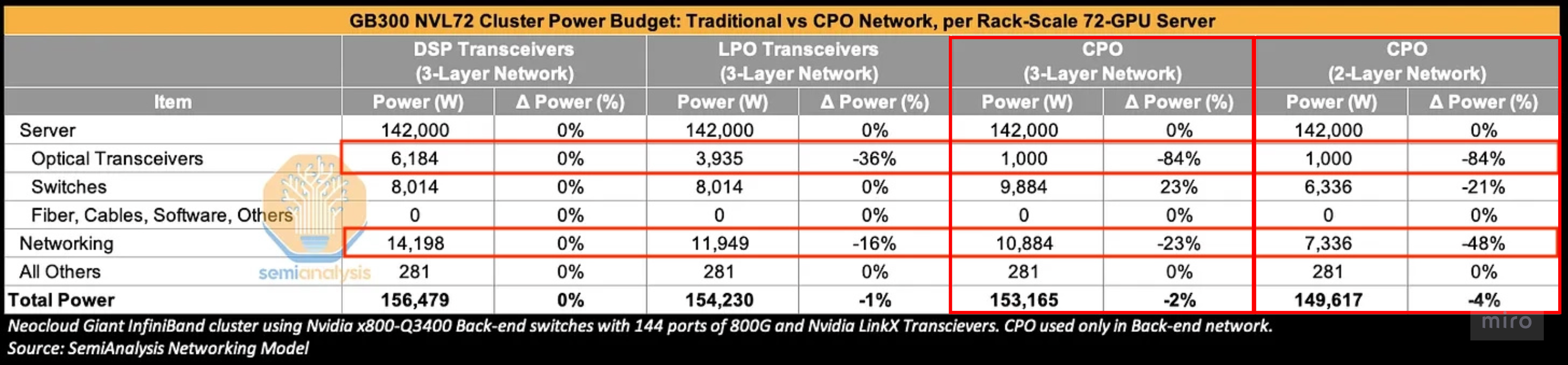
DSP transceiver를 CPO로 바꾸면: transceiver 전력 −84% 절감, 네트워킹 전력 −23% 절감이 가능하지만, 총 클러스터 전력으로는 ~2% 절감에 그친다. (3-Layer 네트워크 클러스터 기준)
개별 링크 단위 기준:
상당한 절감효과를 이룰 수 있다. DSP 기반 pluggable과 CPO 광 엔진 (OE) + 외부 레이저를 대역폭 800G로 정규화해 비교하면:
800G DR4 pluggable: ~16–17 W 소비에서 → CPO OE + 레이저: ~4–5 W 소비 = ~73% 감소.
800G 2×FR4 pluggable: ~15 W 소비에서 → OE + 레이저: 5.4 W 소비 = ~65% 감소. 모듈 종류도 다르고 별개의 연구인데도 같은 범위로 떨어진다는 점이 결과의 신뢰도를 높인다.
어떻게 이런 가파른 절감이 가능한지: DSP가 pluggable 전력의 대부분을 차지한다. CPO는 짧은 전기 구간 덕에 그 규모의 전력 소보가 불필요하고, 이 하나의 절감이 CPO의 대표 수치인 링크당 ~50–80% 전력 절감에 가장 크게 기여한다.
클러스터 단위 기준:
클러스터 규모에서는 희석된다. 3-layer GB300 NVL72 클러스터 전반에서 DSP transceiver를 CPO로 바꾸면 transceiver 전력은 ~84%, 네트워킹 전력은 ~23% 줄어든다.
하지만 네트워킹은 클러스터 전력의 ~9%에 불과해서, 총 클러스터 전력은 ~2%밖에 안 줄어든다 (2-layer 망에서도 ≤~4%).
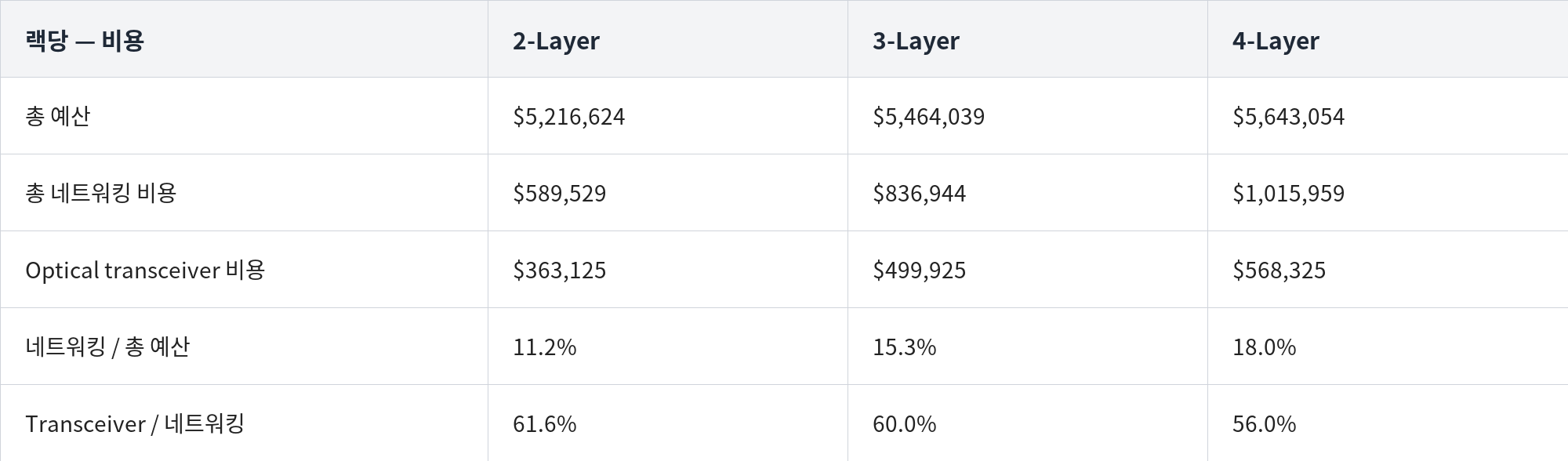
비용도 마찬가지다: 네트워킹 비용 −21%지만 총 클러스터 비용은 −3% (2-layer 망에서 최대 −46% / −7%).
따라서 scale-out 쪽은 전력 절감의 상한이 낮고, 전략적 견인력은 scale-up에 있다. 전력 2–4% / 비용 3–7% 절감만으로는 서비스 용이성·신뢰성·vendor lock-in에 대한 우려를 안고 뛰어들기 어렵다.
CPO가 "있으면 좋은" 게 아니라 반드시 필요한 곳은 scale-up이다 — copper/SerDes 스케일링이 물리적 벽에 부딪히는 영역이며, 광학의 영역이 scale-out에서 scale-up 순으로 확장되는 이유도 바로 이것이다.
SerDes를 곧바로 CPO로 갈아끼울 수는 없다. 광학은 integration ladder (통합의 사다리)를 오른다. 단계가 올라갈수록 die에 더 가까워지고 비트당 비용은 낮아지지만, 구현 난도는 높아진다:
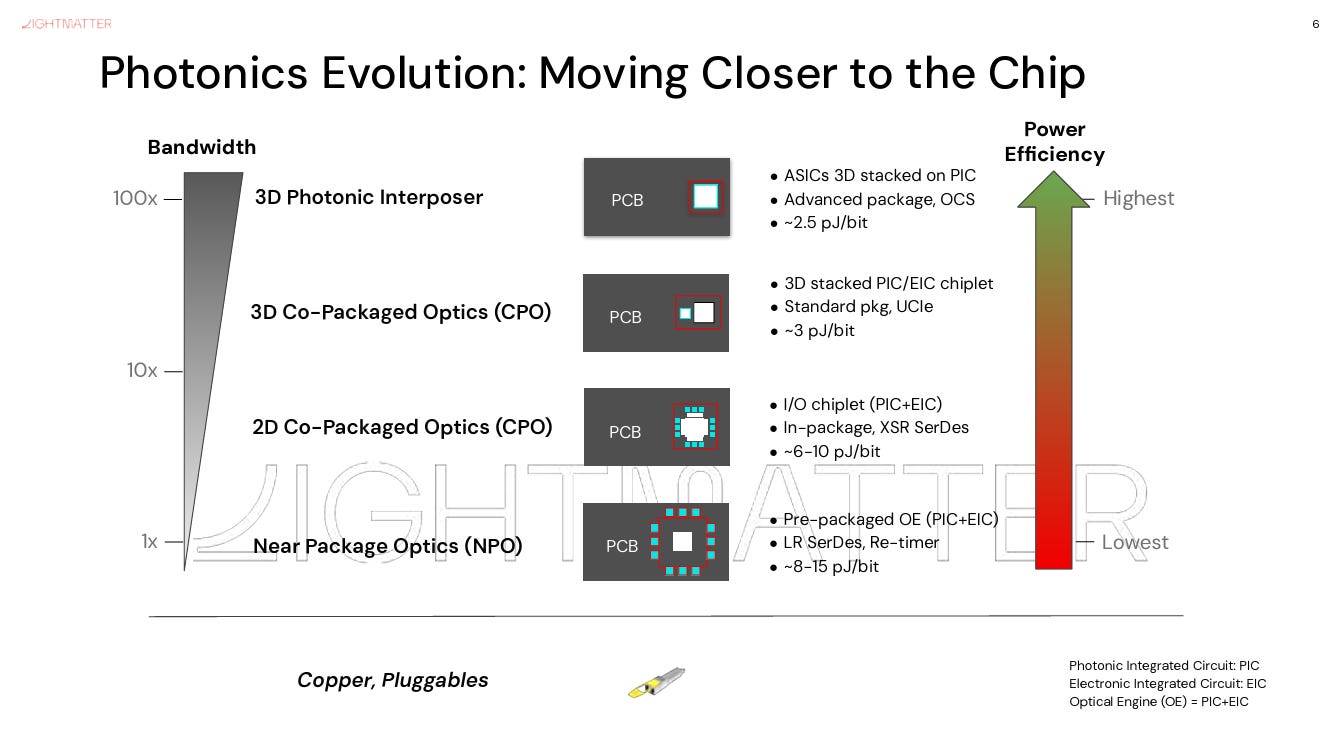
단계적 경로: copper/pluggables → NPO → 2D CPO → 3D CPO → 3D photonic interposer.
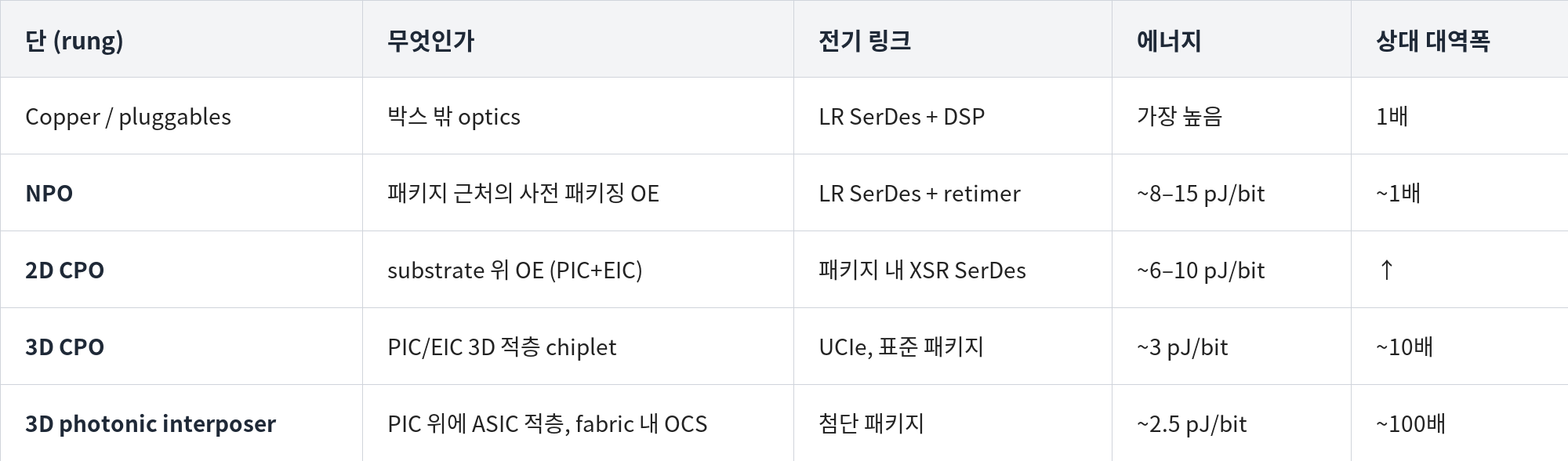
발목을 잡는 건 물리적 한계가 아니라 경제성과 운영적 한계다
공급망 미성숙.
신뢰성 / 수율.
서비스 용이성 — 납땜된 OE 하나가 고장 나면 스위치 전체를 못 쓰게 만들 수 있다.
고객이 비용 협상력을 잃을 수 있다는 우려 — transceiver 공급사 여러 곳을 압박하는 편이 소수의 스위치 ...

훌륭한 인사이트 감사합니다
읽어주셔서 감사합니다!




